

Introduction
You built an agent that mostly works, and then it stopped. It forgets its goals, picks the wrong tool, and debugging turns into spelunking through logs. That’s not just bad luck. It’s context engineering, or the lack of it, showing up as brittle behavior. This article gives a clear, practical map for anyone doing AI agent development who wants systems that behave, scale, and can be reasoned about, not prayed over.
(Quick promise: you’ll walk away with a three-pillar mental model, concrete memory patterns, a multi-agent blueprint, and the exact questions to ask when you pick a stack.)
Table of Contents
1. The Core Problem, Why Most AI Agents Feel Like Glorified Workflows
Most early projects call an LLM, parse a response, call a tool, repeat, and hope for the best. That looks like an agent, but it’s a workflow with a personality problem. The real difference between a fragile workflow and a resilient agent is context management.
Context is the data that tells the agent who is speaking, what the goal is, what tools exist, and what’s already been tried. When context is missing, noisy, or unmanaged, the agent will drift, hallucinate, or repeat itself. The recent paper Context Engineering 2.0 calls this the central failure mode of modern agents, and lays out a principled response.
If you care about reliable AI agent development, stop chasing fancy toolkit features. Start owning context.
2. What Is Context Engineering, Really
Context engineering is the systematic practice of designing how we collect, store, manage, and use the signals that define a situation. It is entropy reduction for machine understanding. In practical terms, that means choosing which facts live in short-term memory, which summaries live in long term memory, and how tools and agents exchange those facts. The formal framing in Context Engineering 2.0 makes this explicit, and it helps to think of context engineering as a pipeline, not a single component.
Key idea, stated plainly: the more you invest in shaping context, the less the LLM has to guess. That converts stochastic answers into predictable behavior.
3. The Three Pillars of Professional AI Agent Development
Treat these as your design checklist. Nail these three and your agent goes from demo to dependable.
3.1 Pillar 1, Context Collection
Collect the right multimodal signals, not everything. That includes text, retrieved docs, tool outputs, telemetry, and when needed, images or audio. Era 2.0 systems tolerate raw human signals better than Era 1.0 did, but that tolerance is an asset only if you manage volume and relevance. Table 2 in the paper lists representative collectors you can use as inspiration.
3.2 Pillar 2, Context Management
This is storage plus structure. Use layered memory: a fast short-term buffer and a distilled long-term store. Define transfer rules, for example when an item moves from short to long term. The paper gives formal definitions for short term, long term, and transfer functions. Implementing these rules makes your agent consistent across sessions.
3.3 Pillar 3, Context Usage
Decide how the agent reads and writes context, and how agents share it. Options include embedding context into prompts, exchanging structured JSON messages, or using a shared blackboard memory. Pick the pattern that fits your task, then standardize it. The paper shows several practical patterns for intra and cross system sharing.
4. Beyond RAG, Advanced Techniques for Context Collection and Management
RAG is a great baseline. Retrieval makes LLMs grounded. For production AI agent development you need more than retrieval.
- Self-baking. Convert raw dialogue, tool output, and observations into compact, structured artifacts. That could be natural-language summaries, schema entries, or vectors that you re-embed for semantic lookup. Self-baking moves you from “store everything” to “learn from what happened.”
- Hierarchical notes and vector compression. Keep the raw detail in a cold store, then create progressively compressed summaries and embeddings for active reasoning. This drastically reduces token costs and keeps attention focused on what matters.
- Functional isolation with subagents. Give specialized tasks their own context windows and restricted permissions. That prevents cross-pollination of irrelevant state and makes debugging simpler. Claude Code and similar subagent systems show this pattern in action.
5. Building a Resilient Agent Memory, Practical Patterns and Architectures
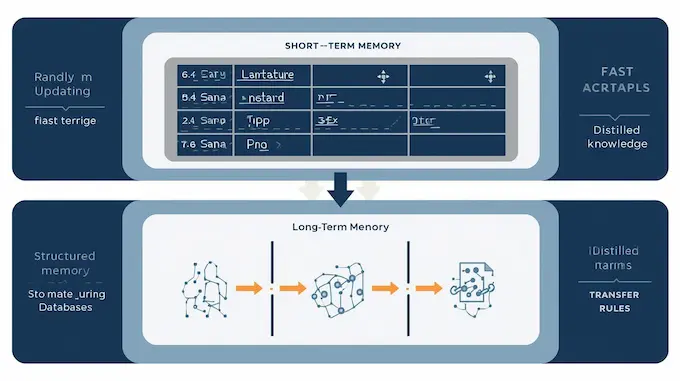
Memory is where agents win or die. Use a layered architecture.
5.1 Short Term, Fast Access
Implement a working memory that holds just what the current plan needs. Time stamp entries and keep lightweight role tags like goal, step, or evidence. This keeps the prompt focused.
5.2 Long Term, Distilled Knowledge
Store persistent facts, user preferences, and proven heuristics here. Use schema extraction for facts you need to query with precision, and embeddings for broad semantic search. The paper formalizes thresholds for choosing what moves from short term to long term.
5.3 Transfer Rules
Automate consolidation. For example, when a short-term item is accessed N times or flagged by a human as important, trigger a transfer operation that produces a summary, schema entry, and an embedding. That creates a readable track for audits and reduces surprise behaviors later.
5.4 Table, Memory Patterns at a Glance
Memory Patterns for AI Agent Development
| Pattern | When to Use | Strengths | Weaknesses |
|---|---|---|---|
| Timestamped Log | Simple chats, low infrastructure | Easy to implement, chronological trace | Hard to retrieve semantically, grows fast |
| Hierarchical Notes | Long, evolving tasks | Preserves structure, good for planning | Requires extractor logic |
| Schema Extraction | Facts and entity state | Precise queries, easy to update | Needs robust parsing and validation |
| Vector Embeddings | Semantic search across noisy data | Fast semantic matches | Hard to inspect, needs reranking |
| Subagent Isolation | Multi-role systems | Limits pollution, parallelism | Adds orchestration complexity |
The choices above are practical levers for any serious AI agent development effort, and they align with the patterns described in Context Engineering 2.0.
6. Architecting Multi-Agent Systems for Complex Tasks
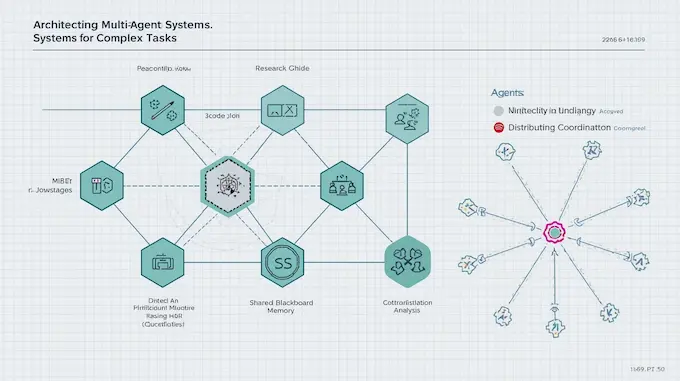
When a task is naturally decomposable, multiple agents are cleaner than a single Swiss Army knife agent.
6.1 Direct Communication
Use structured JSON schemas for message passing. That avoids the brittle natural language interface and makes integration testable. The paper highlights exchanging structured messages as a robust pattern.
6.2 Indirect Communication
Use a shared memory or blackboard. Agents write their intermediate results there and other agents pick up relevant segments. This is great for asynchronous workloads and scales token budgets across systems.
6.3 Shared Representations
Agree on a universal data format early in your design. JSON schemas, lightweight typed records, or shared vector spaces reduce the friction of cross-agent collaboration. The trade off is coordination cost up front, but you save debugging time later.
7. Choosing Your Stack, Frameworks as Implementations of Principles
Frameworks like LangChain, LangGraph, and CrewAI are useful sets of primitives. They are not silver bullets. If you understand the three pillars, you can evaluate frameworks by how well they help you collect, manage, and use context.
Ask these questions when you compare stacks:
- How does it represent memory and transfer between layers?
- How does it handle schema extraction and indexing?
- Can you run subagents with isolated contexts?
- How observable is the runtime, including token use and tool calls?
Frameworks can speed up AI agent development. They often trade simplicity for black-box behavior, so prefer stacks that expose intermediate states and let you plug in your own storage, indexing, and reranking logic. The paper emphasizes choosing tools that implement first principles, instead of chasing feature lists.
8. Hard Problems and How to Manage Risk
Long-horizon memory introduces four stubborn pain points.
- Storage bottlenecks. Keep the minimal sufficient data, compress aggressively, and tier storage between cold, warm, and hot.
- Processing degradation. Attention thins as inputs grow. Use summarization, local caches, and reranking to keep the working set small.
- System instability. Small memory errors can cascade. Isolate functionality with subagents and provide validation gates to prevent contamination.
- Evaluation gap. Benchmarks rarely check for reasoning over long memories. Add unit tests for memory transfer, and smoke tests that replay historical sessions.
None of these are unsolvable. They are engineering trade offs you must plan for when moving from proof of concept to production AI agent development.
Closing, Shift to a Context-Centric Mindset
If you only remember one sentence from this article, remember this: the defining difference between demos and dependable systems is how you treat context.
AI agent development is not a library choice, it is a discipline. Put context collection, context management, and context usage at the center of your design. Build transfer rules early, bake summary and schema generation into your pipeline, and isolate responsibilities across subagents. Those moves convert brittle workflows into systems you can monitor, reason about, and ship.
If you want a short checklist to take away, here it is:
- Start with a minimal working memory and a clear short-to-long transfer rule.
- Add schema extraction for facts you need to query deterministically.
- Use embeddings plus a reranker for semantic recall.
- Isolate special roles into subagents and use a shared blackboard for coordination.
If you want help turning this into code, share the simplest agent you have and I will rewrite its memory layer into a concrete short-term/long-term pipeline with transfer rules and a suggested schema. That’s how you move from curiosity to craft in AI agent development.
If you want the paper I referenced, it’s Context Engineering 2.0 and it’s a dense, practical read. I drew the memory definitions and the era breakdown directly from it.
Ready to refactor your agent’s memory? Send me your agent sketch and I’ll return a compact, prioritized plan you can implement this week with tools like OpenAI Codex, Gemini Robotics, or Qwen3 Coder. Compare approaches across Gemini 2.5 Pro vs Gemini Deep Research to see different context strategies in action.
What is “Context Engineering” and why is it essential for professional AI agent development?
Context Engineering is the systematic practice of designing how an AI agent collects, manages, and uses information to understand a situation. It is essential because it provides the architectural foundation for building agents that are resilient, scalable, and predictable. Without it, most agents remain brittle workflows that fail in complex, long-running tasks.
2. My AI agent is unreliable. How can I improve its consistency and stop it from getting stuck?
Your agent’s unreliability is likely a context management problem, not a code issue. To improve consistency, implement a structured memory system instead of just relying on chat history. Key techniques include:
A Layered Memory: Separate memory into a fast short-term layer for current tasks and a distilled long-term layer for persistent knowledge.
‘Self-Baking’: Create processes for the agent to automatically summarize raw interactions into structured knowledge (like facts or summaries), allowing it to learn from experience.
3. How is Context Engineering different from advanced RAG techniques?
Think of Retrieval-Augmented Generation (RAG) as a single, powerful tool, while Context Engineering is the entire engineering discipline and workshop.
RAG is a tactic primarily focused on context collection—retrieving relevant documents to ground an LLM.
Context Engineering is a holistic framework that includes collection (like RAG), but also management (memory, abstraction), usage (reasoning, tool selection), and multi-agent collaboration.
4. What is the best way for multiple AI agents to communicate and collaborate on a task?
There are three primary patterns for effective multi-agent communication, each with different trade-offs:
Direct Communication: Agents exchange structured messages (e.g., JSON) with a predefined schema. This is clear and testable.
Shared Memory (Blackboard): Agents communicate indirectly by writing to and reading from a common data store. This is excellent for asynchronous tasks.
Shared Representation: All agents agree on a universal data format or API standard, which simplifies integration at the cost of more upfront design.
5. Do I need a complex framework like LangChain to build an effective AI agent?
No. Understanding the principles of context engineering is far more important than the specific framework you choose. An effective agent can be built with a lightweight stack if it correctly implements core patterns for memory, context management, and tool use. Frameworks can accelerate development, but they are tools that implement these principles—they are not a substitute for them.