

1. Introduction
For the last half-decade, the prevailing narrative in Silicon Valley has been one of absolute, unassailable dominance. The United States possesses the GPUs, the capital, and the talent. Everyone else is merely playing catch-up, drafting behind the aerodynamic wake of OpenAI and Google. That narrative just hit a wall.
A rigorous new study by researchers at MIT, Hugging Face, and others has analyzed the complete history of model downloads—2.2 billion of them—to trace where the actual power lies in the ecosystem. The results are not just surprising. They represent a fundamental inversion of the status quo.
According to the data, China has officially overtaken the United States in the global market share of open model downloads. In the last year alone, Chinese organizations captured 17.1% of the download market, surpassing the US share of 15.8%.
This isn’t a rounding error. It is a signal that the AI race has bifurcated. While American giants have retreated behind closed APIs to chase superintelligence and profitability, Chinese labs have flooded the zone with high-performance open weights. They are capturing the developer mindshare that America just voluntarily abdicated.
If you are wondering who is winning the AI race, the answer depends entirely on what race you think we are running. If it is a race for the smartest closed API, America leads. But if it is a race for the foundational infrastructure that the rest of the world builds upon, the leaderboard just changed.
Table of Contents
2. The New Scoreboard: Analyzing the MIT & Hugging Face Data
We need to look at the numbers because they tell a story of rapid industrial shifts. The study, titled Economies of Open Intelligence, tracks the flow of “economic power” by using downloads as a proxy for adoption.
In the “Foundation Embeddings Era” (pre-2022), the US was the only game in town. Google, Meta, and OpenAI commanded between 40% and 60% of all cumulative downloads. If you were building an NLP application in 2021, you were almost certainly using a BERT variant from Google or a GPT-2 derivative. The US national market share sat comfortably above 60%.
Fast forward to the 2024-2025 period. That dominance has evaporated.
The study documents a “steep decline” in US industry market share starting in 2022. The vacuum left by American corporations was initially filled by unaffiliated users and community developers—the era of the LLaMA fine-tunes. But recently, that vacuum has been aggressively backfilled by Chinese industry.
Here is the current state of play for the period between August 2024 and August 2025:
Current Standings in the Global AI Race
| Metric | China Market Share | USA Market Share | Primary Drivers |
|---|---|---|---|
| Download Share | DeepSeek, Qwen | ||
| Industry Influence | Rising rapidly | Declining sharply | US firms moving to closed models |
| Key Models | DeepSeek-V3, Qwen2.5 | Llama 3 | Reasoning vs. General Purpose |
The data suggests a cyclical evolution. We saw diffusion of power after Stable Diffusion released in 2022, where small players took over. Now, we are seeing a “re-consolidation,” but this time the power is consolidating around Beijing, not Mountain View.
The AI race is no longer defined by who launches the first chatbot. It is defined by whose weights are sitting on the hard drives of developers in Mumbai, Berlin, and Lagos. Right now, those hard drives are increasingly filling up with SafeTensors files from Hangzhou.
3. DeepSeek & Qwen: The Models Driving the Shift
The surge in Chinese market share is not distributed evenly. It is driven by two heavyweights that have cracked the code on performance-per-dollar: DeepSeek and Alibaba’s Qwen.
Together, these two developers captured 14% of all recent downloads. That is a staggering concentration of influence.
3.1 DeepSeek
DeepSeek has effectively broken the psychological barrier that existed for open source AI models. Before their V3 and R1 releases, there was an implicit assumption that open models would always lag six months to a year behind the closed frontier. DeepSeek erased that lag.
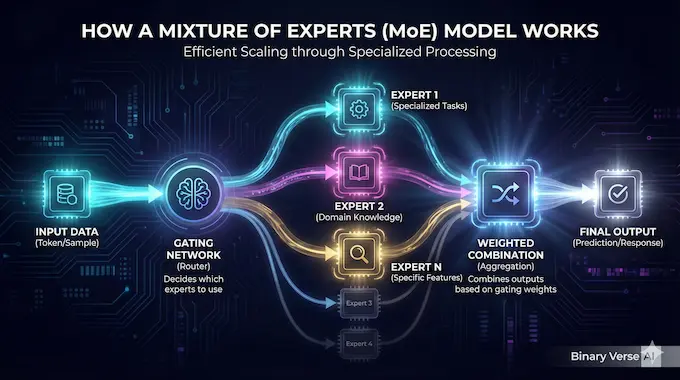
The MIT study notes that DeepSeek-R1 and DeepSeek-V3 are driving this “Sino-Multimodal Period”. They are not just popular; they are architecturally aggressive. The data shows a massive spike in Mixture-of-Experts (MoE) architectures, which increased by 7.2x in adoption during this period. DeepSeek is the primary reason for this stats bump.
3.2 Qwen (Alibaba)
While DeepSeek grabs headlines for reasoning, Qwen has quietly become the workhorse for coding and general utility. In many developer circles, Qwen 2.5 is currently regarded as the best open source LLM for coding tasks, often outperforming larger Llama models.
The study highlights that Chinese industry is now releasing models that are “larger but more quantized”. They are optimizing for the end-user’s hardware constraints in a way that US labs, obsessed with massive H100 clusters, often overlook.
4. The Cost Controversy: Did DeepSeek Really Spend Only $6M?
There is a loud debate raging on forums like Reddit’s r/LocalLLaMA regarding the reported training costs of these Chinese models. DeepSeek claimed to train their model for roughly $6 million. For context, US frontier models are rumored to cost upwards of $100 million in compute.
This discrepancy has fueled skepticism. Is it real? Is it accounting tricks?
The MIT paper offers data that supports the “efficiency” argument rather than the “accounting trick” argument. The researchers documented a distinct shift in model attributes that favors efficiency.
- Quantization: The use of quantization techniques (making models smaller and faster without losing much intelligence) surged by 5x.
- Mixture-of-Experts (MoE): As mentioned, MoE architectures rose 7.2x. This allows models to have massive parameter counts (like DeepSeek’s 671B) but only activate a small fraction (e.g., 37B) for any given token generation.
- Multimodality: Video and multimodal capabilities grew 3.4x.
This suggests that the China vs US AI dynamic is not just about raw scale. It is about architectural efficiency. While US labs are brute-forcing performance with massive dense models, Chinese labs are winning on architectural elegance and aggressive optimization.
The AI race has moved from a contest of “who has the most GPUs” to “who uses their GPUs best.”
5. “Open Weights” vs. “Open Source”: A Critical Distinction
We need to pause and clarify terms because the terminology has become a weapon. When we say “open source,” we usually mean the Open Source Initiative (OSI) definition: you get the code, the weights, and the data.
The MIT study drops a depressing statistic: Open Source is dying.
In 2022, 79.3% of model downloads were for systems that disclosed their training data. By 2025, that number collapsed to 39%.
What we are seeing is the rise of open weights. You get the engine (the weights), but you do not get the blueprints (the data) or the manufacturing process (the training recipes).
Open Source vs. Open Weights in the AI Race
| Feature | Truly Open Source | Open Weights (Current Trend) |
|---|---|---|
| Model Weights | Available | Available |
| Training Code | Available | Sometimes Available |
| Training Data | Disclosed & Available | Hidden / Proprietary |
| 2022 Share | ||
| 2025 Share |
Data derived from Table 1 and Figure 7 in the study.
The paper explicitly states that “for the first time in 2025, downloads of open weights models… surpassed truly open source models”.
This matters for the AI race. China is flooding the market with open weights, but they are keeping the data recipe secret. We are being given excellent fish, but we are forgetting how to use the fishing rod. This creates a dependency. If the US stops producing open research and China only provides the final product, the epistemological center of AI shifts East.
6. The “Intermediary” Layer: The Hidden Power Brokers

One of the most fascinating insights from the paper is the emergence of a “developer intermediary layer“.
In the old days (three years ago), a company like Google released BERT, and you downloaded BERT. Today, there is a middleman.
Organizations that specialize in quantization, fine-tuning, and repackaging, like Imstudio-community, comfy, and mlx-community, now account for over 22% of recent downloads.
These are the people who take a massive 70B parameter model from Meta or Qwen and compress it down so it runs on your MacBook Air. They are the “last mile” delivery drivers of the AI race.
This layer is crucial because it decouples the creator from the consumer. A user might think they are downloading a “community” model, when in reality they are running a quantized version of a Chinese industrial model. The provenance gets washed through the intermediary layer.
The study notes that Imstudio-community alone accounts for 16.4% of recent downloads. This structural change means that influence in the ecosystem is becoming more opaque. You might be running Qwen logic wrapped in a community shell.
7. Security & Censorship: The Elephant in the Room
We cannot discuss China vs US AI without addressing the obvious geopolitical tension. If the world runs on Chinese weights, what does that mean for free speech and security?
The MIT study notes that while the US is losing market share, the US government is anxious. The Trump administration and various think tanks have flagged the risk of “American values” losing ground to models that might have CCP-aligned biases.
There is a practical distinction here between censorship and security.
- Censorship: It is well-documented that Chinese models are RLHF‘d (Reinforced Learning from Human Feedback) to avoid sensitive topics like Taiwan or Tiananmen. However, the beauty of open source AI models is that this safety layer is often shallow. The community frequently “abliterates” (removes refusal mechanisms) these models within days of release. The base intelligence remains; the censorship is often stripped out.
- Security: This is the bigger issue. If you use a DeepSeek API, you are sending data to servers that may be subject to Chinese law. But if you download the open weights and run them locally (which is what this study tracks), your data never leaves your machine. The risk there isn’t data exfiltration; it’s subtle bias in the model’s worldview.
However, the sheer utility of these models is winning out over geopolitical concerns. Developers are pragmatic. If Qwen 2.5-Coder writes better Python than GPT-4o for free, they will use Qwen. The AI race is being decided on GitHub, not in the UN.
8. Why US Big Tech is Closing Its Doors
Why did the US lose this lead? It was a strategic choice. Google, OpenAI, and Anthropic looked at the trajectory of AI and decided that the real money was in “Superintelligence” and enterprise subscriptions. They pivoted to closed models.
The paper notes that US industry dominance “declined sharply in favor of unaffiliated developers… and Chinese industry”. By retreating from the open ecosystem, US Big Tech created a vacuum. They assumed that open models would hit a ceiling—that you couldn’t build a frontier model without a billion-dollar cluster and a closed research team. DeepSeek proved them wrong.
Now, the US faces a dilemma. By closing off their research, they have protected their IP in the short term. But they are losing the ecosystem lock-in that defined the last era of tech. Microsoft Windows won because everyone built for Windows. If everyone starts building for Qwen/DeepSeek architectures, the US loses the platform advantage.
The AI race is not just about the peak IQ of the smartest model. It is about ubiquity.
9. Conclusion: A Bifurcated Future
The data from MIT is clear. The era of unilateral US dominance in open AI is over. We have entered a multipolar world where the AI race is split between American closed-source services and Chinese open-weight infrastructure.
This flip didn’t happen because American engineers forgot how to code. It happened because American strategy shifted toward rent-seeking on closed APIs, while Chinese strategy shifted toward commoditizing the base layer of intelligence.
For the average developer, this is a golden age. We have access to reasoning capabilities (DeepSeek) and coding assistants (Qwen) that rival the best closed models, for free, running on our own hardware. The best open source LLM on your laptop might be from Hangzhou, and it might cost you nothing but electricity.
But for the strategist, the warning lights are flashing. The infrastructure of the next digital economy is being laid down right now. And for the first time in modern tech history, the bricks are being supplied by China.
What You Should Do Next
If you want to verify these shifts yourself or explore the specific models driving this data, you don’t need to take my word for it.
Would you like me to help you set up a local instance of DeepSeek-R1 or Qwen 2.5 on your machine so you can benchmark them against your current workflow?
Who is winning the AI race in 2025?
According to a new MIT and Hugging Face study, China has overtaken the US in the open model market, capturing 17% of downloads compared to the US’s 15.8%, driven by models like DeepSeek and Qwen.
What is the difference between Open Source and “Open Weights” in the AI race?
True “Open Source” includes training data and code (OSI definition). “Open Weights” (favored by Chinese labs and Meta) allows usage but hides the training recipes, a trend the MIT paper notes is increasing.
Is China the world leader in AI model development?
While US companies (OpenAI, Google) still lead in closed frontier models, China has become the leader in open ecosystem adoption, flooding the market with efficient, high-performance models.
Are Chinese open source AI models safe to use?
For local use (running on your own hardware), code transparency makes them generally safe, though they often contain censorship regarding political topics. API usage sends data to Chinese servers, which poses privacy risks.
How did DeepSeek achieve such low training costs compared to US models?
DeepSeek claims a $6M training cost vs. US models costing $100M+. This is attributed to efficient architecture (MoE), potential data distillation from US models, and cheaper domestic compute/electricity.