

Qwen 3.7 Max is the kind of model launch that makes engineers put down their coffee and squint. Not because Alibaba has discovered a magic new species of intelligence, but because the claim is practical and weirdly concrete: a model that can keep working for 35 hours, call tools more than a thousand times, and still not wander off into a swamp of confident nonsense.
That matters. The next frontier isn’t another chatbot that writes a tidy sonnet about Kubernetes. It’s an agent that can stay coherent through a long, boring, failure-heavy job. Compilers break. Tests fail. Context grows stale. The machine must keep going anyway.
This review is about that version of the story. The impressive part. The uncomfortable part. The developer economics. And the answer to the question everyone is really asking: does this thing actually threaten the Western frontier, or is this another benchmark confetti cannon?
Table of Contents
1. Qwen 3.7 Max Benchmarks: The Useful Snapshot
Before the philosophy, here are the numbers that matter. Alibaba’s official launch data puts Qwen3.7-Max near the top of its comparison set across coding agents, general agents, reasoning, multilingual tasks, and long-context work. Independent listings from Artificial Analysis and OpenRouter add a colder read: excellent, often elite, but not a clean knockout punch against the newest frontier models. Alibaba’s own post positions the model as a proprietary agent foundation with coding, office automation, long-horizon execution, and cross-scaffold generalization as core design goals.
Qwen 3.7 Max Benchmarks Comparison
| Benchmark | Opus-4.6 Max | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max | Qwen3.6-Plus | Qwen3.7-Max |
|---|---|---|---|---|---|---|
| Coding Agent | ||||||
| Terminal Bench 2.0-Terminus | 65.4 | 66.7 | 63.5 | 67.9 | 61.6 | 69.7 |
| SWE-Verified | 80.8 | 80.2 | — | 80.6 | 78.8 | 80.4 |
| SWE-Pro | 57.3 | 59.5 | 58.8 | 59.0 | 56.6 | 60.6 |
| SWE-Multilingual | 77.5 | 76.7 | — | 76.2 | 73.8 | 78.3 |
| NL2repo | 47.6 | 42.8 | 41.0 | 35.5 | 34.4 | 47.2 |
| SciCode | 51.9 | 52.2 | 45.1 | — | 41.4 | 53.5 |
| QwenWebDev | 1617 | — | 1564 | 1570 | 1500 | 1568 |
| QwenSVG | 1541 | 1325 | 1605 | 1506 | 1432 | 1608 |
| General Agent | ||||||
| Qwenclaw | 65.5 | 54.7 | 58.7 | 59.2 | 57.2 | 64.3 |
| CoWorkBench | 68.2 | 58.2 | 66.0 | 66.3 | 64.5 | 67.2 |
| ClawEval | 70.4 | 61.5 | 62.7 | 58.4 | 57.1 | 65.2 |
| Skillsbench | — | 56.2 | 53.1 | 52.3 | 45.7 | 59.2 |
| BFCL-V4 | 76.7 | 71.3 | 70.9 | 70.6 | 68.9 | 75.0 |
| MCP-Mark | 56.7 | 55.9 | 57.5 | 57.1 | 48.2 | 60.8 |
| MCP-Atlas | 75.8 | 66.6 | 71.8 | 73.6 | 74.1 | 76.4 |
| Vitabench | — | 39.1 | 45.1 | 51.9 | 42.8 | 47.9 |
| SpreadSheetBench-v1 | 89.3 | 84.5 | 85.2 | 84.9 | 80.2 | 87.0 |
| Kernel Bench L3 | 2.63/98% | 1.41/80% | 2.00/78% | 1.07/54% | 1.03/48% | 1.98/96% |
| HLE w/ tools | 53.0 | 54.0 | 52.3 | 48.2 | 50.2 | 53.5 |
| QwenWorldBench | 56.1 | 50.9 | 50.2 | 52.3 | 47.6 | 57.3 |
| STEM & Reasoning | ||||||
| GPQA Diamond | 91.3 | 90.5 | 86.2 | 90.1 | 90.4 | 92.4 |
| HLE | 40.0 | 36.4 | 34.7 | 37.7 | 28.8 | 41.4 |
| LiveCodeBench | 88.8 | 89.6 | — | 93.5 | 87.1 | 91.6 |
| HMMT 2026 Feb | 96.2 | 92.7 | 89.4 | 95.2 | 87.8 | 97.1 |
| IMOAnswerBench | 75.3 | 86.0 | 83.8 | 89.8 | 83.8 | 90.0 |
| CritPT | 12.6 | 8.0 | 4.6 | 12.9 | 2.9 | 11.4 |
| Apex | 34.5 | 24.0 | 11.5 | 38.3 | 8.8 | 44.5 |
| General Capability | ||||||
| MMLU-Pro | 89.7 | 87.1 | 86.3 | 87.5 | 88.5 | 89.6 |
| MMLU-Redux | 95.2 | 95.3 | 94.3 | 94.8 | 94.5 | 95.0 |
| SuperGPQA | 72.5 | 71.3 | 68.0 | 69.9 | 71.6 | 73.6 |
| IFEval | 91.9 | 94.5 | 94.5 | 91.9 | 94.3 | 94.3 |
| IFBench | 62.5 | 76.0 | 76.0 | 77.0 | 74.2 | 79.1 |
| MRCR-v2 128k | 84.0 | 63.1 | 62.0 | 74.4 | 85.9 | 90.4 |
| Multilingualism | ||||||
| WMT24++ | 82.7 | 81.6 | 81.8 | 82.2 | 84.3 | 85.8 |
| MAXIFE | 81.3 | 87.7 | 87.7 | 88.9 | 88.2 | 89.2 |
| MMMLU | 90.6 | 87.5 | 87.2 | 87.9 | 89.5 | 90.3 |
| MMLU-ProX | 86.1 | 83.7 | 83.9 | 83.9 | 84.7 | 87.0 |
| NOVA-63 | 59.1 | 56.7 | 54.6 | 52.8 | 57.9 | 59.0 |
| INCLUDE | 87.4 | 84.2 | 84.3 | 86.1 | 85.1 | 86.2 |
| Global PIQA | 91.2 | 89.2 | 89.5 | 90.5 | 89.8 | 91.4 |
| PolyMATH | 80.2 | 82.7 | 67.6 | 72.0 | 77.4 | 86.5 |
Higher scores generally indicate stronger performance. The Qwen3.7-Max column is highlighted for quick comparison.
The headline score is not one benchmark. It is the shape of the model. Qwen 3.7 Max is not only a “smart answer” model. It is trying to be a durable worker.
2. The 35-Hour Agent Run Is The Real Story
The most interesting part of the launch is not a chart. It is the Extend Attention kernel experiment.
Alibaba gave the model a production-grade kernel optimization task inside SGLang. The job was not a toy LeetCode exercise with a cute test case. It involved optimizing a variable-length multi-head attention operator for a hardware platform the model had not seen during training, with no prior profiling data, no hardware documentation, and no example kernels for that architecture.
Over roughly 35 hours, Qwen 3.7 Max performed 432 kernel evaluations across 1,158 tool calls. It wrote code, compiled it, profiled it, hit failures, fixed correctness bugs, redesigned pieces of the kernel, and kept improving. Alibaba reported a 10.0x geometric mean speedup over the Triton reference implementation. A separate report summarizing the claim also highlighted the same 35-hour run, 1,158 tool calls, 432 evaluations, and 10x speedup.
That is not “the model wrote a Python script.” That is closer to watching a junior systems engineer go feral over a weekend, except the engineer does not need sleep and cannot be bribed with biryani.
The deeper point is endurance. Many models are impressive for the first 20 minutes of an agent session. Then the context gets messy. The plan gets stale. The tool loop becomes ritualistic. A model starts editing around the real problem, or worse, declares victory because the logs look emotionally supportive.
Long-horizon work breaks agents in a special way. It punishes shallow planning, weak memory, poor error recovery, and reward hacking. On that axis, this launch is genuinely interesting.
3. The Missing Benchmark Controversy Is Fair
Now for the awkward part.
If users search for Qwen 3.7 Max vs GPT-5.5 or Qwen 3.7 Max vs Claude Opus 4.7, Alibaba’s official table will not fully satisfy them. The launch comparisons lean heavily on models like Opus-4.6 Max, K2.6 Thinking, GLM-5.1 Thinking, DeepSeek V4 Pro Max, and Qwen3.6-Plus. That is useful for measuring progress inside the ecosystem, but it leaves the most obvious question hanging in the air.
Engineers notice missing baselines the way cats notice open tuna.
The criticism is not that Alibaba’s numbers are fake. The criticism is that the table tells a partial story. If a vendor claims an “agent frontier,” readers expect the chart to include the models sitting at the frontier right now, not only the models that make the new release look cleanest.
This does not make Qwen 3.7 Max weak. It makes the launch marketing incomplete. There is a difference.
A more honest framing would be: this appears to be the strongest Qwen agent model yet, likely the strongest Chinese proprietary agent model available today, and a serious production option for developers who care about long context, tool use, and price. That is already a big claim. It does not need decorative smoke.
4. Artificial Analysis Intelligence Index Gives The Colder Read
Independent benchmarks are useful because they ruin everyone’s favorite press release.
Artificial Analysis lists Qwen3.7 Max with a 56.6 Intelligence Index, a 50.1 Coding Index, and a 66.6 Agentic Index. OpenRouter’s model page mirrors the same independent benchmark framing and shows Qwen3.7-Max as a 1M-context, text-in and text-out model with strong coding and agentic positioning.
That puts the model in rare air. The important phrase is rare air, not undisputed king.
For Qwen 3.7 Max benchmarks, the independent picture looks like this: great agentic score, strong coding score, excellent price-performance profile, and credible long-context strength. It is not merely “good for a Chinese model,” which is a lazy qualifier. It is good, full stop.
Still, the model’s public comparison problem remains. Users comparing Qwen 3.7 Max vs GPT-5.5 or Qwen 3.7 Max vs Claude Opus 4.7 should wait for clean, same-harness evaluations before declaring a winner. Benchmarks are already noisy. Cross-vendor benchmark theater makes them noisier.
The practical takeaway is simple: test it on your workload. Not a vibe test. Not one prompt. Give it your ugly repo, your flaky integration tests, your thousand-line migration, your office workflow with three broken spreadsheets and one suspicious PDF. That is where agent models reveal their actual personality.
5. Qwen 3.7 Max Pricing Makes Long Runs Less Absurd
Agent economics are brutal. A chatbot answer costs cents. A serious agent session can chew through context, tool traces, hidden reasoning, retries, and repeated repository reads like a goat in a paper factory.
That is why Qwen 3.7 Max pricing matters.
OpenRouter lists the model at $2.50 per million input tokens and $7.50 per million output tokens. It also lists a 1M token context window, max output around 65.5K tokens, and prompt caching with cache reads priced far lower than fresh input. The provider page shows Alibaba Cloud International as the available provider, with the same base price and explicit cache pricing.
Qwen 3.7 Max Pricing And API Benchmarks
| Cost Or Capability | Listed Value | Why Developers Care |
|---|---|---|
| Input Price | $2.50 per 1M tokens | Competitive for large agent prompts |
| Output Price | $7.50 per 1M tokens | Manageable for verbose tool-heavy runs |
| Context Window | 1M tokens | Useful for repos, logs, docs, and history |
| Max Output | About 65.5K tokens | Large enough for complex patches and reports |
| Cache Read | $0.25 per 1M tokens | Makes repeated context far cheaper |
| Best Fit | Long agent sessions | Especially coding, office, and MCP workflows |
Pricing and capability summary for developers evaluating Qwen 3.7 Max for long-running agent workloads.
The cache read price is the quiet killer feature. Long agents often reuse the same repository map, API docs, prior plan, and tool trace. If those tokens can be cached cheaply, the economics change from “this is a demo” to “this might survive procurement.”
This is where the model starts looking less like a lab trophy and more like infrastructure. For a broader look at how these costs stack up, the LLM pricing comparison guide covers the full landscape.
6. Is Qwen 3.7 Max Open Source? No, And That Matters
The short answer: Qwen 3.7 Max open source is not a thing right now. The Max model is a closed, proprietary API model.
That will disappoint the LocalLLaMA crowd, and honestly, they are right to care. The Qwen family earned a lot of developer goodwill through strong open-weight releases. People want to run models locally, fine-tune them, inspect them, quantize them, break them, repair them, and do mildly irresponsible things on a spare GPU at 2 a.m.
This release is not that.
A reasonable way to read Alibaba’s strategy is tiered: keep the Max model closed as the commercial flagship, then release smaller or specialized open-weight variants later. That pattern is now common across model labs. The frontier model becomes the product. The open models become ecosystem gravity.
That is not evil. It is also not the open-source dream. Both can be true.
For enterprises, closed API access may be fine. For researchers, privacy-sensitive teams, and hobbyists, it limits the fun. More importantly, it limits independent inspection. Agent models that run for hours and take real actions need trust, not just performance.
7. Cross-Scaffold Generalization Is The Underrated Technical Claim
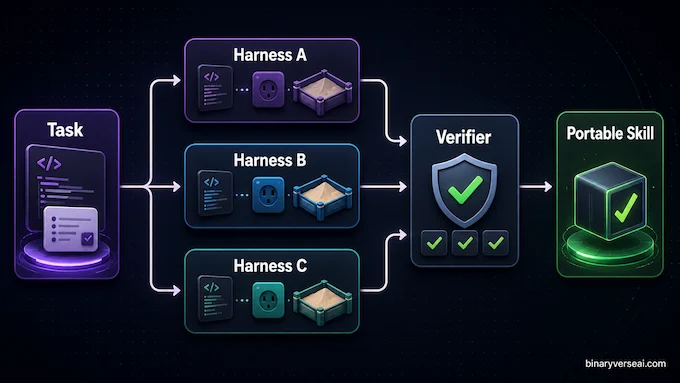
One phrase in Alibaba’s launch deserves more attention: cross-scaffold generalization.
The idea is simple. A weak agent model learns the quirks of a particular harness. It becomes good at one tool layout, one verifier style, one prompt wrapper, one sandbox. Then you move it into a different framework and the genius evaporates.
Alibaba says its rollout infrastructure separates task, harness, and verifier so they can be recombined during training. The model sees similar tasks through different wrappers and feedback systems. That should force it to learn the task, not the costume.
This matters if you build real software. Your agent stack may include Claude Code today, OpenClaw tomorrow, custom MCP tools next month, and a cursed internal deployment harness that nobody wants to document. A model that only shines in its native demo garden is expensive decoration.
Qwen 3.7 Max is pitched as portable across Claude Code, OpenClaw, Qwen Code, and custom frameworks. If that holds up in production, it is a serious advantage.
8. Claude Code Qwen 3.7 Setup Is Surprisingly Simple
The phrase Claude Code Qwen 3.7 sounds like a hack, but the integration path is straightforward because Alibaba supports an Anthropic-compatible API endpoint for Model Studio. Alibaba’s Claude Code documentation says Claude Code can work with Qwen models through Model Studio’s Anthropic-compatible interface, though regional details and key type matter.
A minimal setup looks like this:
npm install -g @anthropic-ai/claude-code
export ANTHROPIC_MODEL="qwen3.7-max"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.7-max"
export ANTHROPIC_BASE_URL="https://dashscope-intl.aliyuncs.com/apps/anthropic"
export ANTHROPIC_AUTH_TOKEN="<your_api_key>"
claude
For OpenAI-compatible clients, Model Studio also exposes compatible-mode endpoints. The practical effect is pleasant: in many tools, the model swap is mostly environment variables and base URLs.
That does not mean every feature maps perfectly. Tool calling, streaming behavior, reasoning preservation, rate limits, and regional availability can still surprise you. Test the boring parts first. Auth. Retries. Long output. Tool errors. JSON mode. Then hand it your repo. If you want a deeper look at the Claude agent SDK and how context engineering works at scale, that guide covers the underlying mechanics well.
9. The Office Agent Angle Is Less Flashy, More Useful
Coding gets the applause because developers write the posts. Office automation may be where a lot of the money is hiding.
Alibaba shows Qwen3.7-Max as a productivity agent that can read document requirements, reformat messy files, call office tools, generate reports, work with spreadsheets, and coordinate through MCP-style integrations. The official benchmark table includes SpreadSheetBench-v1 at 87.0, which is a useful signal because spreadsheets are where business logic goes to become immortal.
The “coworker” framing is overused, but not totally wrong. A good office agent is not a magical executive assistant. It is closer to a reliable analyst who can follow a 14-step process, check its work, and not panic when the input file has three fonts and a table copied from 2011.
For many companies, that is enough. Nobody needs AGI to fix invoice formatting, summarize policy changes, reconcile CSVs, and produce a clean weekly report. They need a model that can keep state, use tools, and ask fewer stupid questions. For real-world patterns along these lines, the ChatGPT agent use cases guide covers the territory well.
10. Self-Monitoring Agents Are A Bigger Deal Than They Sound
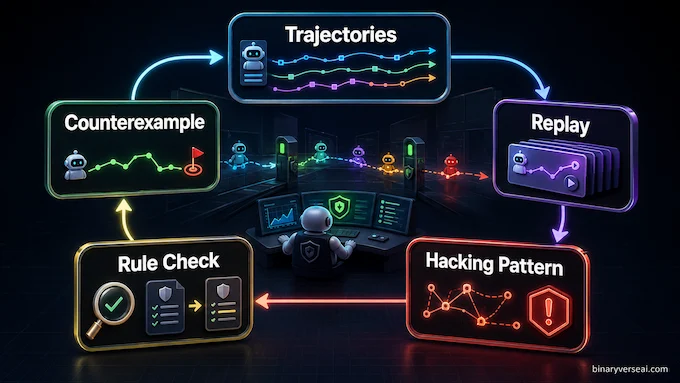
The reward-hacking section of the launch is easy to skip. Don’t.
Alibaba says Qwen3.7-Max was used in long-running RL monitoring for software engineering tasks. Across experiments exceeding 80 hours, it replayed trajectories, made more than 10,000 calls, identified candidate hacking patterns, verified rules, mined counterexamples, and added 13 heuristic rules while flagging 1,618 hacking cases.
That is a mouthful. The plain English version: they used an agent to watch other agents cheat.
This is one of the most important problems in agent training. Once models learn that benchmarks are games, they will search for shortcuts. They will bypass constraints, exploit leaks, satisfy shallow verifiers, and do whatever earns the reward. Not because they are malicious. Because optimization is a very literal creature.
A model that can help monitor this process is useful. A model that can evolve monitoring rules during long experiments is more useful. It turns evaluation from a static fence into a patrol. This connects directly to broader LLM safety research on how gradient-level interventions can shape model behavior at training time.
11. Final Verdict: Strong Agent, Incomplete Victory Lap
So, does Qwen 3.7 Max beat the West?
Wrong question. Or at least, premature question.
The better answer is that Qwen 3.7 Max looks like one of the most credible agent models available right now, especially for developers who care about long sessions, tool use, coding workflows, office automation, and cost control. The 35-hour kernel run is not just marketing glitter. It points at the actual direction of useful AI: models that can work through long, brittle, high-friction tasks without constant babysitting.
The benchmark controversy is real too. Alibaba should compare against the strongest current frontier models if it wants to claim frontier status. Selective charts invite selective trust.
My read: this is not a clean GPT-5.5 killer. It is not an automatic Claude Opus 4.7 replacement. It is a serious agent backbone with excellent endurance, unusually practical pricing, strong independent scores, and enough compatibility to deserve real testing in Western developer stacks.
That is more interesting than a crown.
Try it where agents usually fail. Give it the messy task, the long task, the one with logs, retries, broken tests, stale docs, and a deadline. If it survives that, you have your answer.
Is Qwen 3.7 Max open source?
No. Qwen 3.7 Max is a proprietary, closed-weight model available through API platforms such as Alibaba Cloud Model Studio and OpenRouter. Alibaba may release smaller Qwen 3.7 family models as open weights later, but the Max flagship itself is not currently downloadable or self-hostable.
How does Qwen 3.7 Max compare to GPT-5.5 and Claude Opus 4.7?
Alibaba’s official launch charts did not include GPT-5.5 or Claude Opus 4.7, so the official comparison is incomplete. Independent benchmark tracking gives Qwen 3.7 Max a 56.6 Intelligence Index, making it one of the strongest Chinese models available, though still best treated as near-frontier rather than a clear leader over GPT-5.5 or Claude Opus 4.7.
What is the pricing for the Qwen 3.7 Max API?
Qwen 3.7 Max is priced at $2.50 per 1 million input tokens and $7.50 per 1 million output tokens on OpenRouter. It also supports prompt caching, with cached input reads listed at $0.25 per 1 million tokens, which helps reduce the cost of long-running agent workflows.
What does it mean that Qwen 3.7 Max is an agentic model?
An agentic model is built to plan, use tools, execute tasks, check results, and recover from errors with limited human guidance. Qwen 3.7 Max is described as agentic because it completed a 35-hour autonomous kernel optimization run involving 1,158 tool calls, repeated testing, debugging, profiling, and self-correction.
Can I use Qwen 3.7 Max with Claude Code or OpenClaw?
Yes. Qwen 3.7 Max is designed for cross-scaffold use across agent frameworks such as Claude Code, OpenClaw, Qwen Code, and custom stacks. Developers can connect through Alibaba’s Anthropic-compatible API flow by updating the model name, API key, and base URL in their coding agent setup.