

Qwen AgentWorld is not another chatbot trying to sound smarter in a browser tab. It is a model trained to predict what an environment will do after an AI agent takes an action. That difference sounds small until you remember what agents actually do. They click buttons, run shell commands, call APIs, edit code, search the web, and sometimes confidently step on rakes.
The Qwen-AgentWorld technical report and official Qwen release frame it as a native language world model for general agents. In plain English, Qwen AgentWorld tries to answer: “If the agent does this, what happens next?”
That makes it less like a talking assistant and more like a simulator for agent training, testing, and planning.
Table of Contents
1. What Is Qwen AgentWorld?
Qwen AgentWorld is a language world model. A normal LLM predicts the next useful text response. A language world model predicts the next environment observation after an action.
If an agent runs pip install torch, the model should predict a plausible terminal response. If an agent clicks a button in a web app, it should predict the updated DOM or accessibility tree. If an agent calls a tool through MCP, it should return a consistent API-style response.
Qwen AgentWorld Key Points Explained
| Key Point | What It Means |
|---|---|
| Core idea | Predict the next environment state from current context plus agent action |
| Model type | Language world model, not a general chatbot first |
| Main release | Qwen-AgentWorld-35B-A3B open weights |
| Larger research model | Qwen-AgentWorld-397B-A17B reported in benchmark results |
| Domains | MCP, Search, Terminal, SWE, Web, OS, Android |
| Training data | More than 10 million real environment interaction trajectories |
| Benchmark | AgentWorldBench, with real observations as references |
| Open resources | GitHub, Hugging Face model, and AgentWorldBench |
The useful comparison is simple.
- Normal LLM: “What should I say or do?”
- Qwen AgentWorld: “If the agent does that, what will the world return?”
That is the heart of the whole project.
2. Why World Models Vs LLMs Matters For Agents
The phrase world models vs LLMs can get abstract fast, so keep it practical. Agents do not live inside pure text. They live inside tool loops. A coding agent runs tests. A browser agent clicks through forms. A research agent calls search and extraction tools. A desktop agent manipulates files and windows.
Most agent systems focus on policy, meaning the model chooses what action to take. Qwen AgentWorld focuses on the other half, environment dynamics. Given a state and an action, what state follows?
That matters because good planning depends on consequence prediction. Humans do this constantly. Before deleting a file, we imagine what breaks. Before running a migration, we imagine the database crying quietly in the corner. An llm world model gives agents a rough version of that ability.
Qwen AgentWorld AgentWorldBench Scores by Domain
| Model / System | MCP | Search | Terminal | SWE | Android | Web | OS | Overall |
|---|---|---|---|---|---|---|---|---|
| Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
| GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
| Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
| Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
| Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
| Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
These are AgentWorldBench scores, not general intelligence scores. That distinction matters.
3. How The Seven-Domain Language World Model Works
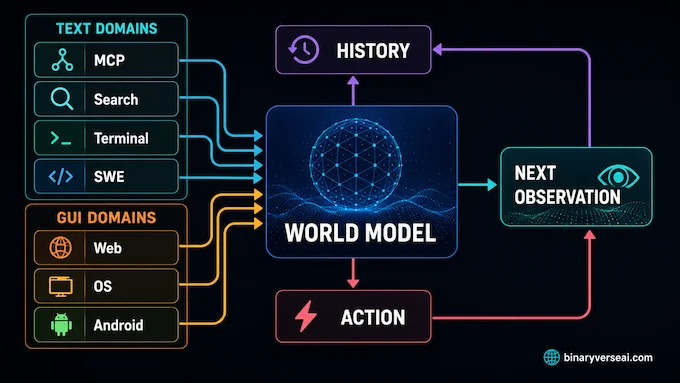
Qwen AgentWorld covers seven agent environments in one model.
The text-heavy domains are MCP, Search, Terminal, and SWE. These involve tool calls, search results, shell outputs, code changes, test failures, file state, and build behavior.
The GUI domains are Web, OS, and Android. The important detail is that the model does not mainly simulate raw pixels. For GUI tasks, observations are represented as renderable code or structured UI text, such as accessibility trees, HTML, XML, and Android UI hierarchy markup.
That makes the phrase vision language world model slightly tricky. Qwen AgentWorld is relevant to browser, desktop, and mobile UI environments, but its core method is text-based world modeling of visual interfaces. If someone searches for planning with reasoning using vision language world model, this is close to the neighborhood, but the technical nuance is important. It predicts structured interface states, not video frames.
The loop is clean:
- The agent has an interaction history.
- The agent takes an action.
- The model predicts the next observation.
- The agent or trainer uses that prediction for evaluation, planning, or reinforcement learning.
That is world model AI in a form language agents can actually use.
4. How Qwen AgentWorld Was Trained
The training recipe has a nice phrase from Qwen: CPT injects, SFT activates, RL sharpens.
CPT, or continual pre-training, injects environment knowledge. This stage teaches broad dynamics from real interaction traces and domain-specific knowledge. The paper mentions sources across agent infrastructure, open traces, in-house trajectories, and specialized corpora.
SFT, or supervised fine-tuning, activates next-state prediction. The model learns to reason through environment changes and express that reasoning in structured prediction tasks.
RL, or reinforcement learning, sharpens simulation fidelity. The reward combines rubric-style judging with rule-based checks where exact correctness can be measured.
The key design choice is that environment modeling is not bolted on after the fact. The model is trained as a generative world model from the beginning of the pipeline. That is why calling it a generative world model is fair, as long as we remember what it generates: environment observations, not fantasy landscapes.
5. What Is AgentWorldBench?
AgentWorldBench is the evaluation suite released with Qwen AgentWorld. It is designed to measure how well a model predicts environment observations.
The benchmark contains 2,170 turn-level samples across seven domains. Those samples come from real environment interactions generated from frontier model trajectories on nine established benchmarks, including Tool Decathlon, Terminal-Bench, and OSWorld-Verified.
Each predicted observation is judged across five dimensions:
- Format
- Factuality
- Consistency
- Realism
- Quality
This is not a chatbot leaderboard. It does not ask, “Which model writes the best poem about Kubernetes?” It asks whether the model can predict a believable and reference-grounded environment response after an action.
That is why the benchmark is both interesting and narrow. It measures simulation quality. It does not prove that one model is better at everything.
6. Did Qwen AgentWorld Beat GPT-5.4 And Claude?
The headline version is spicy: the 397B-A17B Qwen AgentWorld model reports the highest overall AgentWorldBench score, 58.71, above GPT-5.4 at 58.25 and Claude Opus 4.8 at 56.59.
The careful version is better.
On this benchmark, for this task, the larger Qwen AgentWorld model performs extremely well. It is especially strong in domains such as Terminal and SWE, where predicting command output, code edits, test results, and build behavior requires detailed causal tracking.
That does not mean it is generally better than GPT-5.4 or Claude Opus 4.8 at chat, creative writing, open-ended coding, reasoning, or multimodal understanding. The benchmark is about environment simulation.
The GUI results also deserve nuance. Frontier proprietary models remain strong in Web, Android, and OS-style domains. That makes sense. Many frontier models have deep multimodal and UI grounding. Qwen AgentWorld’s edge is not that it sees everything better. Its edge is that it is trained directly for next-state prediction.
7. Why Not Just Use Real Environments?
Real environments are still the gold standard. If you want to know whether a command works, run it. If you want to know whether a web automation flow succeeds, execute it in the browser.
So why build a simulator?
Because real environments are expensive, slow, brittle, risky, and hard to control. A simulator can create rare failures on demand. It can produce paginated tool responses, intermittent API errors, broken dependencies, partial results, fictional search worlds, and adversarial edge cases.
The paper’s strongest argument is not cost reduction. It is controllability.
In MCP experiments, uncontrolled simulated RL did little. Controlled simulation improved Tool Decathlon and MCPMark, with MCPMark rising by 12.3 points. In WideSearch, controlled fictional-world simulation improved F1 by Item from 34.02 to 50.31 for the 35B agent setup.
That is the useful lesson. Simulation is not magic because it is cheaper. It is useful because it can make agents practice situations that real systems rarely expose cleanly.
8. What Developers Can Actually Use It For
Developers should think of Qwen AgentWorld as an environment simulator for agent research, not as a drop-in ChatGPT replacement.
Useful cases include:
- Mocking terminal, tool, or API responses
- Testing agent rollouts before real execution
- Creating harder evaluation cases
- Training agents on controlled failures
- Simulating browser or app state changes through structured UI text
- Studying whether agents can plan by predicting next states
- Generating synthetic trajectories for research
If you searched for Qwen AgentWorld app, the most relevant public path today is the official demo-style experience linked from the Qwen materials, plus the open model and benchmark. If you searched Qwen AgentWorld reddit, the useful skepticism is also fair: a learned simulator can drift when tools, APIs, packages, websites, or operating systems change.
That caveat is not a footnote. Any simulated result still needs real validation before production use.
9. Qwen AgentWorld 35B-A3B Vs 397B-A17B
There are two model scales to keep separate.
Qwen-AgentWorld-35B-A3B is the practical open-weight release. The official repository describes it as a mixture-of-experts model with 35B total parameters, 3B active parameters, and a 256K context window. It can be served through SGLang or vLLM, according to the GitHub quickstart.
Qwen-AgentWorld-397B-A17B is the larger research model reported in the benchmark tables. It posts the strongest overall AgentWorldBench result, but ordinary users should not assume it is the model they can casually run locally.
This distinction matters for expectations. The 35B-A3B model is the one developers can realistically inspect, deploy, and test. The 397B-A17B model is the one driving the biggest benchmark headline.
Both are interesting. Only one is currently the practical playground for most builders.
10. The Big Picture: Predict Before You Act
Qwen AgentWorld matters because it shifts the agent conversation from action alone to consequence prediction.
For years, much of the AI agent discussion has sounded like this: how do we make the agent choose better actions? Qwen AgentWorld asks the companion question: how do we make the agent understand what its actions will cause?
That is a deeper framing. A good agent should not just pick commands. It should anticipate outcomes, notice likely failures, and plan around the world it is about to disturb.
The research is early. The benchmark is specific. Simulators can drift. Real execution still matters. But the direction is compelling.
If the next wave of agents is going to operate browsers, terminals, APIs, apps, and full operating systems with less chaos, they will need more than bigger policies. They will need better internal models of the environments they touch.
That is why Qwen AgentWorld is worth watching. It is not trying to be the loudest chatbot in the room. It is trying to teach agents the old engineering lesson: think through what happens next.
For more technical AI breakdowns that separate real progress from leaderboard confetti, follow Binary Verse AI.
What is Qwen AgentWorld?
Qwen AgentWorld is a language world model from the Qwen team that simulates AI agent environments. Instead of only deciding what an agent should say or do, it predicts what the environment will return after an action, such as a terminal output, API response, search result, code error, or UI state.
Is Qwen AgentWorld an LLM or a world model?
It is built from language-model technology, but its purpose is world modeling. A normal LLM predicts text responses; Qwen AgentWorld predicts environment observations for AI agents. That is why it is better described as a language world model.
Will world models replace LLMs?
No. World models are more likely to complement LLMs than replace them. In an AI-agent system, one model may choose actions while a world model predicts what could happen next. Qwen AgentWorld is important because it shows how world prediction can become part of agent training and planning.
Is Qwen AgentWorld good for coding?
It may be useful for coding-agent workflows because it can simulate terminal output, software-engineering tool results, code edits, test failures, and build errors. But it should not be judged like a normal coding chatbot. Its main role is predicting what the coding environment would return after an agent action.
Did Qwen AgentWorld beat GPT-5.4?
The reported Qwen-AgentWorld-397B-A17B result is slightly higher than GPT-5.4 on AgentWorldBench overall, but that benchmark measures environment simulation quality, not general chatbot superiority. The claim should be explained in that limited context.