

The old meaning of “Flash” was simple: cheap, fast, good enough, and slightly disposable. Gemini 3.5 Flash breaks that mental model. This is not a bargain-bin chatbot with a racing stripe. It is Google’s attempt to turn the Flash tier into an agent engine, the kind of model you point at a terminal, a workflow, or a messy business process and ask, politely, to stop wasting everyone’s afternoon.
That shift matters because AI buyers are no longer impressed by demos where a model writes a poem about Kubernetes. Developers want tools that ship code, read giant contexts, call functions correctly, and don’t spend a small mortgage thinking about a button label. Google’s pitch is clear: Gemini 3.5 Flash is where speed meets useful autonomy. The catch is just as clear. The bill moved too. If you’ve been following the best LLMs for coding in 2025, this one belongs in that conversation.
Table of Contents
1. Gemini 3.5 Flash Benchmarks: The Full Scoreboard
| Category | Benchmark | Condition Or Metric | Gemini 3.5 Flash | Gemini 3 Flash | Gemini 3.1 Pro | Claude Sonnet 4.6 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|---|---|---|---|
| Coding | Terminal-Bench 2.1 | Agentic terminal coding, Terminus-2 harness | 76.2% | 58.0% | 70.3% | – | 66.1% | 78.2% |
| Coding | SWE-Bench Pro, Public | Diverse agentic coding tasks, single attempt | 55.1% | 49.6% | 54.2% | – | 64.3% | 58.6% |
| Agentic | MCP Atlas | Multi-step workflows using MCP | 83.6% | 62.0% | 78.2% | 69.5% | 79.1% | 75.3% |
| Agentic | Toolathlon | Real-world general tool use | 56.5% | 49.4% | – | – | – | 55.6% |
| UI Control | OSWorld-Verified | Agentic computer use | 78.4% | 65.1% | 76.2% | 72.5% | 78.0% | 78.7% |
| Expert Tasks | Finance Agent v2 | Financial analysis and decision-making | 57.9% | 42.6% | 43.0% | 51.0% | 51.5% | 51.8% |
| Expert Tasks | GDPval-AA | Economically valuable knowledge work, Elo | 1656 | 1204 | 1314 | 1676 | 1753 | 1769 |
| Multimodal | CharXiv Reasoning | Complex chart synthesis, no tools | 84.2% | 80.3% | 83.3% | 72.4% | 82.1% | 84.1% |
| Multimodal | MMMU-Pro | Multimodal understanding and reasoning, no tools | 83.6% | 81.2% | 80.5% | 74.5% | 75.2% | 81.2% |
| Multimodal | Blueprint-Bench 2 | Agentic spatial reasoning, normalized score | 33.6% | 0.0% | 26.5% | 6.7% | 24.5% | 36.2% |
| Long Context | MRCR v2, 8-Needle | 128k average | 77.3% | 67.2% | 84.9% | 84.9% | 59.3% | 94.8% |
| Long Context | MRCR v2, 8-Needle | 1M pointwise | 26.6% | 22.1% | 26.3% | – | – | – |
| Reasoning | Humanity’s Last Exam | Academic reasoning, text and multimodal | 40.2% | 33.7% | 44.4% | 33.2% | 46.9% | 41.4% |
| Reasoning | ARC-AGI-2 | Abstract reasoning puzzles | 72.1% | 33.6% | 77.1% | 58.3% | 75.8% | 84.6% |
The interesting story is not that Google found a few friendly numbers. Everyone does that. The story is where the numbers land. Terminal-Bench 2.1 puts 3.5 Flash at 76.2%, nearly on top of GPT-5.5 and ahead of Claude Opus 4.7 in the supplied table. MCP Atlas shows an even cleaner win, with Google’s new model beating every listed competitor. OSWorld-Verified is effectively a tie among the top models, which is a nice way of saying the UI-control race has moved from “cute demo” to “actual engineering problem.”
The weak spots are just as important. GPT-5.5 still dominates MRCR at 128k and ARC-AGI-2. Claude Opus 4.7 remains stronger on Humanity’s Last Exam and GDPval-AA. That means the new Flash is not the universal champion. It is something more specific and, for many teams, more useful: a very fast agent model that is now strong enough to be annoying to the expensive models.
2. The Agentic Pivot: Flash Is No Longer A Budget Model

The biggest change is conceptual. Gemini 3.5 Flash is not framed as a small model for cheap completions. It is framed as a workhorse for agentic execution, coding loops, long-horizon tasks, and multi-step workflows. That sounds like marketing until you map it to the benchmark set.
Terminal-Bench asks whether the model can survive in a terminal without wandering into the bushes. SWE-Bench Pro asks whether it can solve real software tasks rather than toy LeetCode puzzles wearing a blazer. MCP Atlas and Toolathlon ask whether it can coordinate tools, state, and actions over time. OSWorld asks whether it can operate software interfaces, which is where language models discover that pixels are cruel and menus have moods.
This is a different job description. The model is not only answering. It is planning, checking, calling tools, reading outputs, revising, and trying again. That makes latency more than a UX detail. In an agent loop, every extra second compounds. A model that is a bit less clever but dramatically faster can beat a deeper model when the task needs twenty calls, not one perfect paragraph.
3. The Speed Argument: 289 Tokens Per Second Changes The Feel

Speed is one of those metrics people pretend to care about until a model is slow. Then everyone suddenly becomes a distributed systems engineer.
The reported 289 tokens per second number matters because agentic work is interactive. Debugging is not a single majestic answer. It is a loop. Read the error, inspect the file, patch the code, run the test, break something new, mutter softly, repeat. In that setting, throughput is not vanity. It is oxygen.
A slow model can still be useful for deep research, hard math, or final reasoning passes. A fast model becomes part of your hands. It changes how willing you are to ask one more question, generate one more patch, or spin up one more sub-agent. The best tools disappear into muscle memory. The worst tools make you watch a progress bar and reconsider your career.
This is why Google’s speed story is stronger than it first looks. Flash used to mean low-cost responsiveness. Now it means enough intelligence at enough speed to make autonomous workflows feel less like theater.
4. Gemini API Pricing: The 300 Percent Moment
The uncomfortable part is the Gemini API pricing table. Google did not merely rename a model and sprinkle benchmark confetti. It moved the price.
| Model | Input Price Per 1M Tokens | Output Price Per 1M Tokens | Context Caching | Best Fit |
|---|---|---|---|---|
| Gemini 3 Flash Preview | $0.50 | $3.00 | $0.05 | Older Flash workloads and preview-era testing |
| Gemini 3.5 Flash | $1.50 | $9.00 | $0.15 | High-speed agents, coding loops, enterprise workflows |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | $0.025 | Cheap high-volume generation, translation, simple processing |
| Gemini 3.1 Pro Preview | $2.00 to $4.00 | $12.00 to $18.00 | $0.20 to $0.40 | Heavier reasoning and premium multimodal work |
That is a clean 3x jump from Gemini 3 Flash Preview to Gemini 3.5 Flash on both input and output. In plain English: the model got promoted, and so did the invoice.
There is a logic to it. Google appears to be splitting the lineup into clearer jobs. Flash-Lite becomes the place for cheap scale. Pro stays the premium reasoning shelf. Flash becomes the fast agent tier. That makes product sense, but developers do not pay invoices with product sense. They pay with budgets, and budgets have teeth. For a broader view of how these costs stack up, see our LLM pricing comparison.
The practical move is simple. Don’t migrate every workload blindly. Use the new Flash where speed and agentic competence change the outcome. Use Flash-Lite for routine extraction, classification, translation, and low-risk content operations. Use Pro or GPT-5.5 class models only where depth beats iteration speed.
5. The Hidden Cost: Thought Preservation And Token Drain
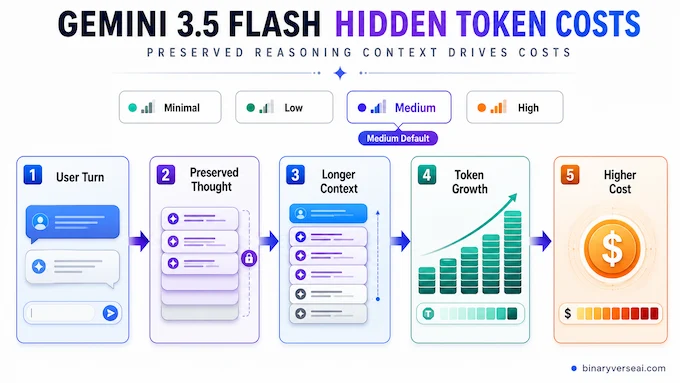
The published price is not the whole price. The second cost lives inside the conversation.
The new model carries intermediate reasoning context across turns when thought signatures are present. This “thought preservation” can help in multi-turn debugging and refactoring because the model does not have to rediscover the shape of the problem every time. For serious agent work, that is valuable. Forgetful agents are just interns with infinite confidence.
The tradeoff is input growth. Preserved reasoning context increases token count over multi-turn sessions, especially if you keep full conversation history. This is where developers get surprised. A task that used to feel like a tidy request can balloon into a context-heavy loop where every turn drags a backpack full of past thoughts. This is a known challenge across LLM inference optimization.
The default thinking effort also changed to medium. That is a sensible default for quality, but it can be expensive when the task is simple. For small transformations, quick summaries, or narrow function calls, medium may be a gold-plated spoon.
The fix is not mystical. Set thinking levels deliberately. Use minimal for basic chat-like responses. Use low for fast coding help and lightweight analysis. Keep medium for tasks that actually require planning. Use high for the hard stuff, the kind where you would rather pay for thought than debug nonsense at 2 a.m.
6. Google Antigravity AI: The Developer Playground Google Needed
Google Antigravity AI is the most commercially interesting part of this launch because it gives the model a place to act. Models without harnesses are like engines on a table. Impressive, loud, and not especially useful until bolted into a vehicle.
Antigravity is pitched as an agent-first development platform where sub-agents can run, coordinate, and attack larger workflows. That matters because the future of coding assistants is not one chat window giving advice. It is swarms of bounded workers: one agent reads the repo, another writes tests, another checks regressions, another updates docs, and the human does the adult supervision.
This is where 3.5 Flash’s speed becomes strategically important. Sub-agents are only practical if they are cheap enough and fast enough to run in parallel. A brilliant but slow model makes a lovely oracle. A fast, capable model makes a workforce.
The enterprise appeal is obvious. Banks, fintechs, data teams, and software orgs have piles of workflows that are too messy for simple automation and too repetitive for expensive human attention. Antigravity gives Google a way to sell not just intelligence, but execution. That is the difference between “our model can reason” and “our platform can close tickets.”
7. Gemini 3.5 Flash Vs GPT-5.5: Pick The Tool, Not The Religion
The Gemini 3.5 Flash vs GPT-5.5 comparison is not a fan war unless you enjoy wasting time in comment sections. The models have different shapes. For a deeper look at how the GPT-5 family performs on coding tasks, see our GPT-5.2 and Codex benchmarks breakdown.
GPT-5.5 looks stronger in the supplied table on ARC-AGI-2, MRCR at 128k, GDPval-AA, and Terminal-Bench by a small margin. That suggests deeper reasoning, stronger long-context retrieval at 128k, and broader high-end knowledge work. If your task is mathematically gnarly, deeply abstract, or mission-critical in a single pass, GPT-5.5 remains the safer bet.
Gemini 3.5 Flash wins or ties in places that matter for agents. It leads MCP Atlas. It is effectively level with the top group on OSWorld-Verified. It beats GPT-5.5 on MMMU-Pro and narrowly edges CharXiv Reasoning in the supplied numbers. More importantly, it does this while pushing speed as a first-class feature.
The right question is not “which model is smarter?” The right question is “where does failure cost more, latency or reasoning depth?” For one-shot expert analysis, pick depth. For iterative code repair, supervised agents, UI workflows, and parallel exploration, pick speed plus competence.
8. The Developer Migration Checklist
The API changes are small enough to miss and sharp enough to cut you. The official Gemini 3.5 Flash model card covers these technical specifications in full detail.
- First, stop tuning temperature, top_p, and top_k out of habit. Google now recommends leaving sampling defaults alone for Gemini 3.x. That will annoy people who learned prompt engineering by touching every knob like a spaceship pilot, but it makes sense. Reasoning models are often more stable when the reasoning policy is left intact.
- Second, replace numeric thinking budgets with thinking_level. The new language is simpler: minimal, low, medium, high. Use it like an engineering control, not a personality test.
- Third, tighten function calling. Function responses need matching id, matching name, and one response per function call. Loose matching can produce empty responses, which is the API equivalent of a model staring at you and pretending nothing happened.
- Fourth, put multimodal content inside the function response, not beside it. If a tool returns an image, audio, or other media, keep it in the response part. Side-loading content invites weird behavior.
- Fifth, treat tool calls as a budget. Higher thinking levels may explore more aggressively. That can be useful for hard tasks, but expensive for routine jobs. Tell the model when actions are scarce. Good agents need boundaries. So do junior developers and, frankly, most adults.
9. The Missing Pieces: Computer Use And Pro
One limitation deserves a red circle. Direct Computer Use is not supported in the stable 3.5 Flash release described in the provided material. That is awkward because the benchmark story leans heavily into UI control and agents. For browser-control or computer-use workloads, teams may still need older preview options or specialized models until support lands.
There is also the looming Pro release. Google says 3.5 Pro is already being used internally and is expected next. That model will almost certainly target the premium end: deeper reasoning, tougher coding, heavier multimodal tasks, and pricing that makes procurement blink twice.
That leaves 3.5 Flash in an interesting middle position. It is not the cheapest model. It is not the deepest model. It is the model Google wants developers to use when the task needs movement. In modern AI systems, movement is becoming the product.
10. Final Verdict: Migrate Carefully, But Take This Seriously
Gemini 3.5 Flash is not just a faster autocomplete engine. It is Google’s clearest statement yet that the next major platform fight is agent execution, not chat polish. The model’s strongest case is not that it beats every frontier rival everywhere. It doesn’t. Its strongest case is that it is fast enough, capable enough, and integrated enough to make multi-agent workflows feel practical.
The pricing makes casual migration risky. The thought-preservation behavior can quietly inflate token usage. The lack of direct Computer Use support leaves a real gap. None of that cancels the core point: this is a serious model for builders.
Use Flash-Lite when cost matters more than autonomy. Use GPT-5.5 or a Pro-class model when the task demands maximum depth. Use 3.5 Flash when you need fast agents that can code, inspect, iterate, and keep a workflow moving without turning every turn into a coffee break.
The best way to evaluate it is not with a prompt like “write me a blog post.” Please, let’s respect silicon. Give it a repo, a failing test suite, a messy internal process, or an Antigravity workflow with real constraints. Then measure what matters: completed tasks, tool calls, latency, token cost, and human minutes saved.
That is the new benchmark. Not whether the model sounds smart, but whether your team gets Friday afternoon back. If 3.5 Flash can do that reliably, the Flash name has finally grown up.
Why Is The Gemini 3.5 Flash API Pricing So Much Higher Than 3.0?
Google has repositioned Flash. Gemini 3.5 Flash is no longer the cheap chatbot tier. It is now a frontier-style agentic model built for coding, tool use, and multi-step workflows. That is why pricing moved from $0.50 input and $3.00 output to $1.50 input and $9.00 output per 1M tokens.
Why Does Gemini 3.5 Flash Use So Many More Tokens Than Previous Models?
Gemini 3.5 Flash can use more tokens because of thought preservation and its default medium thinking effort. The model carries reasoning context across multi-turn conversations, which improves complex debugging and agent tasks but increases input token usage. For simpler jobs, developers should lower the thinking level or clear reasoning history.
Is Gemini 3.5 Flash Better Than GPT-5.5 And Claude Opus 4.7?
Gemini 3.5 Flash is not better at everything, but it is much faster. It competes closely with GPT-5.5 and Claude Opus 4.7 on agentic and coding benchmarks while delivering around 289 tokens per second. GPT-5.5 still leads in some deep reasoning tasks, but Gemini 3.5 Flash is stronger for rapid coding loops.
What Is Google Antigravity AI?
Google Antigravity AI is Google’s agent-first developer platform for building and running AI coding agents. It gives Gemini 3.5 Flash a practical environment for multi-step workflows, subagent coordination, code execution, and long-running developer tasks. Think of it as Google’s answer to agentic coding tools like Cursor and Claude Code.
Are The Gemini 3.5 Flash Benchmarks Real Or Benchmaxxed?
The benchmarks are real, but they still need real-world testing. Gemini 3.5 Flash scores strongly on agentic tests like Terminal-Bench 2.1, MCP Atlas, and OSWorld-Verified. The fair view is this: Google’s numbers are impressive, but developers should judge the model by completed tasks, token cost, latency, and reliability in production.