

GLM 5.2 lands at a funny moment in AI. Developers are tired of paying luxury prices for every autocomplete, every log summary, every “please explain this stack trace” moment. At the same time, nobody wants a cheap model that gets clever in the wrong direction and turns a simple bug fix into interpretive dance.
That is why GLM 5.2 matters. Z.ai is positioning it as an open-weights flagship for long-horizon engineering work, with a 1M-token context window, strong coding benchmarks, and API pricing that sits far below the usual frontier-model toll booth. According to the Z.ai docs, the model targets project-scale coding tasks, long-context debugging, and agentic software workflows. The Hugging Face model card lists it under an MIT license with 753B parameters.
The short version: this is not a casual chatbot release. It is a serious attempt to make frontier-ish engineering intelligence cheaper, more open, and more routable.
Table of Contents
1. GLM 5.2 Benchmarks And Pricing At A Glance
The headline is simple. GLM 5.2 is not beating Claude Opus 4.8 everywhere. It is not beating GPT-5.5 everywhere either. The more interesting story is that it gets close enough in several developer-relevant benchmarks while costing much less per token.
GLM 5.2 Benchmarks
| Category | Benchmark | GLM 5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | Practical Read |
|---|---|---|---|---|---|---|---|
| Reasoning | HLE | 40.5 | 31.0 | 49.8 | 41.4 | 45.0 | Competitive, not leading |
| Reasoning | HLE With Tools | 54.7 | 52.3 | 57.9 | 52.2 | 51.4 | Close to the frontier |
| Reasoning | CritPt | 16.7 | 4.6 | 20.9 | 27.1 | 17.7 | GPT leads |
| Reasoning | AIME 2026 | 99.2 | 95.3 | 95.7 | 98.3 | 98.2 | GLM leads this row |
| Reasoning | GPQA-Diamond | 91.2 | 86.2 | 93.6 | 93.6 | 94.3 | Strong but not top |
| Coding | SWE-bench Pro | 62.1 | 58.4 | 69.2 | 58.6 | 54.2 | Strong open model score |
| Coding | NL2Repo | 48.9 | 42.7 | 69.7 | 50.7 | 33.4 | Claude dominates |
| Coding | DeepSWE | 46.2 | 18.0 | 58.0 | 70.0 | 10.0 | GPT leads |
| Coding | ProgramBench | 63.7 | 50.9 | 71.9 | 70.8 | 39.5 | Near frontier, not first |
| Coding | Terminal Bench 2.1 | 81.0 | 63.5 | 85.0 | 84.0 | 74.0 | Very close |
| Coding | Terminal Bench Best Harness | 82.7 | 69.0 | 78.9 | 83.4 | 70.7 | Nearly tied with GPT |
| Coding | FrontierSWE Dominance | 74.4 | 30.5 | 75.1 | 72.6 | 39.6 | Excellent showing |
| Coding | PostTrainBench | 34.3 | 20.1 | 37.2 | 28.4 | 21.6 | Close to Claude |
| Coding | SWE-Marathon | 13.0 | 1.0 | 26.0 | 12.0 | 4.0 | Still hard for everyone |
| Agentic | MCP-Atlas Public Set | 76.8 | 71.8 | 77.8 | 75.3 | 69.2 | Almost level with Claude |
| Agentic | Tool-Decathlon | 48.2 | 40.7 | 59.9 | 55.6 | 48.8 | Mid-pack against closed models |
GLM 5.2 API Pricing Comparison
| Model Or Plan | Input Price Per 1M Tokens | Cached Input | Output Price Per 1M Tokens | Context | Best Use |
|---|---|---|---|---|---|
| GLM 5.2 | $1.40 | $0.26 | $4.40 | 1M | Long-context coding, routing, repo analysis |
| GLM-5.1 | $1.40 | $0.26 | $4.40 | Varies by product | Cheaper mature GLM workflows |
| GLM-5 | $1.00 | $0.20 | $3.20 | Varies by product | Cost-sensitive coding and reasoning |
| GLM-5-Turbo | $1.20 | $0.24 | $4.00 | Varies by product | Fast coding-plan workloads |
| Claude Opus 4.8 | $5.00 | Provider dependent | $25.00 | 1M | Highest-stakes coding and reasoning |
| GPT-5.5 | $5.00 | $0.50 | $30.00 | 1M class | Professional coding and reasoning |
| Claude Fable 5 Fast-Price Class | $10.00 | Provider dependent | $50.00 | 1M class | Premium frontier tasks where cost matters less |
The Z.ai numbers come from its official pricing page. Claude Opus 4.8 pricing comes from Anthropic, and GPT-5.5 pricing comes from OpenAI’s API pricing page. Pricing changes quickly, so check the live pages before building a production cost model.
2. What Makes GLM 5.2 Different For Developers

The 1M-token context window is the marketing line. The useful part is whether the model can still think coherently near the far end of that context. Big context windows often behave like large backpacks. You can fit everything inside, then spend half the hike forgetting where you put the flashlight.
Z.ai says the model was trained for long-horizon coding-agent scenarios, not just long-prompt demos. That matters for real engineering work because a meaningful task may include architecture notes, code files, tests, logs, migration constraints, and team rules. A short-context assistant can help with a function. A reliable long-context assistant can inspect a repo, respect its boundaries, and avoid inventing a new framework because it got bored.
The technical hook is IndexShare. Z.ai says the architecture reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9x at 1M context length. Translation: the model is trying to make long context less ruinously expensive while keeping retrieval quality useful. That is the right battle. The future of coding agents is not one brilliant answer. It is sustained attention over a messy workspace.
3. GLM 5.2 Vs Claude Opus 4.8 For Real Work
The phrase GLM 5.2 vs Claude Opus 4.8 is going to attract hot takes, charts, and a few suspiciously dramatic YouTube thumbnails. The calmer answer is better: use each model where its economics and behavior make sense.
Claude Opus 4.8 still has the cleaner frontier reputation for hard reasoning, deep code review, and complex multi-file changes. In the official benchmark table, it leads on SWE-bench Pro, NL2Repo, ProgramBench, Tool-Decathlon, and several reasoning tests. If a failed model call can break a customer-facing deployment, the expensive model may still be the cheap choice.
The surprise is how many rows GLM 5.2 makes competitive. Terminal Bench 2.1 at 81.0 puts it close to Opus and GPT. FrontierSWE Dominance at 74.4 is almost level with Claude’s 75.1. MCP-Atlas at 76.8 is also close. For an open-weights model with much lower API pricing, that is not a consolation prize. That is an invitation to route intelligently.
Think of it like hiring. You do not assign every task to your principal engineer. You reserve that person for ambiguous design calls, risky migrations, and situations where judgment compounds. A cheaper but capable model can handle the boring 70 percent: summaries, traces, first-pass reviews, test generation, documentation cleanup, and repetitive repo inventory.
4. GLM 5.2 API Pricing And The 80 Percent Routing Idea
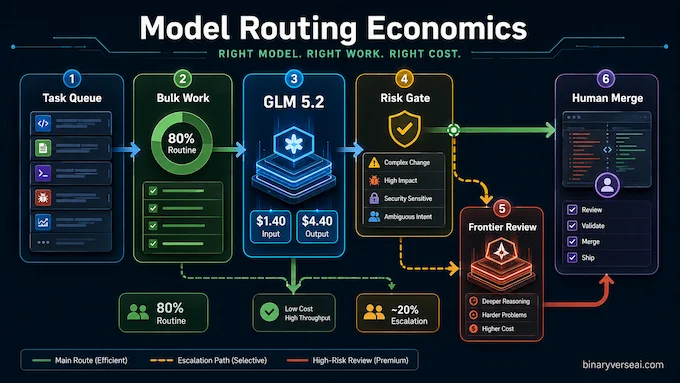
GLM 5.2 API pricing is the real wedge. At $1.40 per million input tokens and $4.40 per million output tokens, it is far cheaper than Claude Opus 4.8 at $5 and $25, and GPT-5.5 at $5 and $30. The difference gets loud when output tokens grow.
Suppose a team runs 100 million input tokens and 20 million output tokens through a model in a month. At Z.ai list pricing, that is roughly $228 before caching. At Claude Opus 4.8 regular pricing, the same token shape is roughly $1,000. At GPT-5.5 standard pricing, it is roughly $1,100. This is not a rounding error. This is the difference between “let the agents inspect the repo” and “please summarize your bug report in exactly twelve tokens.”
The sensible strategy is not total replacement. It is routing.
Send GLM 5.2 the tasks that are large, frequent, and recoverable:
- Log extraction and error clustering
- Internal summaries of tickets and pull requests
- First-pass code review comments
- Repo maps and dependency inventories
- Test scaffolds and migration checklists
- Documentation rewrites and changelog drafts
Reserve Claude Opus 4.8 or GPT-5.5 for the work where failure is expensive:
- Security-sensitive reviews
- Architecture decisions
- Complex refactors across many services
- Production incident reasoning
- Legal, financial, or compliance-heavy outputs
- Final review before merging risky changes
This is the boring 70 percent strategy. It sounds less glamorous than “one model to rule them all,” but it is how sane engineering budgets survive contact with agents.
5. Can You Run GLM 5.2 Locally?
Yes, but this is where the phrase “open weights” needs adult supervision. You can run GLM 5.2 locally in the same sense that you can own a printing press. The license may allow it. Your desk probably does not.
The model card lists 753B parameters. Even with quantization, that is not something a normal gaming PC casually loads after lunch. A 24GB GPU is not the plan. A 48GB workstation GPU is still not the plan for the full model. You are looking at serious multi-GPU infrastructure, very large unified-memory machines, or hosted inference.
The Hugging Face card lists support paths for vLLM, SGLang, xLLM, Transformers, and KTransformers. That is good news for labs and infrastructure teams. It is less comforting for a hobbyist who has one GPU and a dream.
If you want to run GLM 5.2 locally for real throughput, expect the conversation to include BF16 or quantized weights, tensor parallelism, KV cache pressure, storage bandwidth, networked GPUs, and a cooling situation that sounds like a small airport. For most developers, the API or a gateway such as OpenRouter is the realistic way to test it.
6. GLM 5.2 Hardware Requirements In Plain English
The practical GLM 5.2 hardware requirements depend on precision, context length, serving framework, batch size, and whether you need usable latency or merely proof that the model can technically emit tokens before the weekend.
For the full 753B parameter model, BF16 weights alone imply enormous memory needs. Quantization can reduce that, but the 1M context window adds another monster: KV cache. Long context is not free. It consumes memory while the model attends to previous tokens, and very long coding sessions can become a memory planning exercise before they become an AI workflow.
A realistic stack for serious local serving looks like this:
- A multi-GPU server or cluster with very high aggregate VRAM
- vLLM, SGLang, xLLM, or KTransformers
- Fast local storage for model weights
- Careful context-length limits if you do not need the full 1M window
- Quantization experiments for cost and memory reduction
- Monitoring for throughput, time to first token, and cache behavior
That sounds unromantic because it is. The local story is excellent for research groups, model-serving companies, and infrastructure nerds with a heroic electricity bill. For ordinary builders, the right question is not “can I download it?” The right question is “which workloads deserve local hosting, and which should stay behind an API?”
7. Fixing Error 1113 Insufficient Balance Z.ai
One practical reason this model is showing up in developer forums is the GLM Coding Plan. It lets users access GLM models through supported coding tools, but the setup has sharp edges.
The Z.ai Coding Plan FAQ says Error 1113 Insufficient Balance can appear after buying a coding package if usage does not meet plan conditions. The common culprit is endpoint configuration. The coding package is not a generic API balance. It is restricted to officially supported tools and specific base URLs.
Use these endpoints carefully:
- Claude Code and Goose: https://api.z.ai/api/anthropic
- Other supported tools: https://api.z.ai/api/coding/paas/v4
- Standard API calls: https://api.z.ai/api/paas/v4/chat/completions
That last distinction matters. If you point an unsupported SDK flow at the wrong endpoint, you may miss the plan benefit and trigger balance errors or normal billing behavior. It is the kind of tiny configuration issue that makes developers question reality, then discover the culprit was one URL.
Z.ai also notes that plan tiers affect usage and concurrency. Lite, Pro, and Max do not behave the same, and peak traffic can affect real-world limits. If GLM feels like it has only one lane open, check plan tier, API Management notices, supported-tool status, and whether your requests are going through the intended base URL.
8. Creative Writing, Roleplay, And The Alignment Problem
Developer benchmarks are not the whole personality of a model. Early community chatter around GLM models often splits into two camps. Engineers care about repo-scale attention and price. Creative users care about whether the model can write with nerve, continuity, and less corporate fog.
The open model world has a recurring tension here. A model can be smart, but cautious to the point of stiffness. It can produce polished prose that sounds like an anxious lawyer reviewed every adjective. That may be great for enterprise memos. It is less great for fiction, roleplay, or any style that needs risk, texture, and surprise.
The prompting lesson is useful even for technical writing. Do not merely ask for “better output.” Define the permission space. Tell the model what kind of mistakes are acceptable, what tone is desired, and where it should stop over-policing itself. A good system prompt can say: be precise, be direct, do not invent facts, but do not sand every sentence into a compliance brochure.
For Binary Verse AI readers, this is the broader point. GLM 5.2 is not just a benchmark object. It is a tool. And tools behave differently depending on routing, prompting, context design, and failure handling.
9. Should Developers Switch To GLM 5.2?
Developers should test it. That is the honest verdict.
Do not rip out Claude Opus 4.8 or GPT-5.5 from high-risk workflows because a benchmark table looks exciting. Also do not ignore a model that offers 1M context, open weights, strong coding numbers, MIT licensing, and a dramatically cheaper API path. The middle path is obvious and useful: add GLM 5.2 as a routed option.
Start with workloads where review is easy and savings are high. Repo summaries. Log analysis. First-pass issue triage. Internal documentation. Non-critical test generation. Let it prove itself on tasks where a human or stronger model can catch failures. Then slowly move it into harder agentic work if the results hold up.
The model’s biggest contribution may not be that it “beats” Claude or GPT. That framing is fun, but crude. Its real value is pressure. It pressures closed frontier models on price. It pressures open models on long-context engineering. It pressures developers to stop treating model choice like a religion and start treating it like infrastructure.
If you are building AI systems, the next advantage will not come from worshipping one model. It will come from routing the right work to the right intelligence at the right price. GLM 5.2 deserves a place in that experiment.
For more practical AI model breakdowns, pricing guides, and developer-first workflows, follow Binary Verse AI and keep a close eye on the models that make strong engineering cheaper, not just louder.
How Does GLM-5.2 Compare To Claude Opus 4.8 And GPT-5.5?
GLM-5.2 performs near the closed-model frontier, with 62.1 on SWE-bench Pro and 81.0 on Terminal-Bench 2.1. It trails Claude Opus 4.8 on several hard coding benchmarks, but beats GPT-5.5 in selected long-horizon coding rows such as SWE-bench Pro and FrontierSWE. Its biggest advantage is the mix of open weights, 1M context, and lower API pricing.
What Hardware And VRAM Do I Need To Run GLM-5.2 Locally?
GLM-5.2 is a 753B-parameter model, so full local deployment is not realistic on consumer GPUs. The model files alone are extremely large, and long-context serving adds further memory pressure through KV cache. Serious local use needs multi-GPU enterprise hardware, FP8 or quantized serving, and frameworks such as vLLM, SGLang, xLLM, Transformers, or KTransformers. For most developers, Z.ai API access or hosted inference is the practical route.
Why Am I Getting “Error 1113 Insufficient Balance” When Using The GLM Coding Plan?
“Error 1113 Insufficient Balance” usually appears when the GLM Coding Plan is not being used through the correct supported endpoint. For Claude Code and Goose, use https://api.z.ai/api/anthropic. For OpenAI-compatible coding tools, use https://api.z.ai/api/coding/paas/v4. If you use the general API endpoint, your coding package quota may not apply.
Does GLM-5.2’s 1M Context Window Actually Stay Coherent?
GLM-5.2 is designed for stable 1M-token long-context work. Z.ai’s IndexShare architecture reuses the same indexer across sparse attention layers, reducing per-token FLOPs by 2.9x at 1M context. In practice, this makes GLM-5.2 especially useful for large repositories, long support logs, multi-file debugging, and agentic coding sessions. Teams should still test it on their own codebases before relying on it for production workflows.
How Can I Reduce GLM-5.2’s Strict Filtering For Creative Writing Or Roleplay?
Do not try to bypass safety filters. For legitimate creative writing, reduce over-cautious outputs by giving GLM-5.2 clearer editorial direction. Define the genre, tone, boundaries, audience, and style. Add a system instruction such as: “Make reasonable creative choices, avoid unnecessary disclaimers, stay within the user’s boundaries, and prioritize vivid, natural prose.” This usually works better than jailbreak-style prompting and produces cleaner writing.