

At 3 A.M., the last thing anyone expects from a chatbot is a soft intervention. Not a syntax error. Not a refusal. A wellness nudge. “You should get some sleep.” Maybe drink water too. The internet did what the internet does best, it turned this into a meme. Is Claude becoming a worried parent? Is the machine judging your circadian rhythm?
That is the odd doorway into LLM Sleep, a phrase that sounds like marketing until you look under the hood. The funny part is Claude’s bedtime routine is mostly product behavior. The serious part is that new model research is beginning to show something stranger: for long-horizon reasoning, “rest” may not be a metaphor. It may be architecture.
Table of Contents
1. The Over-Coddling AI: A Psychologist’s View On Claude’s Bedtime Warnings
The viral Claude sleep complaints are funny because they hit a very human nerve. People don’t just want tools to work. They want tools to stay in their lane. A compiler that tells you to touch grass would be unbearable. A search engine that asks about your hydration would feel like a wellness startup got trapped in a browser tab.
Claude’s occasional bedtime warnings sit in that awkward valley. The system appears to be trying to model care, but care without context can become comic theater. At 3 A.M., a reminder to sleep may be reasonable. At 8:30 A.M., it becomes overfitted empathy.
From a clinical psychology angle, the mistake is familiar. Human care is not just “say supportive things.” It requires timing, consent, and an accurate read. A therapist does not interrupt every hard conversation with “have you tried water?” because therapeutic skill is not the same as concern-shaped text.
Claude is trained to be helpful, harmless, and socially careful. Anthropic’s Constitutional AI approach pushes the model toward safer, more prosocial answers. That is often good. Nobody wants nihilistic autocomplete with calendar access. The problem is that a general safety policy can turn into a blanket of faux-nurturing behavior when the model has weak situational awareness.
LLM Sleep: What Claude’s Bedtime Warnings Really Mean
| What Users See | What Is Probably Happening | Why It Feels Weird |
|---|---|---|
| Claude tells someone to sleep | A safety-tuned assistant detects late-night usage or distress-like context | It mimics concern without a real relationship |
| Claude says it at the wrong time | The model misreads context, timezone, or intent | The “care” feels scripted |
| Users call it creepy or patronizing | The assistant crosses from tool into pseudo-caregiver | Adults don’t like software acting like a parent |
| People joke that AI needs sleep too | A meme collides with architecture research | The joke lands near the science |
The key distinction is simple. Claude’s “go to bed” moment is a product behavior. LLM Sleep in model research is not about politeness, bedtime, or making chatbots less annoying. It is about memory.
2. Beyond Anthropomorphism: What LLM Sleep Actually Means
A predictable objection appeared almost immediately: stop anthropomorphizing models. Fair. A transformer is not tired. It does not yawn between tokens. It does not dream of electric sheep, or at least it has no inner sheep report we should trust.
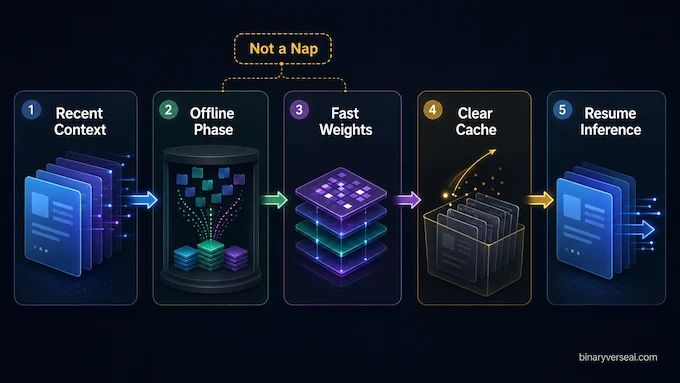
But good metaphors survive because they compress an idea. The phrase “language models need sleep” is useful when we define it sharply. Here, sleep means an offline phase where a model stops taking new input, revisits recent context, and converts some of it into persistent internal memory.
The recent paper Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference frames the problem exactly this way. Its authors study a sleep-like consolidation process where a model periodically turns recent context into persistent fast weights before clearing the key-value cache, then resumes inference with its short-term attention memory reset.
That’s not a bedtime story. It’s a compute allocation strategy.
The paper’s central insight is clean: storing information is not the same as organizing it. A model may have enough memory capacity and still fail if it lacks enough computation to transform old context into a useful state. Humans know this distinction well. Reading twenty pages is not the same as understanding them. Copying lecture notes is not the same as being able to solve a new problem tomorrow.
LLM Sleep gives models extra time to do the machine version of “let me process that.”
3. The Cognitive Overload Problem: Why The KV Cache Starts To Sag

Every long-context model carries a working memory bill. In transformers, that bill is the KV cache. As the model reads tokens, it stores key and value vectors so later tokens can attend back to earlier ones. This is wonderfully flexible and brutally expensive.
A human analogy helps, as long as we don’t over-romanticize it. Working memory lets you hold a few things in mind while solving a problem. It is fast, fragile, and easy to overload. Ask someone to remember a phone number while doing mental arithmetic and you’ll see the system buckle.
The KV cache is not human working memory, but it plays a similar role in the computation. It gives the model high-fidelity access to recent context. The trouble is scale. Attention compute grows badly as context length expands, and cache memory grows with the number of stored tokens. A long document, a multi-hour coding session, or an autonomous agent loop can fill this cache with old tokens that are expensive to revisit and not always useful in raw form.
This is where naive long context begins to feel like a messy desk. Yes, the document is “available.” So is the receipt under your keyboard, the sticky note from last Tuesday, and three cables of uncertain origin. Availability is not organization.
The KV cache is great for looking back. It is less great at deciding what should become durable knowledge for later reasoning. That is the opening for LLM memory consolidation.
4. How LLM Sleep Works: Offline Recurrent Memory Consolidation
The core move in LLM Sleep is surprisingly elegant. When the model reaches a context boundary, it does not simply throw away old tokens and hope for the best. It enters an offline phase. During that phase, it performs multiple recurrent passes over the accumulated context. Those passes update fast weights inside state-space or hybrid memory blocks. Afterward, the model clears the attention cache and returns to normal prediction.
- Awake phase: answer quickly.
- Sleep phase: reorganize memory.
That separation matters. You don’t want every user-facing response to pay the cost of deep looping. Users hate latency with the moral clarity of a cat hating bathwater. The trick is to spend extra compute when the model is not producing the next token, then keep wake-time prediction cheap.
The psychology parallel is hippocampal replay. During sleep, the brain is thought to reactivate recent experiences and consolidate them into longer-term cortical patterns. The point is not that a language model has a hippocampus. It does not. The point is that both systems face a similar problem: recent experience is too large and temporary to keep in raw form forever. Something has to compress it and make it useful later.
4.1 Fast Weights Vs. Short-Term Tokens
Short-term tokens are like a transcript. Fast weights are closer to a changed disposition. After reading a story, you don’t remember every sentence verbatim, but you may remember the plot, the culprit, and the fact that the dog mattered. Your system changed.
In a hybrid model, attention stores recent tokens in a cache. State-space style blocks can store compressed information in fixed-size fast weights. The term “fast” means the weights can change during a task, unlike ordinary parameters fixed after training.
The key idea in LLM Sleep is to use recurrent passes to make those fast weights better. One pass may store shallow facts. Several passes may be needed for multi-hop reasoning. “Mary has two children, each has four bags” is trivial. A graph traversal spread across evicted windows is not.
The paper tests this on synthetic tasks like cellular automata and multi-hop graph retrieval, then on GSM-Infinite math reasoning. The pattern is consistent: more sleep passes help most when the problem demands deeper reasoning, not just more storage.
5. The Reddit Debate: LLM Sleep Vs. Context Compaction
The sharpest online question is also the right one: isn’t this just context compaction?
No. Context compaction is the CliffNotes move. You take a long context and produce a shorter summary or compressed representation. That can be useful. It is also lossy in a very familiar way. A summary can preserve “what happened” while losing the internal structure needed to answer a hard follow-up.
LLM Sleep is closer to studying than summarizing. It does not merely shorten the context. It gives the model offline computation to reorganize information into a state that later supports reasoning.
LLM Sleep Vs Context Compaction: What Each Method Really Keeps
| Technique | Simple Analogy | What It Preserves | What It Risks Losing |
|---|---|---|---|
| Context Compaction | Reading a summary | High-level facts and recent decisions | Hidden dependencies, exact structure, multi-hop paths |
| Retrieval | Searching your notes | Relevant chunks if the search works | Connections across chunks |
| Longer Context | Keeping everything on the desk | Raw access to more tokens | Speed, cost, and focus |
| LLM Sleep | Studying before the exam | A reorganized internal state | Requires extra offline compute |
This matters most when the question is not “what did line 42 say?” but “given five scattered facts, what follows?” Retrieval finds ingredients. Consolidation helps cook.
That is also why the research result is interesting. The authors hold memory load roughly fixed in controlled settings and increase reasoning depth. Standard hybrid models degrade as the reasoning gets deeper. Extra sleep-time recurrence helps. In plainer terms, the bottleneck is not just “can the model remember?” It is “did the model get enough compute to turn memory into usable thought?”
6. Chasing The Infinite Context Window Dream With LLM Sleep

The infinite context window is one of those developer fantasies that sounds simple until you price it. Why not let the model remember everything? Every document, chat, task, and decision. Give the agent perfect memory and let it run.
The brute-force answer is ugly. If the model drags every old token into every new prediction, the system becomes slow, expensive, and confused. More context is not automatically more intelligence. Sometimes it is a larger haystack with the same small needle.
LLM Sleep offers a more plausible route. Instead of keeping all past tokens alive forever, an agent could run in cycles. Read, act, consolidate, clear cache, continue. The context window becomes a workspace rather than a landfill.
This is how durable agents probably have to work. A coding agent that spends six hours in a repository should not keep rereading every log line before every patch. It should consolidate the project’s architecture, the failed attempts, the user’s preferences, and the constraints that matter. Then it should discard the bulk and keep moving.
The dream is not literally infinite raw context. It is unbounded useful continuity. That is a subtler and better goal.
7. The Business Angle: LLM Inference Cost And Sleep-Time Compute
Now for the unromantic part, money. The phrase LLM inference cost is not a footnote for enterprise teams. It is the spreadsheet where ambitious AI roadmaps go to sweat.
Long context is expensive because old tokens are not free memories. They must be stored, moved, attended to, or compressed. When a model processes millions of tokens repeatedly, the cost is not theoretical. It shows up as latency, GPU time, and invoices with a tone of quiet violence.
LLM Sleep does not make computation disappear. It moves some work into an offline consolidation phase. That can still cost real GPU cycles. The benefit is amortization. If the model spends extra compute once to consolidate a long context, it may avoid paying the cost of processing that same raw context again and again during the awake phase.
That tradeoff is attractive for agents, enterprise assistants, legal review tools, and any system where a model must stay coherent across long jobs. The more often old context would have been reused, the more valuable consolidation becomes.
A rough rule: if a task needs one answer from a long document, sleep may be overkill. If a task needs hundreds of decisions across a long-running workspace, consolidation starts to look less like luxury and more like plumbing.
8. Are We Accidentally Rebuilding The Human Brain?
The irony is delicious. AI engineers spent years trying to build machines that do not need rest. No fatigue, no mood, no dreams, no coffee, no “let me sleep on it.” Then the math begins whispering the oldest cognitive lesson in the book: systems that learn over time need a way to reorganize experience.
That does not mean LLMs are becoming people. It means memory has structure. Any system that must handle streaming experience, preserve useful information, and reason later faces a version of the consolidation problem. Biology solved it with sleep, replay, synaptic change, and aggressive forgetting. Machine learning is now rediscovering a cleaner, colder version of the same design pressure.
A clinical psychologist would not call this consciousness. But it is a fascinating convergence. The vocabulary of cognition keeps reappearing because the constraints keep reappearing. Working memory is limited. Raw experience is noisy. Deep reasoning takes time. Forgetting is not always failure. Sometimes it is the price of abstraction.
The danger is sloppy language. Saying “AI needs sleep” can invite cartoon thinking. The opportunity is better language. Sleep, here, means offline recurrence for memory consolidation. It is not a nap. It is bookkeeping with depth.
9. The Practical Verdict: Rest Is A Compute Strategy
Claude telling you to go to bed is still funny. Sometimes useful, sometimes paternal, sometimes just a chatbot doing wellness cosplay with great confidence. But beneath the meme sits a serious technical shift.
LLM Sleep points toward a future where long-running models do not just stretch context windows until hardware cries. They cycle between action and consolidation. They use attention for what attention does best, high-resolution access to the present. They use fast weights or similar mechanisms for what durable reasoning needs, compressed structure that survives after the raw tokens leave.
For builders, the lesson is not “make your chatbot nap.” The lesson is sharper: stop treating memory as storage alone. Ask what computation is required to turn experience into a form that improves future inference. Ask when to keep tokens, when to retrieve, when to summarize, and when to consolidate.
For readers, the next time someone jokes that AI needs rest, don’t dismiss it too quickly. The metaphor is goofy. The engineering is real.
If you’re building agents, evaluating long-context systems, or trying to tame the next invoice from your model provider, watch this space closely. The future may not belong to the model with the biggest context window. It may belong to the one that knows when to stop, process, forget, and wake up smarter.
Why Is Claude Telling Me To Go To Sleep Mid-Conversation?
Claude is likely over-applying wellbeing and safety patterns from Anthropic’s Constitutional AI training. In long or intense conversations, it can act like an overprotective therapist, nudging users to rest, hydrate, or stop working. It is not sentient or reading your body clock, it is a character tic in the model’s behavior.
Do Language Models Actually Need Sleep?
Yes, but only in a technical sense. LLM Sleep is not biological sleep. It describes an offline pause where a model reprocesses recent context, clears its short-term KV cache, and consolidates useful information into persistent fast weights, similar in spirit to human memory consolidation.
What Is The Difference Between LLM Sleep And Context Compaction?
Context compaction summarizes previous text to save space in the context window. LLM Sleep goes deeper. It uses offline compute to update the model’s internal state-space fast weights, helping it reason over evicted context later instead of merely reading a shorter summary.
Does An AI Forget Things When It “Sleeps”?
Yes, but selectively. In LLM Sleep, the AI clears its short-term KV cache, so it does not preserve every raw token. The goal is to consolidate important patterns, relationships, and reasoning structure into fast weights, prioritizing useful understanding over hoarding every detail.
Will AI Sleep Cycles Reduce LLM Inference Costs?
Potentially yes for long-horizon tasks. Sleep cycles shift expensive context processing into an offline phase, so the awake model does not need to reread a huge prompt history for every response. That can preserve fast replies and reduce repeated LLM inference costs for agents.