

Introduction
You open your editor, fire up an AI coding assistant, and a boring but expensive question pops up: which brain do you trust with your codebase? GPT-5.1 vs Sonnet 4.5 is no longer a social media argument. It is a line item in your cloud bill, a risk to your uptime, and sometimes the difference between a painless merge and a weekend buried in logs.
For ai for developers who live inside Cursor, VS Code, or JetBrains, the real GPT-5.1 vs Sonnet 4.5 question is simple. Which model should be your default workhorse, and when is it worth paying extra for the specialist?
This article treats GPT-5.1 vs Sonnet 4.5 like a tool choice, not a team sport. We will look at benchmarks, pricing, and real workflows so you can decide where each one fits in your stack. By the end, you should know how GPT-5.1 vs Sonnet 4.5 maps to the problems you actually ship, not just leaderboard screenshots.
Table of Contents
1. The Showdown At A Glance: Key Differences For Developers

Underneath all the charts and anecdotes, the takeaway is straightforward. This matchup is really a question of default vs specialist.
GPT-5.1 behaves like a highly capable generalist. It is priced to sit everywhere: in your IDE, your CI bots, your internal tools, and your lightweight agents. Sonnet 4.5 behaves more like a focused expert. It shines when the task is long, messy, and unforgiving, especially when you wire it into terminals and browsers through the Claude Agent SDK.
If you only have time for one section, make it this one. Here is the high level picture of both models from a developer’s perspective, using current pricing and public benchmark runs.
GPT-5.1 vs Sonnet 4.5 benchmark snapshot
Key accuracy, cost and latency signals for developers choosing an AI coding model.
| Benchmark (Date) | What It Tests (Dev View) | GPT-5.1 Accuracy | Sonnet 4.5 Accuracy | GPT-5.1 Cost* | Sonnet 4.5 Cost* | GPT-5.1 Latency | Sonnet 4.5 Latency | High Level Takeaway |
|---|---|---|---|---|---|---|---|---|
| IOI (2025-11-13) | Algorithmic and Olympiad style reasoning | 21.5% | 18.5% | $1.25 / $10.00 (in/out) | $3.00 / $15.00 | 1750.07 s | 3315.17 s | GPT-5.1 is more accurate, faster and cheaper. |
| LiveCodeBench (2025-11-14) | General coding, debugging, execution | 86.5% | 73.0% | $1.25 / $10.00 | $3.00 / $15.00 | 141.24 s | 109.55 s | GPT-5.1 is more accurate per run, Sonnet replies a little faster but costs more. |
| SWE-bench (2025-11-14) | Real world repo bug fixing tasks | 67.2% | 69.8% | ~$0.36 / test | ~$8.26 / test | 563.34 s | 762.98 s | Sonnet 4.5 is a bit more accurate but much slower and far more expensive per test. |
| Terminal-Bench (2025-11-14) | Multi step terminal agents | 47.5% | 61.3% | ~$0.10 / test | ~$2.55 / test | 685.95 s | 525.78 s | Sonnet 4.5 is stronger for long running terminal agents but far pricier per run. |
Cost notes
- IOI and LiveCodeBench “Cost In / Out” is approximate dollars per 1M input / output tokens from public API list prices.
- SWE-bench and Terminal-Bench “Cost / Test” is the evaluator’s estimated all in price for one benchmark sample using those list prices and typical prompts.
Simple story for your mental model:
- GPT-5.1 is cheaper per token, excellent at everyday coding, and solid on full repo and terminal benchmarks. It is a strong default for most dev teams.
- Claude Sonnet 4.5 is more expensive but leads on SWE-bench and Terminal-Bench style work. It fits best where reliability on long, multi step tasks matters more than the API bill.
1.1 Benchmark Snapshot: GPT-5.1 vs Sonnet 4.5 On Core Tasks
At a glance, the comparison looks like a familiar trade.
- On LiveCodeBench, GPT-5.1 is near the very top of all coding models. For bread and butter tasks like writing functions, wiring feature flags, and fixing tests, that matters more than any single marketing claim.
- On SWE-bench, Sonnet 4.5 edges ahead on accuracy. When you hand it a real repository and ask it to close real tickets, it is slightly more likely to land a correct patch in one shot.
- On Terminal-Bench, Sonnet 4.5 pulls further ahead. That benchmark looks like long lived agents operating in a shell, exactly the pattern Anthropic is chasing with the Claude Agent SDK and Claude Code.
So GPT-5.1 vs Sonnet 4.5 is not one model beating the other everywhere. It is a split personality: GPT-5.1 dominates the short and medium coding loops, and Sonnet 4.5 dominates the longest ones.
1.2 Benchmark Reality Check: What The Scores Actually Mean
Benchmarks only become useful when you tie each one to a real job your team does. Here is the quick translation.
- IOI covers algorithmic puzzles and Olympiad style questions. If you lean on models for tricky data structures and math heavy backends, GPT-5.1’s small lead here means fewer logic bugs.
- LiveCodeBench tracks everyday coding, debugging, and execution. This is where most ai for developers work happens, and GPT-5.1 sits near the top, which is what you want from a default AI coding assistant in your editor.
- SWE-bench tests bug fixing in real repositories. Sonnet 4.5 wins by a narrow margin, so you notice the difference on gnarly tickets that touch many files at once.
- Terminal-Bench measures long running terminal agents. Sonnet 4.5 is far ahead here, which matches its design as a model that can keep a tool heavy workflow on the rails for hours.
Read this way, the benchmarks say something simple. GPT-5.1 is tuned for short and medium coding loops. Sonnet 4.5 is tuned for long horizon work where the model needs to remember and act across many steps.
1.3 Cost Per Solved Problem: The Real Bottom Line
The loudest question in most Reddit threads is not “who is smarter,” it is “who is cheaper to trust.”
On IOI and LiveCodeBench style workloads, GPT-5.1 is already ahead on accuracy and costs less per token. There is no real drama there. For most of these tasks, GPT-5.1 vs Sonnet 4.5 is a pure win for GPT-5.1.
SWE-bench and Terminal-Bench are where the trade gets interesting. Sonnet 4.5 wins on raw success rate, yet each SWE-bench test costs roughly twenty times more. That is a wild gap. If your bug fixes or terminal agents are cheap to retry, GPT-5.1 can easily win on cost per solved ticket even when its accuracy is slightly lower.
The right way to read the pricing is to ask a simple question. In your system, is the main cost the API bill or the cost of failure? If mistakes mean downtime, data loss, or grumpy enterprise customers, paying Sonnet 4.5’s premium for higher success on long sequences might be rational. If the worst case is “the test failed, try again,” GPT-5.1 is usually the smarter bet.
2. The Go To Workhorse: When Should You Choose GPT-5.1?
If you want one model sprinkled across your stack, GPT-5.1 is usually the right starting point. In most day to day GPT-5.1 vs Sonnet 4.5 decisions, it is the cheaper, calmer default.
Choose GPT-5.1 as your default when:
- You live in an IDE and want an AI coding assistant that behaves like a reliable mid level engineer.
- You care about cost per line of code and need to keep token spend predictable.
- You are building tools where latency and throughput matter as much as raw accuracy.
GPT-5.1 Instant gives you a warm conversational partner for explanations and brainstorming, while GPT-5.1 Thinking dials up the depth for harder problems. Both follow instructions more cleanly than earlier generations, which keeps rewrites and clarifications to a minimum.
Stack all of that against pricing and benchmark results and a pattern appears. For the average sprint, GPT-5.1 is the practical choice, especially when you compare GPT-5.1 vs Sonnet 4.5 inside the same backlog.
3. The High Stakes Specialist: When Should You Choose Sonnet 4.5?
Sonnet 4.5 is what you reach for when your problem looks less like “write a function” and more like “keep this agent alive for 30 hours while it pokes at a messy system.”
You reach for Sonnet 4.5 when:
- You are building long running agents that manipulate terminals, browsers, or complex enterprise dashboards.
- Your tasks resemble SWE-bench and Terminal-Bench: multi file refactors, hairy migrations, security sensitive changes, or delicate incident response.
- You plan to lean on the Claude Agent SDK to orchestrate tools, memory, and subagents, and you care more about end to end success than raw token price.
The GPT-5.1 vs Sonnet 4.5 decision flips as soon as your main risk moves from “this call was expensive” to “this failure was expensive.” In that world, Sonnet 4.5’s extra reliability on long sequences starts to look cheap.
There is also a cultural angle. Anthropic explicitly pitches Sonnet 4.5 as a safer, more aligned frontier model. It ships with stronger defenses against prompt injection and some of the rougher edges of agent autonomy. If your whole value proposition sits on top of an autonomous agent, that safety work is not a footnote, it is part of the product.
4. The Power User’s Secret: The Two Model Workflow
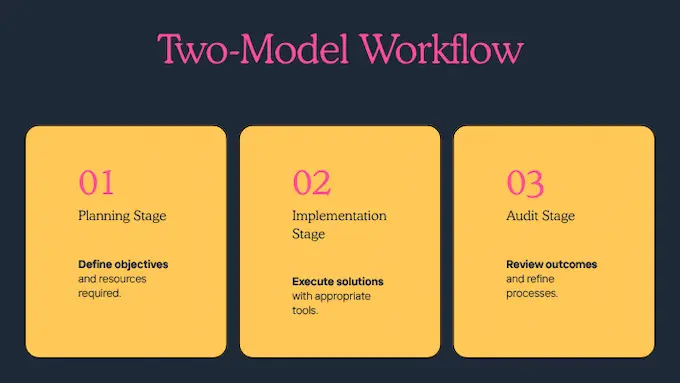
Once you zoom out from single model loyalty, GPT-5.1 vs Sonnet 4.5 stops looking like a rivalry and starts looking like a tag team.
A pattern has already emerged among power users: use Sonnet 4.5 to design and GPT-5.1 to deliver. Sonnet 4.5 is excellent at high level reasoning, architecture, and step by step plans. GPT-5.1 and GPT-5.1 Codex are excellent at actually wiring those plans into code, tests, and integration scripts.
A typical two model loop looks like this:
- Planning pass with Sonnet 4.5
- Ask for a multi phase plan with explicit acceptance criteria.
- Have it outline which files will change, which invariants must hold, and how you will test the result.
- Implementation pass with GPT-5.1 or Codex
- Feed in the plan and your repo context.
- Let GPT-5.1 implement one phase at a time, keeping prompts narrow so context stays clean.
- Audit pass across models
- Ask GPT-5.1 to review Sonnet’s plan and code.
- Ask Sonnet 4.5 to critique GPT-5.1’s implementation, focusing on failure modes and edge cases.
This is where ai for developers gets interesting. You are no longer arguing about who has the single best ai for coding. You are using model diversity the same way you use human diversity on a team: different strengths, different blind spots, better outcomes when they cross check each other.
5. The Vibe Check: Which AI Is A Better Coding Partner?
Performance is only half the picture. The other half is how it feels to live with these systems eight hours a day.
GPT-5.1 Instant leans warmer and more conversational. It is playful without being silly, good at rubber ducking tricky logic, and happy to explain concepts in plain language. GPT-5.1 Thinking keeps that tone but dives deeper when you need more reasoning. For many developers, that combination makes it easier to stay in flow.
Sonnet 4.5, in contrast, feels more no nonsense. It is less sycophantic than many models and will push back when your plan looks shaky. That can feel harsh when you just want validation, but it is valuable when you want a serious partner for design and risk analysis.
The GPT-5.1 vs Sonnet 4.5 choice here is about personality fit:
- If you want a friendly, talkative co-pilot that still respects your instructions, GPT-5.1 is the nicer default.
- If you want something closer to a blunt senior engineer who tells you when you are spiraling, Sonnet 4.5 may feel more trustworthy.
In practice, many teams end up liking both: Sonnet 4.5 for architecture and safety discussions, GPT-5.1 for fast iteration and day to day implementation.
6. The 2025 Market Leaderboard: Where They Fit In The Top 10
The GPT-5.1 vs Sonnet 4.5 debate sits inside a crowded leaderboard. LiveCodeBench results from late 2025 place GPT-5.1 near the very top of current coding models, which is useful context before you tune your stack.
Table 2 – Top 10 Coding Models (LiveCodeBench Snapshot, 2025-11-14)
GPT-5.1 vs Sonnet 4.5 coding peers leaderboard
Top LiveCodeBench models that frame the GPT-5.1 vs Sonnet 4.5 decision for developers.
| Rank (LCB) | Vendor | Model | LiveCodeBench Accuracy | Cost In / Out* ($ per 1M tokens) | Latency (s) | Quick Take For Devs |
|---|---|---|---|---|---|---|
| 1 | OpenAI | GPT 5 Mini | 86.6% | $0.25 / $2.00 | 33.67 | Very fast and cheap for well scoped and high volume tasks. |
| 2 | OpenAI | GPT 5.1 | 86.5% | $1.25 / $10.00 | 141.24 | Frontier grade default that handles code, agents and general tasks well. |
| 3 | OpenAI | GPT 5.1 Codex | 85.5% | $1.25 / $10.00 | 233.56 | Code focused GPT-5.1 variant for repos, refactors and deep reviews. |
| 4 | OpenAI | GPT 5 Codex | 84.7% | $1.25 / $10.00 | 134.35 | Previous generation specialist that still works well for coding. |
| 5 | OpenAI | o3 | 83.9% | $2.00 / $8.00 | 63.95 | Reasoning heavy option when planning and analysis matter more than speed. |
| 6 | xAI | Grok 4 | 83.3% | $3.00 / $15.00 | 228.11 | Competitive frontier model that offers solid coding at a higher price. |
| 7 | OpenAI | GPT OSS 120B | 83.2% | $0.15 / $0.60 | 81.70 | Open style model with good price performance for large internal workloads. |
| 8 | OpenAI | o4 Mini | 82.2% | $1.10 / $4.40 | 32.84 | Fast mini model for interactive tools and low latency IDE features. |
| 9 | zAI | GLM 4.6 | 81.0% | $0.60 / $2.20 | 235.66 | Strong non US option tuned for coding heavy workloads. |
| 10 | OpenAI | GPT OSS 20B | 80.4% | $0.05 / $0.20 | 108.79 | Extremely cheap workhorse with respectable accuracy for batch jobs. |
*Cost column shows approximate vendor list pricing for input and output tokens at the time of these runs.
Sonnet 4.5 is not in this LiveCodeBench top ten because its coding accuracy is lower, around 73 percent. It was tuned more for agent style work. On SWE-bench and Terminal-Bench, where long sequences of actions matter more than raw throughput, Sonnet 4.5 moves back toward the front.
Seen through that lens, GPT-5.1 vs Sonnet 4.5 is straightforward. GPT-5.1 is the wide deployment generalist, and Sonnet 4.5 is the high stakes specialist you call when your workload looks like a long running agent or a complex enterprise system. Together, they cover a huge chunk of what ai for developers actually need from an AI coding assistant in 2025.
7. Build A Toolkit, Not A Monolith
By now the pattern should be clear. GPT-5.1 vs Sonnet 4.5 is not about declaring a single champion. It is about deciding where each one belongs in your everyday workflow.
For most teams, a simple layout works:
- Use GPT-5.1 or GPT-5.1 Codex as the default AI coding assistant in your IDE and CI. Let it chew through tickets, tests, docs, and refactors where price and responsiveness matter most.
- Keep Sonnet 4.5 for the scary work: production incidents, risky migrations, security sensitive changes, and long lived agents that operate across terminals and browsers.
- Where it helps, lean into OpenAI vs Anthropic as a feature. Let one model design, and the other critique. Use their different strengths to keep your own code honest.
GPT-5.1 vs Sonnet 4.5 still sounds abstract until you run the numbers yourself. Pick one real project and instrument it. Run a GPT-5.1 first pass, a Sonnet 4.5 first pass, and a hybrid workflow where they split the work. Measure cost per solved ticket, time to merge, and how much manual rescue you had to do.
Once you have seen GPT-5.1 vs Sonnet 4.5 under the pressure of your own backlog, the decision stops being a blog post and becomes part of how you ship. Treat these systems like serious tools, build a small toolkit you actually trust, and you will get much closer to the best ai for coding for your team.
Which AI is best for developers?
For most developers, GPT-5.1 is the best default because it balances coding accuracy, speed and cost across everyday tasks. Sonnet 4.5 is better for long, high risk workflows like terminal agents and complex repo wide refactors where reliability matters more than price.
Which is the best AI tool for coding?
The best AI tool for coding in 2025 is usually GPT-5.1 or GPT-5.1 Codex inside your IDE, with Sonnet 4.5 reserved for the hardest tickets. Many teams get the best results by pairing them in a two model workflow, using Sonnet 4.5 to plan and GPT-5.1 to implement and iterate.
Is AI actually good for coding?
Yes, modern models like GPT-5.1 and Sonnet 4.5 are very good for coding when you keep prompts specific and review the output. They speed up boilerplate, tests and refactors, and can even solve complex bugs, but human developers still need to own design, security and final review.
How can I use AI as a developer?
You can use AI as a developer by integrating GPT-5.1 or Sonnet 4.5 into your editor for completions, refactors and explanations, and by wiring them into CI bots for tests and docs. For harder tasks, use them to design step by step plans, then implement and review changes in small, auditable chunks.
What is the most cost-effective AI for coding?
For most coding workloads, GPT-5.1 is the most cost effective option because it delivers near top tier accuracy at a lower token price than Sonnet 4.5. If your tasks are cheap to retry, GPT-5.1 usually wins on cost per solved ticket, while Sonnet 4.5 can pay off on rare, high stakes problems.