

Introduction
We have a problem in AI right now. We are addicted to scale.
For the last few years, the dominant strategy has been simple: if you want a smarter answer, you build a bigger model. We treat models like GPT-5 or Claude Opus as omniscient gods, asking them to solve everything from quantum physics problems to writing basic Python scripts. This works, but it is incredibly inefficient. It is like hiring a Nobel Prize-winning physicist to calculate your grocery bill. They will get the answer right, but you are wasting their time and your money.
The future isn’t about one giant model doing everything. It is about LLM orchestration. NVIDIA recently dropped a paper that feels like a turning point for this philosophy. They introduced ToolOrchestra and a model called Orchestrator-8B. The claim is bold. They state this tiny 8B parameter model beats GPT-5 on the “Humanity’s Last Exam” (HLE) benchmark. And it does this while being 2.5x more efficient.
This isn’t just an incremental improvement. It is a fundamental shift in how we think about building intelligent systems. We are moving from the era of the “genius monolith” to the era of the “smart manager.”
Table of Contents
1. What is ToolOrchestra? The “Manager” of AI Agents
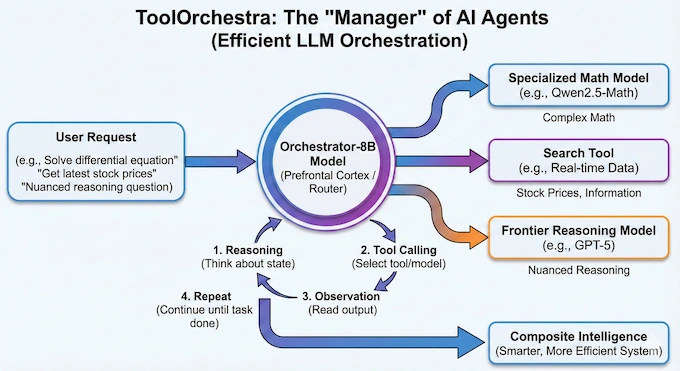
To understand LLM orchestration in this context, you have to stop thinking about the model as the source of truth. Instead, think of the model as a router.
ToolOrchestra is a method for training small models to manage a toolkit. That toolkit isn’t just calculators or search bars. It includes other, specialized AI models. The Orchestrator-8B model acts as the prefrontal cortex. It analyzes a user’s request, breaks it down, and decides which expert to call.
If you ask for the solution to a complex differential equation, the orchestrator routes it to a specialized math model like Qwen2.5-Math. If you ask for the latest stock prices, it calls a search tool. If you ask a nuanced reasoning question, it might escalate the ticket to GPT-5.
This is the essence of efficient LLM orchestration. The orchestrator itself doesn’t need to know the answer. It just needs to know who knows the answer. By decoupling reasoning from knowledge retrieval, NVIDIA has built a system where an 8B model can outperform a frontier model simply by having better management skills.
The architecture is deceptively simple. The system puts the Orchestrator-8B at the center of a loop. It engages in multi-turn reasoning.
- Reasoning: It thinks about the current state.
- Tool Calling: It selects a tool (or model).
- Observation: It reads the output.
- Repeat: It continues until the task is done.
This loop allows for a “composite intelligence” that is smarter than any single part of the system.
2. How Orchestrator-8B Works: Routing, Reasoning, and Rewards
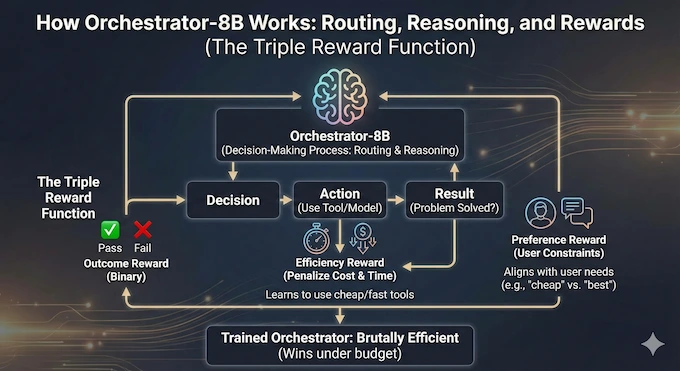
The magic of LLM orchestration lies in the decision-making process. How does an 8B model know when to use a cheap tool versus an expensive model?
Most previous attempts at this used simple prompting. You would tell GPT-4, “You are a router, choose the best tool.” The problem is that LLMs are biased. The paper highlights a fascinating “self-enhancement bias”. When GPT-5 acts as a router, it overwhelmingly prefers to call GPT-5-mini. It likes its own family. When Qwen3-8B is the router, it just hands everything off to GPT-5 because it lacks confidence.
NVIDIA solved this with Reinforcement Learning (RL), specifically an algorithm called Group Relative Policy Optimization (GRPO). They didn’t just train the model to be right. They trained it with a three-part reward function that fundamentally changes the incentives of LLM orchestration.
The Triple Reward Function
- Outcome Reward: Did the system solve the problem? This is binary. Pass or fail.
- Efficiency Reward: This is the game-changer. The model is penalized for spending money and taking too much time. It learns that if it can solve a problem using a free Python script, it shouldn’t pay 5 cents to ask Claude Opus.
- Preference Reward: This aligns the model with user constraints. If a user says “I need this cheap,” the model respects that. If they say “I need the absolute best answer regardless of cost,” it adapts.
This training process produces an Orchestrator-8B that is brutally efficient. It doesn’t just want to win. It wants to win under budget.
3. Benchmark Breakdown: Crushing “Humanity’s Last Exam”
Let’s look at the numbers because they are startling. Humanity’s Last Exam (HLE) is currently one of the hardest benchmarks we have. It consists of PhD-level questions across varying disciplines. It is designed to break models that rely on rote memorization.
On this benchmark, the Orchestrator-8B scores 37.1%. GPT-5, the current heavyweight champion, scores 35.1%. The orchestrator beat the frontier model. But the raw score isn’t even the most impressive part. It achieved this score while being 2.5x more efficient and using only 30% of the cost.
This validates the core hypothesis of LLM orchestration. A team of specialists, managed by a competent leader, beats a single genius working alone.
We see similar dominance on other benchmarks. On FRAMES (a factuality and reasoning benchmark), the Orchestrator hits 76.3%, leaving GPT-5’s 74.0% in the dust. On Tau-Bench (function calling), it scores 80.2% compared to GPT-5’s 77.7%.
These aren’t margin-of-error wins. These are consistent, statistically significant victories that prove LLM orchestration is the superior architecture for agentic tasks.
4. ToolOrchestra vs. Monolithic LLMs: A Cost-Benefit Analysis
The economics of AI are starting to matter. We are moving past the research phase where cost is irrelevant and into the deployment phase where margins are everything. Traditional LLM orchestration often involved daisy-chaining large models. That is expensive. ToolOrchestra flips this by pushing the heavy lifting to the cheapest possible competent entity.
Here is a comparison of how the Orchestrator stacks up against the monolithic approach across different metrics.
ToolOrchestra Performance & Efficiency Comparison
| Model System | HLE Accuracy | FRAMES Accuracy | Cost (Relative) | Latency (Relative) |
|---|---|---|---|---|
| Orchestrator-8B | Low (Baseline) | Fast (Baseline) | ||
| GPT-5 (Monolith) | High (~3.3x) | Slow (~2.5x) | ||
| Claude Opus 4.1 | Very High | Slow | ||
| Qwen3-235B | Medium | Medium |
The data shows a clear trend. The Orchestrator-8B achieves the best trade-off. It is the efficient frontier.
This touches on the “Vibe Lifing” concept we often see discussed in engineering circles. We want agents that can handle real life, booking flights, analyzing data, writing code, without bankrupting us.
The model’s ability to handle user preferences is particularly interesting here. In the paper’s experiments, they tested the model with instructions like “I want to be cost-efficient if possible”. The Orchestrator-8B actually listens. It adjusts its routing logic to favor local search and smaller models over expensive API calls. GPT-5, by contrast, largely ignores these constraints and defaults to its standard behavior. This “listen to the boss” capability is a critical requirement for enterprise LLM orchestration.
5. The “ToolScale” Dataset: How NVIDIA Trained the Brain

You cannot train a manager without scenarios. If you want to teach a model effective LLM orchestration, you need data that shows the consequences of good and bad management decisions. Since this data doesn’t exist in the wild, NVIDIA synthesized it. They built a pipeline called ToolScale.
The process is clever. They didn’t just ask an LLM to “write some conversations.” They simulated full environments.
- Environment Gen: They created database schemas and tool APIs for specific domains like finance or booking systems.
- Task Gen: They generated user intents and “golden” (correct) function calls.
- Verification: This is the key. They executed the calls. If the code didn’t run or the database didn’t update correctly, they threw the data out.
This means the Orchestrator-8B was trained on verifiable ground truth. It knows that if it calls refund_ticket with the wrong ID, it fails. This grounding in executable reality is what separates robust LLM orchestration from models that just hallucinate valid-looking JSON.
They generated thousands of these verified trajectories across 10 domains. This dataset allows the model to learn the mechanics of tool use, not just the syntax.
6. How to Install and Run ToolOrchestra
For the engineers reading this, you are probably wondering how to run this locally. The good news is that because the core brain is an 8B model, the inference requirements are reasonable compared to running a 70B or 400B model.
The paper mentions using H100s for training, but for inference, an 8B model fits comfortably on consumer hardware (like an RTX 3090 or 4090), provided you have the environment set up to handle the tool calls. Here is a simplified setup workflow based on the repository structure.
Note: You will need to adjust the LLM_CALL.py file if you want to swap out the backend providers or use different local endpoints for the specialized models.
The beauty of this architecture is its modularity. You can swap out the “Math Expert” in your LLM orchestration pipeline from Qwen-Math to DeepSeek-Math without retraining the orchestrator. You just change the tool definition.
7. Critical Reception & Community Questions
Whenever a new SOTA claim drops, we have to be skeptical. Is LLM orchestration really a solved problem? One common critique is benchmark saturation. HLE is designed to be hard, so seeing a 37% score reminds us that AI is still failing two-thirds of the time on truly complex tasks. ToolOrchestra is an improvement, but we aren’t at AGI yet.
There is also the question of latency. While the paper claims a 2.5x speedup over monolithic GPT-5, LLM orchestration introduces network overhead. Every time the orchestrator calls an external API or another model, you are adding HTTP request time. For a user, waiting for five different agents to talk to each other can feel sluggish compared to a single token stream. However, the data suggests that because the smaller models generate text so much faster, the total wall-clock time is still lower than waiting for a massive model to “think” and generate.
Another point of discussion is generalization. The paper shows the model generalizes well to unseen tools. This is promising. It suggests the model has learned the logic of LLM orchestration, reading documentation and applying it, rather than just memorizing specific API names.
Finally, we have the “memory” question. Multi-turn agents often get lost in the weeds. By explicitly training on long trajectories (up to 50 turns allowed), Orchestrator-8B seems more robust against losing the plot than standard prompting methods.
8. Conclusion: The Future of Efficient AI Agents
The ToolOrchestra paper is a signal. It tells us that the era of “one model to rule them all” is ending. We are entering the era of the compound AI system.
LLM orchestration is no longer just a buzzword for prompt engineers. It is a trainable, optimizable discipline. By using a small, smart manager to coordinate specialized workers, we can build systems that are smarter, faster, and significantly cheaper than the monoliths.
NVIDIA has provided a blueprint, and a model, that proves you don’t need trillion-parameter scale to solve PhD-level problems. You just need better management.
If you are building agents today, you should stop trying to force your main prompt to do everything. Look at Orchestrator-8B. Look at the LLM orchestration patterns it uses. The future belongs to the modular.
Next Steps for You:
If you want to test this yourself, clone the repository and try swapping the default tools with your own custom APIs. See if the 8B model can figure out how to use your internal company tools without fine-tuning. That is the real test of LLM orchestration.
What is ToolOrchestra and how does it differ from traditional LLM agents?
ToolOrchestra is a novel training method that creates a specialized “manager” model to coordinate various tools and experts. Unlike traditional agents that rely on a single monolithic model (like GPT-5) to do everything, ToolOrchestra delegates tasks to the most efficient expert for the job, such as a math model for equations or a code interpreter for scripts. This reduces bias and improves overall system intelligence.
What is an orchestrator in LLM and why is Orchestrator-8B significant?
n LLM orchestration, an orchestrator is the central decision-maker that plans tasks and routes them to external tools or models.
Orchestrator-8B is significant because it is a small, 8-billion parameter model that outperforms the massive GPT-5 on the “Humanity’s Last Exam” (HLE) benchmark. It proves that smart routing is more effective than raw model size.
How does ToolOrchestra achieve higher accuracy with lower costs?
ToolOrchestra uses a reinforcement learning technique called Group Relative Policy Optimization (GRPO) to balance accuracy, cost, and speed. It learns to route simple queries to cheap, fast models (like Llama-3 8B) and reserves expensive “frontier” models (like GPT-5) only for complex reasoning tasks. This strategy reduced costs to just 30% of a monolithic system in benchmarks.
Can I use ToolOrchestra for commercial applications?
Currently, the Orchestrator-8B model is released under an NVIDIA License for research and development purposes only. While the underlying method of LLM orchestration is applicable to commercial enterprise systems to reduce API costs, this specific model checkpoint is not yet licensed for direct commercial deployment.
How do I install and run ToolOrchestra?
To run ToolOrchestra, you need a Python 3.12 environment and a GPU capable of running an 8B model (like an NVIDIA H100 or potentially smaller consumer cards). You clone the repository, install dependencies via Conda, set up vLLM for serving, and configure your API keys (e.g., Tavily for search). The system is designed to be modular, allowing you to swap out tools easily.