

MiniMax M3 arrives with the kind of launch copy that makes engineers both curious and allergic. Frontier coding. One million tokens. Native multimodality. Open weights coming soon. Cheaper than the usual suspects. Somewhere, a product manager is already updating a roadmap slide with fireworks.
The interesting part is not the fireworks. It’s the engineering bet underneath them.
Long-context models have been fashionable for a while, but most of them behave like people carrying a large backpack full of unread books. The capacity is there. The retrieval, judgment, and stamina are not always there. MiniMax M3 matters because MiniMax is not merely stretching the input window. It is trying to make long context computationally normal through MiniMax Sparse Attention, while keeping enough standard transformer machinery intact to run in real systems.
Table of Contents
1. The MiniMax M3 Hype Vs Developer Reality
The headline claim for MiniMax M3 is simple: a model that combines agentic coding, 1M-token context, and multimodal input in one open-weight package. The official release says the API is live, the context window reaches up to 1M tokens, and the model can handle image and video input along with desktop computer operation. It also says model weights and the technical report are scheduled to follow within 10 days of the June 1, 2026 launch.
That is a serious claim, but benchmarks are not invoices from God. They are lab instruments. Useful, sometimes beautiful, occasionally misleading, and often dangerous in the hands of people who skip the methods section.
A better way to read this launch is as a systems proposal. MiniMax M3 is asking developers to believe three things at once: sparse attention can preserve enough quality, long context can stay useful beyond demo prompts, and an open-weight model can compete in agentic coding without requiring frontier-model pricing. Each claim is plausible. None should be accepted without your own tests.
1.1 MiniMax M3 Benchmark: Complete Matrix
The table below keeps the full comparison set from the published benchmark matrix and the official release context. Treat it as vendor-reported evidence, not a substitute for your own workload tests.
MiniMax M3 Benchmarks
| Benchmark | M3 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE Bench Pro | 59.0 | 64.3 | 58.6 | 54.2 |
| Terminal Bench 2.1 | 66.0 | 66.1 | 78.2 | 70.0 |
| VIBE V2 | 50.1 | 55.8 | 50.5 | 28.0 |
| SVG-Bench | 63.7 | 62.3 | 58.2 | 59.2 |
| KernelBench Hard | 28.8 | 30.7 | 20.9 | 18.6 |
| BrowseComp | 83.5 | 79.3 | 84.4 | 85.9 |
| GDPval Rubrics | 74.7 | 79.8 | 80.6 | 57.8 |
| Banker ToolBench | 76.1 | 81.3 | 70.0 | 67.0 |
| MCP Atlas | 74.2 | 77.0 | 75.3 | 69.2 |
| OSWorld-Verified | 70.0 | 82.8 | 78.7 | 76.2 |
The shape of the data is more useful than the scoreboard. Opus 4.7 still looks strongest where system-level reasoning, OS interaction, and backend discipline matter. GPT-5.5 dominates Terminal Bench 2.1, which suggests strong sequential command-line behavior. Gemini 3.1 Pro is weird in the way very capable models often are, brilliant at browsing and much weaker on some specialized engineering tasks.
MiniMax M3 is the interesting middle. It is not the best at everything. That would be suspicious anyway. It is competitive across most rows, leads SVG-Bench, and comes within shouting distance of the frontier models on coding while promising a very different cost and deployment story.
2. Demystifying MiniMax Sparse Attention
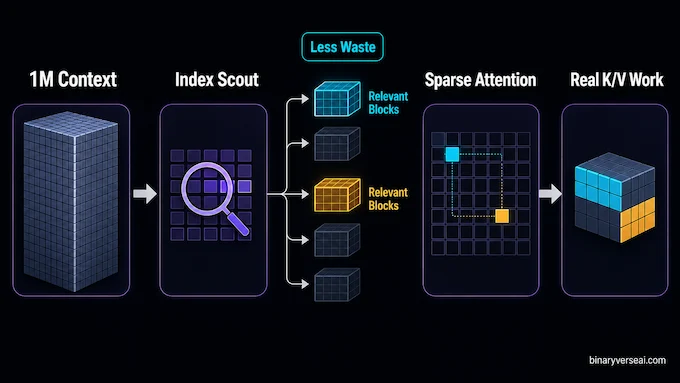
Full attention is elegant until your context window becomes a small novel, then a large codebase, then a repository plus logs plus screenshots plus the user changing their mind three times. Standard attention asks every token to look at every other token. That gives you a clean mathematical story and a very expensive bill.
Minimax sparse attention changes the question. Instead of asking, “What should every token attend to?” it first asks, “Which chunks are even worth looking at?” That sounds obvious, which is usually a good sign. Many good systems ideas feel obvious after someone else pays the research bill.
MiniMax says MSA avoids the quadratic explosion by pre-filtering blocks, improves effective context coverage compared with several sparse approaches, and uses a hardware-friendly operator design where KV blocks are read contiguously. At 1M context, the company reports per-token compute at 1/20th of the previous generation, with more than 9x prefill speedup and more than 15x decode speedup.
2.1 Step 1: The Index Branch Scores Before It Computes
The index branch is the cheap scout. It does not run full attention. It scans the terrain and scores blocks of keys and values with a low-cost mechanism. In plain English, it asks: “Which regions of memory look relevant enough to deserve real compute?”
The important trick is block-level selection. Token-level selection can be precise, but it becomes awkward for hardware. Blocks map better to memory movement, caching, and fast attention kernels. You give up some microscopic freedom, then win back practicality.
2.2 Step 2: The Sparse Branch Does The Real Work
After the index branch picks the promising blocks, the sparse branch runs attention over real K/V content. This is not a toy summary of memory. It is still recognizable softmax attention, just not sprayed over the entire context window like a fire hose.
That distinction matters. A sparse model that compresses too aggressively can become cheap in the same way instant coffee is cheap. You saved money, then remembered you have taste buds. MSA tries to keep the useful expressive behavior of attention while reducing wasteful reads.
3. Why GQA Wins When Production Matters
The architecture chatter around M3 quickly turned into comparisons with DeepSeek-style sparse attention families. The most practical design choice is not the flashiest one: MiniMax appears to stick with Grouped Query Attention rather than leaning into more exotic latent-KV designs. A community technical breakdown notes the same pattern: block-level selection, attention on real K/V, and a streamlined path closer to “engineering first” than “architecture maximalism.”
That choice matters because production inference is where good papers go to discover gravity. If your model needs an exotic kernel stack, your theoretical gains may spend months in integration purgatory. GQA gives you a friendlier path into existing ecosystems such as vLLM, SGLang, and FlashAttention-style kernels.
This is a very Karpathy-ish lesson: the best architecture is often the one that lets the rest of the system keep working. You don’t get extra points for cleverness if the deployment team starts aging visibly.
4. MiniMax M3 Vs GPT-5.5 Is The Wrong Question, But A Useful One
The keyword everyone wants is minimax m3 vs gpt-5.5, because procurement teams love a duel. Duels are entertaining. They’re also a poor abstraction for agent systems.
On the benchmark matrix, MiniMax M3 edges GPT-5.5 on SWE Bench Pro and SVG-Bench. GPT-5.5 wins hard on Terminal Bench 2.1, BrowseComp, GDPval rubrics, MCP Atlas, and OSWorld-Verified. The lesson is not “replace GPT-5.5.” The lesson is “route intelligently.”
Use M3 where long context, visual-code generation, repository-scale ingestion, and cost-sensitive agent loops matter. Use GPT-5.5 where terminal execution, strict interactive environments, or established tooling already performs better. Use Opus when a hard systems problem needs more caution than speed. Use Gemini when browsing dominates the job.
This is the post-monolith era. A serious agent stack should look less like a single genius in a chair and more like a small research group with different temperaments, one of whom is very good at SVG and suspiciously cheap.
For B2B teams, that is the actual buying decision. The goal is not to crown a champion model. The goal is to reduce failure rate, latency, and cost across a portfolio of tasks. A model that is second-best everywhere but cheap and stable can be more valuable than the leaderboard king that turns every workflow into a luxury hobby.
5. The Agentic Coding Story Is About Stamina
The most interesting MiniMax M3 demos are not one-shot code snippets. They are long-running tasks. MiniMax reports a 12-hour paper reproduction run where the model produced 18 commits and 23 experimental figures, plus a CUDA kernel optimization task that involved 147 benchmark submissions and 1,959 tool calls, ending in a 9.4x speedup on Hopper FP8 GEMM.
These numbers are fun, but the deeper point is stamina. Real agentic coding is not “write a React component.” It is read the requirement, inspect the project, form a plan, edit files, run tests, break something, fix the thing you broke, forget why you opened that file, recover, then explain the tradeoff to a human who is already late for lunch.
Long context helps when the model can preserve intent through tool noise. It hurts when the model treats old logs as sacred scripture. MiniMax M3’s 1M window is useful only if the attention mechanism continues to select the right evidence under pressure.
So the right evaluation is not just a minimax m3 benchmark table. Give it your ugliest internal task. Run it in a harness. Make tests fail loudly. Pin system instructions. Watch for instruction drift. Cheap tokens are still expensive if they commit nonsense at scale.
6. MiniMax M3 Pricing: Cheap Tokens, Real Caveats
Now to minimax m3 pricing, because architecture is lovely, but someone eventually pays the cloud bill.
MiniMax says the API prices depend on input length. Calls up to 512K input tokens use the standard rate, while calls beyond 512K use a higher long-context rate. The same pricing applies whether thinking mode is on or off, and the API also supports standard and priority service tiers.
The published pricing sheet gives the following direct API rates.
–MiniMax M3 API Pricing
| Access Mode | Input Price | Output Price | Prompt Cache Read | Best Fit |
|---|---|---|---|---|
| M3 API, Up To 512K Tokens | $0.60 / M tokens | $2.40 / M tokens | $0.12 / M tokens | Most coding chats, agent loops, document work |
| M3 API, 512K To 1M Tokens | $1.20 / M tokens | $4.80 / M tokens | $0.24 / M tokens | Full repositories, giant documents, long video or log analysis |
The API table makes MiniMax M3 look aggressively priced, especially for teams running agents that chew through context. The Token Plan is the other wrinkle. MiniMax lists Plus at $20 per month with roughly 1.7B tokens of M3 usage, Max at $50 with roughly 5.1B, and Ultra at $120 with roughly 9.8B, with text, image, speech, and music sharing the same pool.
For individual developers, that $20 tier is the “try this before the CFO notices” option. For companies, API pricing is cleaner, auditable, and easier to route through observability. The practical move is to prototype with the plan, then graduate serious workloads to API with caching, budgets, and per-task cost dashboards.
The hidden line item is not the final answer. It is all the thinking, tool use, retries, and context replay that happen before the answer appears. That is why prompt caching matters. It turns repeated repository context, shared documentation, and stable project instructions from recurring rent into something closer to a prepaid deposit. For agentic products, that can decide whether a feature feels economically sane.
7. MiniMax M3 HuggingFace, Download, And The Open-Weights Question
The minimax m3 huggingface and minimax m3 download searches are predictable. Developers hear “open weights” and immediately want the repo, the license, the quantization notes, and a weekend plan that ends badly for their GPU.
The official Hugging Face organization exists, but at launch the practical question is timing. MiniMax says it will release the technical report and open-source the corresponding weights within 10 days of the June 1 announcement. Until the files, license, model card, and inference recipes are live, treat “open weights” as a near-term commitment rather than a completed deployment path.
This distinction is not pedantry. Open weights without a clear license are a legal puzzle. Open weights without serving recipes are a hobby project. Open weights without eval notes are a trust fall. Wait for the full package before planning private cluster deployment or fine-tuning.
8. What To Build With It First
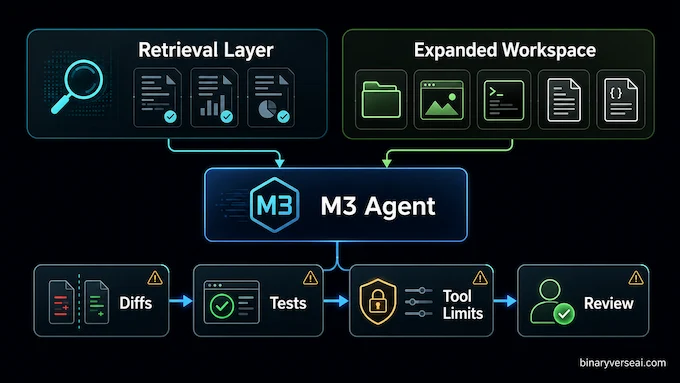
The best first workload for MiniMax M3 is not your most sensitive production path. Start where its design gives you natural leverage.
Use it for repository Q&A across large codebases. Use it for design-to-code tasks where SVG, screenshots, and UI constraints matter. Use it for long document comparison, test-log triage, and agent workflows where context length currently forces ugly summarization hacks.
Avoid giving it silent write access on day one. Put it behind a harness. Require diffs. Run tests. Limit tools. Ask it to explain why it touched each file. A powerful model plus vague permissions is just a fast intern with root access, and nobody needs that particular genre of incident report.
The same goes for long context. Don’t shove 900K tokens into the prompt because you can. Retrieval still matters. Structure still matters. Good context engineering is not dead. It just has a larger apartment now.
A useful pattern is a two-lane setup. Keep a retrieval layer for precision, then give MiniMax M3 the expanded workspace when the task genuinely needs it. That way the model sees the local evidence it must use, plus enough surrounding project memory to avoid making confident nonsense from a keyhole view.
9. Final Verdict: Switch Carefully, Route Aggressively
MiniMax M3 is not magic. That is the compliment.
Magic products ask you to believe. Useful systems ask you to measure. This model gives builders a sharp new tradeoff: long context, credible coding, multimodal input, and unusually attractive economics, all wrapped around a sparse attention design that seems built for deployment rather than conference applause.
The smartest move is not to switch everything. Route. Send massive context ingestion and visual-code work to M3. Keep GPT-5.5 for terminal-heavy loops where it wins. Keep Opus for the brutal backend tasks where you want the model to be boring in the best possible way. Keep Gemini near the browser.
Then run your own evals. Not cute evals. Your evals. The ones with messy repositories, flaky tests, vague tickets, weird PDFs, and business rules that live in someone’s head.
If M3 passes those, don’t just bookmark it. Put it in your agent router, measure cost per completed task, and let the scoreboard be written by production.
Is MiniMax M3 Open Source, And Where Can I Download The Weights?
MiniMax M3 is described as an open-weights model, but the API launched first in late May or early June 2026. The model weights and technical report were scheduled to arrive on HuggingFace and GitHub about 10 days after the initial release. Until the actual files, license, and deployment notes are live, developers should treat MiniMax M3 as API-first with open weights pending.
How Does MiniMax M3 Compare To GPT-5.5 And Claude Opus 4.8?
MiniMax M3 slightly beats GPT-5.5 on SWE-Bench Pro, scoring 59.0% versus 58.6%, and it leads in SVG generation benchmarks. GPT-5.5 remains stronger in terminal execution, while Claude Opus 4.8 is still the heavyweight choice for complex systems logic and high-stakes coding workflows. The best approach is model routing, not blind replacement.
What Is MiniMax Sparse Attention, And How Does It Work?
MiniMax Sparse Attention is the architecture behind MiniMax M3’s 1M-token context window. It splits attention into two stages. First, an Index Branch cheaply scores which key-value blocks matter. Then, a Sparse Branch performs real attention only on those selected blocks. This reduces wasted compute while preserving much of standard attention’s quality.
Is MiniMax M3 Actually Good For Real-World Agentic Coding?
MiniMax M3 looks strong for agentic coding, especially when tasks need long context, fast iteration, and low token cost. Real-world developers should treat it like a hard-working junior developer: useful, fast, and affordable, but not safe without structure. It needs strict planning prompts, clear file boundaries, tests, and review steps to avoid hallucinated edits.
How Much Does The MiniMax M3 API Cost Compared To The Token Plan?
The MiniMax M3 API costs $0.60 per million input tokens and $2.40 per million output tokens for contexts up to 512K tokens, with higher rates above that tier. The Token Plan is different: the Plus plan costs about $20 per month and includes roughly 1.63 to 1.7 billion M3 tokens, making it attractive for heavy individual coding use.