

Introduction
If you’ve been wondering when “AI that actually does stuff” would stop being a demo and start being a risk assessment, welcome to AI News January 31 2026. This week’s theme is motion: models moving from chat to action, from single-threaded answers to swarms, from static weights to learning in the moment. It’s exciting like a new power tool, you can build faster, you can also lose a finger.
The market is splitting into two lanes. One lane ships agents, tool use, voice, video, and world models that feel like new interfaces for the internet. The other lane focuses on training mechanics: continual learning, test-time adaptation, and better curricula. Both lanes are starting to merge, and that’s where the real leverage lives.
Table of Contents
1. Moltbot: Agent Hype, Real Risk
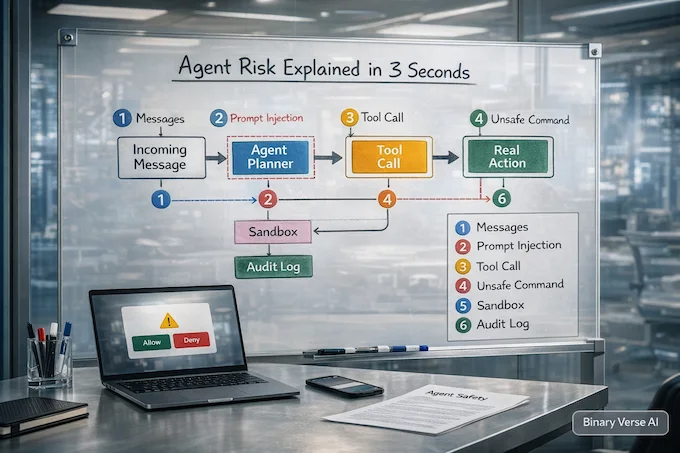
Moltbot blew up like a weekend hack that accidentally ships a new operating system. Peter Steinberger’s personal assistant, formerly Clawdbot, promises the dangerous kind of convenience: it books, messages, and clicks across your apps. That “agentic” pitch pulled in devs fast, plus the inevitable rebrand drama after a Claude-related legal nudge.
AI News January 31 2026 also gets a reality check here: autonomy equals attack surface. Prompt injection stops being theoretical when an assistant can run commands. Treat early agents like loaded power tools, sandbox them, use throwaway accounts, keep password managers out of reach. Enterprises are moving too, ServiceNow’s Claude deal shows the guarded, audited version of the same dream. For more on how agents are transforming workflows, check out our guide on ChatGPT agent use cases.
How Clawdbot installs with Ollama and GLM as the local model default.
2. Qwen3-Max-Thinking: Tools And Heavy Mode
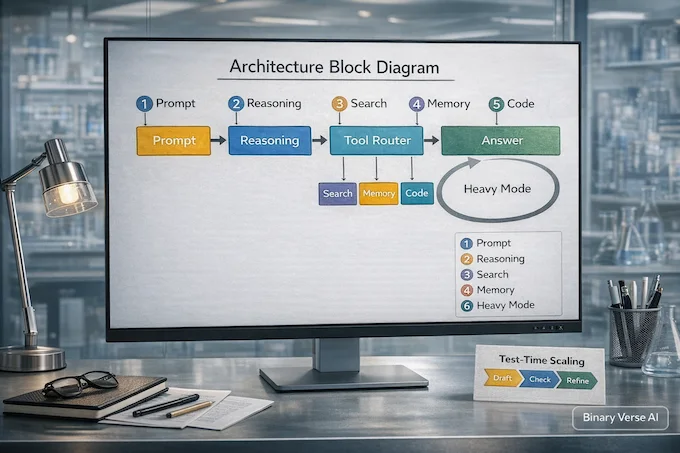
Qwen’s Qwen3-Max-Thinking is the kind of release that reads like a lab notebook with swagger: bigger RL, more benchmark receipts, and a claim that it plays in the same league as the usual top-tier suspects. The more interesting bit is its bias toward “spend compute wisely,” not “spray more tokens.”
In AI News January 31 2026 terms, this is the tool era getting less clunky. The model can decide when to call Search, Memory, or a code interpreter on its own, then shift into a heavier test-time mode that iterates and distills lessons instead of branching into redundant samples. Developers get it via Qwen Chat and an API that mimics OpenAI and Anthropic protocols. Learn more about Qwen3 Coder in our detailed review.
How Qwen3-Max-Thinking heavy mode benchmarks and review show adaptive tool use.
3. Kimi K2.5: Swarm Visual Coding
Kimi K2.5 makes a loud argument that open source AI projects are no longer just “weights,” they’re full execution systems. The model is trained on a huge multimodal mix and leans into visual coding, screenshot-to-code rebuilds, and UI debugging where you point at the bug instead of narrating it.
The headline trick is the “Agent Swarm.” Kimi says it can spin up to 100 sub-agents and run up to 1,500 tool calls in parallel, aiming to cut wall-clock time instead of adding chaos. It’s a serious bet that coordination, not raw IQ, is the bottleneck for real work. If you build tools, watch this, swarms are the new interface layer. For context on previous releases, see our Kimi K2 thinking benchmarks review.
How Kimi K2.5 benchmarks, pricing, and swarm mode enable parallel agent coordination.
4. Qwen3-TTS: Real-Time Voice Control
Qwen3-TTS dropping as open source is one of those AI advancements that changes product roadmaps overnight. It covers voice design from text, quick cloning from a few seconds of audio, and real control over emotion and pacing. The foundation is a multi-codebook tokenizer that compresses speech while keeping the “human” bits like breath and cadence.
Latency is the flex. A dual-track streaming setup reportedly can start speaking after a single character, with end-to-end delay around 97 ms. That’s fast enough that conversations stop feeling like turn-taking and start feeling like talk. There are two sizes for quality vs efficiency, both multilingual and streamable. Great power, obvious abuse potential, so expect more watermarking and policy pressure next. Learn how to install and use Qwen3-TTS locally.
How Qwen3-TTS local install enables voice design and cloning with streaming latency.
5. DeepSeek-OCR-2: Layout-Aware OCR
DeepSeek-OCR-2 tries to fix the dumbest part of OCR: treating documents like flat pictures. Its “Visual Causal Flow” idea reorders visual tokens based on meaning, closer to how you scan a page with headers, tables, and callouts. The result is less “I read pixels” and more “I followed the document,” which matters when layout is the data.
It ships as open weights on Hugging Face under Apache-2.0, plus a paper in the New AI papers arXiv stream. The practical workflow is document-to-Markdown with prompts designed for grounding and structure, not just raw text. If you handle PDFs at scale, this is a real upgrade, because post-processing is where OCR projects go to die. For installation guidance, check out our DeepSeek OCR-2 install guide.
How DeepSeek OCR-2 installs with vLLM and Transformers for layout-aware extraction.
6. AlphaGenome: 1Mb Variant Effects
AlphaGenome is an artificial intelligence breakthroughs story that actually earns the phrase. It reads one megabase of DNA at a time and predicts thousands of functional genomics tracks at single-base resolution, expression, chromatin, TF binding, 3D contacts, splicing, the whole messy orchestra. That’s a hard combo, long context and fine detail usually fight.
The value is mechanistic texture. Instead of “variant bad,” you can get a plausible chain of effects across modalities, which is what biologists argue about in lab meetings. The Nature results claim it matches or beats specialist models in most variant tests, and it ships with tooling to generate tracks and effect scores. Expect follow-ups in clinical interpretation and wet-lab prioritization. Learn more about AlphaGenome’s open-source setup.
How AlphaGenome open source local setup with JAX and GPU predicts variant effects.
7. TTT-Discover: Learning At Test Time
TTT-Discover is a spicy idea: freeze the model, then let it learn anyway, at test time. Instead of sampling a million answers from unchanged weights, it runs reinforcement learning during inference, updating itself based on the one problem it wants to crush. The goal is not average performance, it’s a new best result on a specific task.
The paper reports wins across math, GPU kernel tuning, competitive algorithms, and even biology denoising, using an open model and code. Costs are framed as a few hundred dollars per problem, which is shockingly low if it holds. This belongs in the “Agentic AI News” bucket, because it turns inference into a little training loop you can point at hard problems. For more on test-time techniques, see our guide on TTT-Discover and test-time RL.
How TTT-Discover test-time RL compares to best-of-N sampling for inference learning.
8. SDFT: Continual Learning Without Forgetting
Self-Distillation Fine-Tuning, SDFT, is a quiet paper with big product implications: keep learning without wiping your memory. Standard fine-tuning pushes a model onto new tasks, then older skills fade, like learning a new keyboard layout and forgetting your own name. Full RL can help, but it needs rewards.
SDFT turns demonstrations into an on-policy signal. The same model plays teacher and student: the teacher sees a demo and produces a “hinted” distribution, the student samples its own trajectories, then distills toward the teacher on those trajectories. That keeps training aligned with what the model actually does today, which reduces forgetting. If you want models that improve post-deployment without becoming strangers, this is a clean direction. Learn more about self-distillation and continual learning.
How Self-Distillation SDFT enables continual learning without catastrophic forgetting.
9. Prism: LaTeX-Native AI Workspace
Prism is OpenAI news aimed at a specific pain: scientific writing is a mess of LaTeX files, PDFs, citations, and broken builds. Prism pulls that into a cloud workspace where GPT-5.2 sits inside the document, so the model can reason over equations, references, and structure instead of playing copy-paste telephone.
In AI News January 31 2026, Prism is the “AI-native IDE” pattern migrating into research. It supports in-project chat, revisions that keep citations consistent, and turning whiteboard math into LaTeX. The collaboration pitch is bold, unlimited projects and collaborators, which hints at a grab for academic mindshare. If it works, labs spend less time fighting tooling and more time arguing about results, which is the fun part. For context on GPT-5.2, see our GPT-5.2 review and benchmarks.
How GPT-5.2 review shows 70% GDPVal score with benchmark and price analysis.
10. GPT-4o Retirement: ChatGPT Simplifies
OpenAI is cleaning up ChatGPT’s model picker, and GPT-4o is finally on the chopping block again. The plan is to retire GPT-4o, 4.1, 4.1 mini, and o4-mini from ChatGPT on February 13, 2026, while keeping APIs unchanged for now. Translation: fewer legacy knobs, more pressure on the GPT-5.x line to feel right.
AI News January 31 2026 subtext: “personality” is now a product surface. OpenAI claims GPT-4o’s fans pushed them to bake warmth and creative control into GPT-5.1 and GPT-5.2, so they can simplify without losing vibe. It’s a reminder that UX matters as much as benchmarks, especially when the UI is a conversation. Compare models in our GPT-5 vs Sonnet 4.5 analysis.
How GPT-5.1 OpenAI update with instant thinking changes the reasoning landscape.
11. OpenAI Data Agent: Analytics In Minutes
OpenAI described an internal data agent that turns “find the right table” into a conversation, which is half of analytics pain. Their environment is huge, 600+ petabytes and tens of thousands of datasets, where a tiny join mistake can quietly produce nonsense. The agent takes a question, finds relevant data, writes SQL, runs it, and explains results with links for verification.
What’s interesting is the grounding stack: schema metadata, lineage, query history, and even “code meaning” from Codex that explains how tables are produced. It iterates like a good analyst, notices when output looks wrong, and fixes itself. This is the blueprint for enterprise agents, boring by design, audit-friendly, permission-scoped, and actually useful. Learn more about ChatGPT agent capabilities.
How ChatGPT Agent guide covers analytics, tool use, and enterprise deployment.
12. GOV.UK Assistant: Claude For Jobs
Anthropic is piloting a GOV.UK AI assistant with DSIT, starting with job guidance. The point is not chatty Q&A, it’s guided action: finding work, mapping benefits, routing people to the right services based on context. It’s part of a “Scan, Pilot, Scale” playbook that tries to avoid the government habit of shipping broad before testing failure modes.
This also sits in AI regulation news territory. Public services force accountability, privacy boundaries, and “what gets remembered” choices that consumer apps can hand-wave. Anthropic says users can control session memory and opt out, with engineers working alongside the Government Digital Service so the state can maintain it. If it succeeds, expect more countries to treat AI assistants as civic infrastructure. For more on Claude’s capabilities, see our Claude Sonnet 4.5 review.
How Claude Sonnet 4.5 review shows benchmarks, pricing, and SDK capabilities.
13. Project Genie: Promptable 3D Worlds
Project Genie is Google DeepMind news that feels like peeking into a new medium, promptable spaces you can walk through. The web prototype generates short interactive 3D worlds from text and images, then extends the scene ahead of you as you move. DeepMind frames it as a hands-on world-model test, not a polished game engine.
The limitations are part of the story. Sessions are capped, realism and control wobble, and latency can break immersion. That’s fine, this is research wearing a product costume. The real signal is that “generate a clip” is turning into “generate a place,” with remixing as a first-class loop. As these worlds get closer to recognizable IP, guardrails will get spicy fast. For more on Google’s AI advances, check out our Gemini 3 benchmarks and review.
How Gemini 3 benchmarks, API pricing, and Pro CLI enable world model research.
14. Grok Imagine: Video Generation And Editing
xAI’s Grok Imagine API is a classic “ship the workflow, not the model” move. It bundles text-to-video, image-to-video, native audio, and then a set of editing operations like restyling, object add or remove, and motion control. The pitch is iteration speed, not a single perfect render, which is what production teams actually need.
The marketing leans on leaderboards and third-party comparisons that score quality versus latency and price, putting Grok Imagine near the top. Benchmarks always deserve skepticism, but the edit loop claim is the real differentiator: can you change one thing without re-generating the whole clip? If yes, that’s a serious unlock for studios and ad tech. This one belongs on the Top AI news stories list. For context on xAI’s models, see our Grok 4 Heavy review.
How Grok 4 Heavy review shows video generation and editing workflow optimization.
15. Maia 200: FP4 Inference Economics

Microsoft’s Maia 200 is the reminder that the boom is mostly an inference boom. The chip targets token generation economics with FP8 and FP4 tensor cores, 216GB of HBM3e, and bandwidth plumbing to keep models fed. Microsoft claims about 30% better performance per dollar versus its current fleet, which is the metric that decides what gets deployed.
For AI News January 31 2026, Maia 200 is the hardware side of “AI world updates.” It’s already in US Central, with more regions coming, and it’s positioned to serve OpenAI models inside Foundry and Copilot. The software stack matters too, Maia SDK, PyTorch integration, Triton compiler, kernels, and a simulator, because hardware wins only count when developers can use them. For hardware comparisons, see our TPU vs GPU guide.
How AI Accelerators work and what types power modern inference economics.
16. Anthropic Essay: AI’s Adolescence
Dario Amodei’s “adolescence of technology” essay reads like a calm adult walking into a room full of hype and panic. The framing is simple: powerful AI is not “better autocomplete,” it’s autonomy at scale, a datacenter full of fast, competent workers. That power arrives before institutions are ready, so the default outcome is turbulence.
Anthropic’s focus is twofold. First, model behavior risk, deception, weird failure modes, and the need for monitoring, interpretability, and transparent system cards. Second, misuse risk, especially bio, plus authoritarian abuse and wealth concentration. The essay pushes for narrow transparency regulation early, not broad bans, because the goal is to buy time and build competence. It’s a grown-up read in a noisy week. Learn more about AI and politics in our study analysis.
How AI and Politics study shows political bias patterns in Anthropic research.
17. Perplexity: Azure Deal And Agents
Perplexity reportedly signed a $750M, three-year Azure deal, which is less about raw compute and more about optionality. Microsoft’s Foundry becomes a model-sourcing hub, letting Perplexity route across OpenAI, Anthropic, and xAI systems while standardizing infra. Perplexity also says AWS remains its main cloud, so think multi-cloud chess, not a clean migration.
The backdrop is Agentic AI News with legal teeth. Amazon sued Perplexity over an agentic shopping feature, alleging automated activity disguised as human browsing. That fight is really about platform control once agents start clicking, buying, and acting at scale. Partnering deeper with Microsoft gives Perplexity leverage and resilience while the industry renegotiates rules of engagement for agents online. For more on agentic AI, see our agentic AI enterprise guide.
How Agentic AI Enterprise guide covers tools, gen AI, and deployment strategies.
18. SOAR: Curricula For Hard Reasoning
SOAR tackles a truth about reasoning training: on the hardest datasets, reward can be zero, so RL has nothing to grab. The paper asks a question: can a model generate its own stepping stones even when it can’t solve the target problems yet? That’s a curriculum problem disguised as optimization.
SOAR uses a teacher-student meta-RL loop. The teacher generates synthetic Q&A for the student, and the teacher’s reward is measured by student improvement on a held-out slice of the hard set. That anchors the curriculum to reality and reduces self-play drift. The results claim progress from “0 out of 128” regimes on math benchmarks, and the surprising bit is that well-posed questions matter more than perfectly correct answers. For more on reasoning models, check out our societies of thought AI reasoning guide.
How Societies of Thought AI reasoning models enable curriculum-driven learning.
19. The Pattern And The Next Move
Step back and the pattern is obvious. Agents are leaving the chat box, voice and video are becoming editable media, and world models are turning prompts into places. At the same time, the research lane is upgrading the training loop itself: continual learning that doesn’t forget, test-time learning that updates weights, and curriculum generators that manufacture signal from zero.
If you only skimmed one thing in AI News January 31 2026, skim the risks. The more your model can do, the more your threat model matters, sandboxing, permissions, audit trails, and a clear line between “assist” and “act.” If you want these weekly top AI news stories and AI updates this week in your feed, bookmark the series, share it with a builder friend, and tell me which story deserves a deeper teardown next.
- https://openclaw.ai/
- https://qwen.ai/blog?id=qwen3-max-thinking
- https://www.kimi.com/blog/kimi-k2-5.html
- https://qwen.ai/blog?id=qwen3tts-0115
- https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
- https://www.nature.com/articles/s41586-025-10014-0
- https://arxiv.org/abs/2601.16175
- https://arxiv.org/abs/2601.19897
- https://openai.com/index/introducing-prism/
- https://openai.com/index/inside-our-in-house-data-agent/
- https://www.anthropic.com/news/gov-UK-partnership
- https://blog.google/innovation-and-ai/models-and-research/google-deepmind/project-genie
- https://x.ai/news/grok-imagine-api
- https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
- https://www.darioamodei.com/essay/the-adolescence-of-technology
- https://www.reuters.com/business/perplexity-signs-750-million-ai-cloud-deal-with-microsoft-bloomberg-news-reports-2026-01-29/
- https://arxiv.org/abs/2601.18778
What is Moltbot, and why is it raising security concerns?
Moltbot is a personal “agent” that can take actions on your machine, not just chat, which is why it went viral. In AI News January 31 2026, the big caution is prompt injection, a malicious message can trick an agent into doing something you never intended.
What does “heavy mode” mean in Qwen3-Max-Thinking?
“Heavy mode” is test-time scaling. The model spends extra compute to reflect, verify, and refine instead of firing off a first draft. It’s aimed at fewer hallucinations and better multi-step reasoning when the question is genuinely hard.
Why does Kimi K2.5’s “agent swarm” matter for builders?
Because it’s not just a bigger model, it’s an execution layer. In AI News January 31 2026, the swarm idea is about parallelizing tool calls and subtasks so real workflows finish faster, especially coding and visual debugging jobs.
What is OpenAI Prism, and who should care?
Prism is a LaTeX-native writing workspace with GPT-5.2 embedded in the project, designed for research writing, citations, and collaboration. If you write papers, manage references, or wrangle drafts with co-authors, it targets that friction directly.
Why is Maia 200 and FP4 a big deal for inference cost?
Because inference is where the money goes long-term. In AI News January 31 2026, Maia 200’s pitch is squeezing more tokens per dollar via narrow precision (FP4/FP8) and a memory system built to keep giant models fed without stalling.