

Introduction
Every GPU generation comes with a familiar temptation, stare at the peak numbers, then mentally multiply by “how many can I buy.” It is a comforting game because it avoids the messy part, the part where real systems lose time, lose watts, and quietly lose money.
NVIDIA Rubin is a reminder that the messy part is now the product.
The pitch is simple enough to fit on a keynote slide. Treat the rack as the unit of compute. Design compute, networking, security, and operations as one coordinated stack. Ship it as a repeatable building block. The rest of the industry is already drifting this way under the banner of “AI factories,” always-on infrastructure that converts power and data into tokens, day after day.
NVIDIA Rubin was announced on January 5, 2026, with attention-grabbing claims about token cost and MoE training efficiency. You can debate the multipliers. The direction is harder to argue with. When models turn more agentic, more long-context, and more mixture-of-experts, performance stops being a GPU spec and starts being a system property.
Table of Contents
1. NVIDIA Rubin Explained: What Actually Changed
Here is the one-paragraph version. NVIDIA Rubin takes the components that used to be loosely bolted together, the host CPU, the scale-up fabric, the scale-out NIC, the infrastructure DPU, the Ethernet switching layer, and designs them as a single platform meant to behave like one machine at rack scale. It is less “buy GPUs” and more “buy a production unit.”
To make that concrete, keep this cheat sheet nearby.
NVIDIA Rubin: What Changed and Why It Matters
| What Changed | Why It Matters | Where You Feel It |
|---|---|---|
| Rack-scale integration, not just server builds | Fewer hidden bottlenecks between parts | More stable throughput and less topology drama |
| NVLink 6 scale-up fabric | Communication-heavy workloads stop idling GPUs | Better MoE training, smoother interactive inference |
| Low-precision math plus faster memory | Tokens get cheaper to generate | Higher throughput per watt and lower serving cost |
| Dedicated infrastructure offload tier | Ops and security stop stealing host cycles | More predictable multi-tenant behavior |
| Security expands from device to rack | Trust spans CPU, GPU, and interconnect | Easier deployment for regulated and shared workloads |
If you only remember one thing, remember this: NVIDIA Rubin is a system design bet, not a single chip launch.
2. Why NVIDIA Calls Rubin “One AI Supercomputer”
The easiest way to decode the phrase “one AI supercomputer” is to ask what the scheduler’s natural unit should be. In the classic world, it is the 8-GPU server, and then you stitch servers together with a network, plus a lot of careful parallelism choices to survive latency.
NVIDIA Rubin is aiming higher. The intended unit is the rack-scale system, specifically NVIDIA Vera Rubin NVL72. Inside that rack, the scale-up network is dense and uniform, so your 72 GPUs are peers in one domain. If you have ever watched a job wobble because the topology is uneven, you already understand the appeal.
There is also an operations angle. When the rack is the product, you can optimize serviceability, telemetry, and cooling as baseline features. NVIDIA Rubin is quietly saying, ops is not an afterthought anymore.
3. The Six Chips, Clearly Explained

The marketing line is “six new chips.” The useful interpretation is “six roles that used to fight each other.”
3.1 The Six Roles In One List
- NVIDIA Vera CPU: the data-movement and orchestration engine.
- Rubin GPU: the execution engine for transformer-era compute and memory traffic.
- NVLink 6 Switch: the scale-up fabric that unifies 72 GPUs.
- ConnectX-9 SuperNIC: the scale-out endpoint for predictable cross-rack traffic.
- BlueField-4 DPU: the infrastructure processor for networking, storage, and security.
- Spectrum-6 Ethernet: the switch silicon, with Spectrum-X Ethernet Photonics targeting power and uptime.
If you like metaphors, the GPUs make tokens. The rest of the stack makes token production repeatable.
4. Vera CPU: Why NVIDIA Built A CPU For Agentic Work
The GPU still does the heavy lifting, but inference is no longer “one forward pass and done.” Tool use, retries, longer contexts, and multi-step reasoning add control flow and state. That is where the NVIDIA Vera CPU earns its keep.
4.1 Coherent Memory Makes The CPU Relevant Again
High-bandwidth CPU to GPU coherence (via NVLink-C2C) means the system can treat CPU memory as a real extension of the working set. That matters when you are juggling large contexts and many concurrent sessions and you do not want every state transition to bounce through slow paths.
This is one of those shifts that sounds abstract until you run a busy serving fleet. Then it feels obvious.
4.2 Efficiency Is Part Of The Token Bill
NVIDIA Rubin is sold on tokens per watt, not just tokens per second. A CPU that moves data efficiently and burns less power improves economics even when it never appears in a benchmark headline. It reduces the parasitic energy spent on everything that is not generating tokens.
5. Rubin GPU: NVFP4, Transformer Engine, And The New Cost Curve
Rubin GPU is where the familiar GPU story lives, more compute density, better low-precision math, more bandwidth. The difference is that NVIDIA Rubin frames those improvements as cost structure, not bragging rights.
5.1 NVFP4 And Transformer Engine, Practical Version
NVFP4 and the third-generation Transformer Engine are about packing more useful work into each joule without collapsing accuracy. When it works, you either get more tokens at the same latency target, or the same tokens at lower energy cost.
Either way, inference economics shift.
5.2 HBM4 Turns Long Context Into A Default
Long context is mostly a memory story. Moving to HBM4 is a direct attack on the real bottleneck for large contexts, memory traffic and attention overhead. When memory bandwidth rises, interactive serving stops feeling like a knife fight for every millisecond.
5.3 Communication Is Now Part Of “GPU Performance”
Modern large models are distributed systems. Your “GPU speed” is inseparable from how fast devices share activations, gradients, and expert dispatch. This is why NVIDIA Rubin ships the GPU together with a scale-up story instead of treating interconnect as an accessory.
6. NVLink 6 Switch: 72 GPUs As One Performance Domain
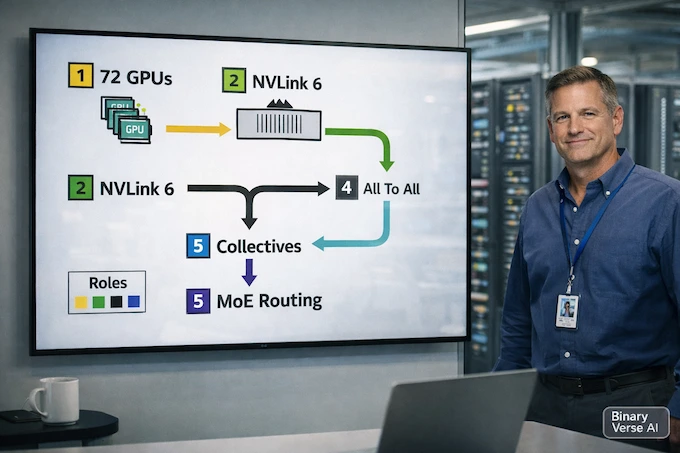
NVLink 6 Switch is the glue that makes the rack idea real. The goal is uniform, all-to-all behavior across the rack, so collectives and MoE routing do not fall off a topology cliff.
The practical payoff is simple. Higher utilization, less variance, and fewer heroic workarounds in your parallelism strategy. In the NVIDIA Rubin world, communication is not overhead. It is the workload.
7. ConnectX-9 SuperNIC: The Scale-Out Edge For MoE Bursts
Inside the rack, NVLink handles tight coupling. Outside the rack, the problems are congestion, tail latency, fairness across tenants, and synchronized bursts that hit the fabric like a wave.
ConnectX-9 SuperNIC is positioned as the endpoint that makes Ethernet behave like a serious AI fabric. The key move is controlling traffic at the edge, before the switches turn into queueing museums.
MoE is the obvious beneficiary. Expert dispatch is bursty by nature, and bursty traffic needs pacing, shaping, and isolation if you want predictable job times.
8. BlueField-4 DPU Plus “Inference Context Memory Storage”
BlueField-4 DPU is the infrastructure processor in NVIDIA Rubin, and it might be the most quietly radical piece. It says the control plane deserves dedicated silicon, because shared hosts make ops fragile.
8.1 Offload Is A Reliability Strategy
If your host CPUs are running the workload and also running the infrastructure that keeps the cluster healthy, you get contention and weird failure modes. Offloading networking, storage paths, encryption, telemetry, and policy enforcement onto BlueField-4 DPU separates concerns. It also makes performance more deterministic.
8.2 KV Cache Reuse Becomes Shared Infrastructure
The “Inference Context Memory Storage” idea is KV cache as a first-class resource. Long-context, multi-turn systems keep rebuilding state they already had. Persisting and reusing that context across the fleet can raise throughput and reduce latency, especially for agentic sessions that revisit the same tools, schemas, and retrieved context.
That is AI factory thinking in hardware form.
9. Spectrum-6 And Spectrum-X Ethernet Photonics: Power, Uptime, Scale-Across
At cluster scale, a network is a reliability problem as much as a bandwidth problem. Spectrum-6 Ethernet is the switch silicon. Spectrum-X Ethernet Photonics is the attempt to reduce the power and failure tax of optics through tighter integration.
If you operate big fabrics, you already know why this matters. Transceivers fail. Retimers burn watts. Replace enough of them and “network uptime” becomes a first-class metric.
There is also the scale-across angle. Multi-site AI factories only work if the fabric behaves predictably over distance. Spectrum-X positions itself as the Ethernet path for that future, where a cluster can span more than one building.
10. Security And Uptime: Confidential Computing Plus RAS
NVIDIA Rubin invests heavily in the unglamorous parts, the parts that decide whether a platform survives production.
Rack-scale confidential computing expands trust across CPU, GPU, and interconnect, which is the difference between “we can run this model in the cloud” and “legal says no.” The RAS engine and rack-level resiliency features exist to protect goodput, the amount of useful work completed over time, not just raw speed.
Fast restarts are nice. Not needing restarts is better.
11. Rubin Vs Blackwell: Interpreting The 10x And 4x Claims

The headline multipliers are workload-specific and end-to-end. You will only see dramatic gains when your old bottlenecks match the ones NVIDIA Rubin targets, communication, long-context memory pressure, multi-tenant interference, and operational overhead.
Use this checklist to keep yourself honest.
NVIDIA Rubin: Marketing Claims vs What to Verify
| Claim You Hear | What It Usually Means | What To Verify In Real Benchmarks |
|---|---|---|
| “Up to 10x lower cost per token” | Higher sustained throughput at interactive latencies | Tokens per second at fixed latency, energy per token, cache reuse rates |
| “4x fewer GPUs for 10T MoE training” | Better scale-up efficiency and less cluster sprawl | All-to-all utilization, expert dispatch overhead, checkpoint behavior |
| “5x better network power efficiency and uptime” | Fewer optical parts and lower signaling overhead | Power per delivered Gb/s, failure rates, effective bandwidth under load |
| “Rack behaves like one domain” | Uniform topology and faster collectives | NCCL collectives, MoE dispatch time, tail latency under contention |
The punchline is boring, which is good. NVIDIA Rubin raises the ceiling. It also raises the floor for predictable performance. If your pipeline is bottlenecked on data prep, storage, or orchestration debt, you will not get 10x. If you are MoE-heavy, long-context heavy, or running shared clusters with strict latency targets, the platform is designed to hit those pain points directly.
12. When Rubin Ships, Who Gets It First, And What To Watch
The stated timeline is partner availability in the second half of 2026. Early deployments are expected from large cloud providers and AI labs, because rack-scale systems match how they buy infrastructure and how they measure success.
If you are watching from the outside, focus on three signals.
12.1 End-To-End Benchmarks, Not Peak Numbers
Look for interactive inference at fixed latency, MoE training throughput with real expert routing, and cost per token once power is included. That is where NVIDIA Rubin either delivers or it does not.
12.2 Software Maturity
Rack-scale hardware only pays off when the software stack can actually use it. Watch how quickly frameworks and serving stacks standardize around best practices for sharding, collectives, cache reuse, and failure handling. Hardware can ship before habits catch up.
12.3 Power, Cooling, And Pricing Reality
Power and cooling are now the constraint. Watch how NVIDIA Rubin racks are deployed, how often they need service, and what the real cost per token looks like when facilities are part of the bill.
NVIDIA Rubin is a bet that the next era of AI progress is about predictable token production at industrial scale. If you build models, run inference fleets, or design data centers, learn the stack now, and pressure-test it against your own bottlenecks.
Want a follow-up tuned to your world? Leave a comment with your workload, MoE training, long-context serving, multi-tenant inference, or something else entirely, and subscribe so you do not miss the next deep dive.
What is NVIDIA Rubin?
NVIDIA Rubin is a rack-scale AI platform, not just a GPU. It’s a coordinated system design built from six chips that target the real bottlenecks in production AI: moving data, moving tokens, moving state, and keeping utilization high under messy workloads.
What are the six chips in the NVIDIA Rubin platform?
The six chips are: NVIDIA Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet (plus the broader Spectrum-X Ethernet Photonics systems). Together they’re designed to behave like one rack-scale machine.
How is Rubin different from Blackwell?
The headline change is system-level co-design. NVIDIA Rubin pushes more scale-up bandwidth (NVLink 6), leans harder into low-precision inference economics (NVFP4 with a newer Transformer Engine), expands rack-scale security (confidential computing), strengthens reliability/serviceability, and adds infrastructure concepts like shared inference context (KV cache reuse) as a first-class layer.
Does Rubin really cut inference cost by 10x?
Treat “10x” as a best-case claim tied to specific operating points. The real question is whether your deployment can actually reach the conditions that unlock it: long-context or agentic patterns, high utilization, the right precision format, and a setup that avoids turning networking, memory, or orchestration into the new ceiling.
Will there be a consumer RTX Rubin (like an RTX 6090)?
Right now, NVIDIA Rubin is presented as data-center infrastructure first. Consumer GPUs often inherit ideas from data-center generations later, but there’s no guaranteed “Rubin-to-RTX” mapping until NVIDIA publishes an explicit GeForce roadmap.