

Claude Opus 4.8 is the kind of release that makes two tribes shout past each other. The benchmark crowd sees a serious engineering model, sharper at code, better at tool use, and less willing to bluff. The daily users see a brilliant assistant that sometimes answers “Good morning” like it’s defending a PhD thesis on greetings. Both are right. Claude Opus 4.8 is not a simple “better model.” It’s a model with a more expensive brain, a stronger conscience, and occasionally the social confidence of a nervous intern holding a clipboard.
Table of Contents
1. The Hype Vs. The User Reality
Anthropic positions Claude Opus 4.8 as its most capable general-access model, with gains across software engineering, agentic tool use, and knowledge work. The official system card says it beats Opus 4.7 across nearly all capability evaluations, while still sitting below the unreleased Mythos Preview tier. That distinction matters. This is not the new frontier model. It is the new workhorse for people who already push models into large, messy, tool-heavy jobs.
Claude Opus 4.8 Benchmarks
| Category / Benchmark | Specifics | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Agentic Coding | SWE-Bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| Agentic Terminal Coding | Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| Multidisciplinary Reasoning | Humanity’s Last Exam, No Tools | 49.8% | 46.9% | 41.4% | 44.4% |
| Multidisciplinary Reasoning | Humanity’s Last Exam, With Tools | 57.9% | 54.7% | 52.2% | 51.4% |
| Agentic Computer Use | OSWorld-Verified | 83.4% | 82.8% | 78.7% | 76.2% |
| Knowledge Work | GDPval-AA | 1890 | 1753 | 1769 | 1314 |
| Agentic Financial Analysis | Finance Agent v2 | 53.9% | 51.5% | 51.8% | 43.0% |
That table tells a pretty clear story. This model is not tuned mainly for charming chat. It’s tuned for staying alive inside difficult workflows. The gains show up when there are files, tools, tests, terminals, browsers, and long chains of dependent steps. For business users, that’s exactly where money is made or burned.
The backlash is also real. Many users wanted a warmer, faster, less fussy assistant. Some preferred Opus 4.6 because it felt more direct and less bureaucratic. The funny part is that the same behavior people dislike in casual chat is part of what makes the model safer in autonomous work. A model that refuses to pretend it fixed the build is annoying until the build matters.
A release like this is easy to misread because benchmarks reward patience and users reward responsiveness. A model can be objectively stronger and subjectively more irritating. Anyone who has watched a compiler emit one perfect binary after fifteen minutes of cryptic warnings knows the feeling. The right question is not whether the model is “good.” The right question is where its extra deliberation converts into fewer mistakes, and where it merely turns a simple conversation into a meeting that should have been an email.
2. What Is Actually New In Claude Opus 4.8?
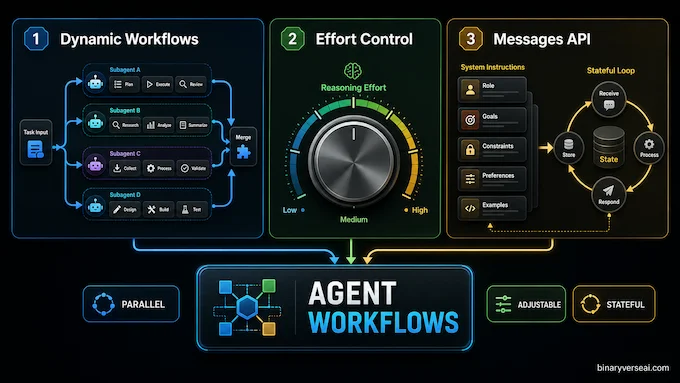
The release has three practical changes. First, Claude Code gets dynamic workflows. The model can plan a large job, spin up many parallel subagents, verify their outputs, and report back. Anthropic describes this as useful for codebase-scale migrations across hundreds of thousands of lines of code, with the test suite acting as the judge. That is the right mental model. This is less “pair programmer” and more “small engineering team with a very strange sleep schedule.”
Second, Claude effort control moves into the user interface. You can now choose how hard the model thinks before it answers. Higher effort means deeper reasoning and more token use. Lower effort means faster answers and slower rate-limit burn. This is a good control, but only if users understand it. Giving someone a turbo button is kind. Making it default to “please melt my quota” is less kind.
Third, the Messages API can now accept system entries inside the messages array. That sounds dry, because it is. It’s also important. Developers can update instructions mid-task without shoving control messages through the user channel or breaking prompt caching. For agents, this is the difference between a brittle puppet show and something closer to a stateful control loop.
3. Why Your Usage Limits Are Vanishing

The token complaints are not imaginary. Claude Opus 4.8 can feel hungry because it combines adaptive thinking with effort settings. At higher effort, the model spends more budget reasoning before it gives you the visible answer. You don’t see all of that work, but your quota does. Silent thinking still lands on the bill.
This is the trade. You can buy depth, or you can buy speed, but pretending they cost the same is how users end up asking three questions and watching a usage bar evaporate like a startup’s Series A.
Use low or normal effort for rewriting, quick debugging, SQL cleanup, small React fixes, summaries, and everyday research. Use high for nontrivial architecture work, messy bugs, migration planning, security reviews, and anything where the first wrong answer wastes an hour. Save max for jobs where real search matters inside the problem space: deep codebase debugging, hard mathematical reasoning, long agent runs, or tasks that resemble a miniature research project.
3.1 How To Use Claude Effort Control Without Going Broke
Prompt it like a senior engineer, not like a fortune teller. Say what depth you want.
- Use: “Give me the shortest correct fix. Don’t explore alternatives unless the first approach fails.”
- Use: “Spend effort on correctness, not explanation. Show only the final patch and a brief rationale.”
- Use: “Before coding, inspect the likely failure points. After that, stop planning and implement.”
The key is to put a governor on the model’s helpfulness. Unbounded helpfulness is just latency wearing a nice jacket. Claude effort control gives you a steering wheel. Use it, or the model will happily think itself into your monthly limit.
4. The Personality Shift: Honesty With A Clipboard
Anthropic highlights honesty as a major improvement. Early testers said the model is more likely to flag uncertainty and less likely to claim progress on thin evidence. Anthropic also says evaluations show it is about four times less likely than its predecessor to let flaws in its own code pass without comment. That is a meaningful shift for agents that write, run, inspect, and repair code.
It also explains the vibe shift. In chat, honesty can look like anxiety. The model checks itself, qualifies claims, and occasionally over-explains a refusal until the refusal needs its own table of contents. The system card even notes a tendency toward over-elaborate refusals. Great for safety analysis. Less great when you ask for a button label.
This is the alignment tax. Not a bad tax, necessarily. Just visible. Opus 4.6 often felt like a confident senior developer. Opus 4.8 can feel like that same developer after legal, security, and brand have all left comments in the Google Doc.
5. Opus 4.8 Vs Opus 4.6: Did Anthropic Downgrade The Model?
The Opus 4.8 vs Opus 4.6 debate is really a debate about taste, not raw capability. Many developers liked 4.6 because it had snap. It made decisions. It did not always surround each action with a reflective moat. If your work is mostly interactive, that matters. A model’s “feel” is not cosmetic. It changes how often you stay in flow.
Opus 4.8 is stronger when the task becomes long-horizon. It holds more moving parts, handles tools more cleanly, and is less prone to pretending success. That makes it better for autonomous coding sessions and worse for people who want fast, opinionated back-and-forth.
So, was it a downgrade? For casual writing, brainstorming, and quick edits, some users will experience it that way. For agentic work, no. It’s a stricter, more deliberate machine. The mistake is expecting one model personality to be ideal for both five-second questions and five-hour workflows.
6. The Rise Of Agentic AI Models
Agentic AI models are not just chatbots with better manners. They plan, call tools, inspect outputs, recover from errors, and keep going when the task stops fitting neatly inside one prompt. This is where Claude Opus 4.8 looks strongest.
OSWorld-Verified is a useful signal here because it tests computer use in a live Ubuntu environment. The model has to click, type, manage files, browse, edit documents, and deal with the small humiliations of real interfaces. A high score there means more than trivia knowledge. It means the model can operate in a world that pushes back.
That matters because the next productivity jump is not “write me a paragraph.” We already got that demo. The next jump is “take this repo, migrate the framework, update the tests, resolve the weird dependency conflict, and tell me where you are uncertain.” Agentic AI models will be judged by how well they survive contact with entropy. Opus 4.8 survives it better than most.
7. Claude Opus 4.8 Vs GPT-5.5
The Claude Opus 4.8 vs GPT-5.5 comparison is refreshingly uneven. Opus wins SWE-Bench Pro, Humanity’s Last Exam in both tool and no-tool setups, OSWorld-Verified, GDPval-AA, and Finance Agent v2. GPT-5.5 wins Terminal-Bench 2.1 in the table, which suggests stronger performance in pure command-line workflows.
For developers, the split is practical. If your work is terminal-heavy, script-heavy, and full of CLI puzzles, GPT-5.5 deserves a hard look. If your work is broader engineering, especially across a large codebase with documents, tools, and business context, Opus 4.8 looks more attractive.
For enterprises, GDPval-AA may matter more than the coding trophies. It measures professional work products across industries, not just algorithmic cleverness. Opus 4.8 leading GPT-5.5 there suggests better performance on the messy white-collar tasks where the input is ambiguous, the output has format constraints, and nobody gets applause for merely sounding smart.
8. Claude Opus 4.8 Pricing: Is Fast Mode Actually Cheaper?
Claude Opus 4.8 pricing looks boring at first, then interesting once you include speed. Standard API pricing stays at $5 per million input tokens and $25 per million output tokens. Fast mode costs $10 per million input tokens and $50 per million output tokens, giving up to 2.5 times faster output at 2 times the standard price. Anthropic’s pricing docs also list batch processing at a 50% discount for asynchronous work. (Anthropic)
Claude Opus 4.8 Pricing
| Model / Mode | Input | Output | 5-Min Cache Write | Cache Read | Notes |
|---|---|---|---|---|---|
| Opus 4.8 Standard | $5 / MTok | $25 / MTok | $6.25 / MTok | $0.50 / MTok | Default high-intelligence agent and coding model |
| Opus 4.8 Fast Mode | $10 / MTok | $50 / MTok | Applies With Modifier | Applies With Modifier | Up to 2.5x faster output, not available with Batch API |
| Opus 4.8 Batch | $2.50 / MTok | $12.50 / MTok | Standard Batch Rules | Standard Batch Rules | 50% discount for asynchronous processing |
| Opus 4.7 Standard | $5 / MTok | $25 / MTok | $6.25 / MTok | $0.50 / MTok | Legacy Opus option |
| Opus 4.6 Standard | $5 / MTok | $25 / MTok | $6.25 / MTok | $0.50 / MTok | Still attractive for users who prefer its feel |
| Sonnet 4.6 Standard | $3 / MTok | $15 / MTok | $3.75 / MTok | $0.30 / MTok | Better default for cost-sensitive everyday work |
| Haiku 4.5 Standard | $1 / MTok | $5 / MTok | $1.25 / MTok | $0.10 / MTok | Best for cheap, high-volume lightweight tasks |
Fast mode is not “cheaper” per token. It is cheaper per unit of wall-clock patience. That distinction matters for agents. If you run customer-facing workflows, developer tools, or live copilots, latency has a price. If you run overnight batch jobs, use batch and pocket the savings.
The hidden pricing issue is effort. A $5 input price does not help if your prompt triggers a long internal reasoning marathon. Cost is price multiplied by tokens multiplied by the model’s desire to be thorough. That last term is where people get surprised.
9. Who Should Upgrade?
Use Claude Opus 4.8 if you run serious coding agents, codebase migrations, long tool chains, financial document workflows, legal or office automation, and research tasks where false confidence is expensive. It is built for work that has state, consequences, and enough complexity to punish shallow answers.
Stick with Sonnet for daily drafting, summarization, ordinary coding help, and workflows where cost matters more than peak reasoning. Sonnet remains the sensible default for most people most days. It’s the model you hire for reliable office work. Opus is the specialist you call when the basement is flooding and the pipes are undocumented.
Keep Opus 4.6 around if you value its voice and directness. There is no shame in preferring the older feel. Models are tools, and tool preference is allowed. The best screwdriver is not always the newest screwdriver. Sometimes it’s the one that doesn’t lecture you about torque.
10. Final Verdict: A Brilliant Machine, Not A Friendly Default
Claude Opus 4.8 is a real upgrade, but not a universally pleasant one. It is better at staying honest, better at agentic work, better at broad professional tasks, and more suited to autonomous engineering than its predecessor. It is also more verbose, more cautious, and more capable of burning through limits when users leave effort settings unchecked.
That makes the verdict simple. For builders of agents, serious coders, and enterprise teams, upgrade and learn the controls. For casual users, writers, and people who want quick clean answers, don’t treat it as the default just because it has the biggest name. Use the smaller model until the work justifies the larger mind.
The best way to test it is not with a cute prompt. Give it one ugly task you have been avoiding: a failing migration, a confusing repo, a spreadsheet full of business logic, a document workflow with too many edge cases. Set the effort deliberately. Measure the result, the time, and the token burn.
If it saves you a day, keep it. If it gives you a dissertation on “Good morning,” turn the effort down and let the machine breathe.
Is Opus 4.6 Actually Better Than Claude Opus 4.8?
Opus 4.6 is not technically better overall, but many users still prefer it for creative writing, smoother conversation, long-context drafting, and lower token use. Claude Opus 4.8 is stronger for autonomous, long-horizon coding tasks, agentic AI workflows, tool use, and complex benchmarked work. The better choice depends on the job: Opus 4.6 feels lighter and more direct, while Claude Opus 4.8 is built for harder, more structured execution.
Why Does Claude Opus 4.8 Use So Many Tokens?
Claude Opus 4.8 can use many tokens because of Effort Control and Adaptive Thinking. When users select Extra or Max effort, the model spends more time reasoning before answering. That hidden reasoning improves difficult outputs, but it also burns through usage limits faster. On claude.ai, this can make the 5-hour limit disappear quickly, especially during coding, debugging, research, or long agentic workflows.
How Much Does Claude Opus 4.8 Cost?
Claude Opus 4.8 costs $5 per million input tokens and $25 per million output tokens through the API. Fast Mode costs $10 per million input tokens and $50 per million output tokens, but runs up to 2.5x faster. Standard mode is cheaper per token, while Fast Mode is better for high-throughput or latency-sensitive workloads where speed matters more than raw token price.
What Are Agentic AI Models, And How Does Opus 4.8 Fit In?
Agentic AI models can plan tasks, use tools, navigate desktops, execute code, inspect results, and solve multi-step problems with less human supervision. Claude Opus 4.8 fits this category because it performs strongly on agentic coding and computer-use benchmarks, including an 83.4% OSWorld-Verified score. Its dynamic workflows in Claude Code also let it coordinate parallel subagents for large codebase tasks.
How Does Claude Opus 4.8 Compare To GPT-5.5?
Claude Opus 4.8 beats GPT-5.5 in several agentic and professional benchmarks, including SWE-bench Pro for coding and GDPval-AA for complex knowledge work. GPT-5.5 remains stronger in Terminal-Bench 2.1, which measures pure terminal command workflows. In simple terms, Claude Opus 4.8 looks stronger for broad autonomous engineering and business tasks, while GPT-5.5 still has an edge in command-line-heavy work.