

Introduction
Most LLM agents today are brilliant goldfish. They reason well. They plan decently. They can browse, search, shop, code. Then the episode ends, and it is as if nothing ever happened. No scars. No instincts. No accumulation.
That is the quiet ceiling on current agent systems. Not reasoning depth. Not model size. Memory.
In this piece, we are going to talk about Agentic Memory, why most “memory” systems are still glorified log storage, and how a new framework called SkillRL reframes the problem from scratch. If you care about reinforcement learning for LLMs, or you are trying to train LLM agents in production, this shift matters.
We will move from the core failure mode, agent amnesia, to the mechanics of skill distillation, to the GRPO LLM training loop, and finally to what this means for engineers building real systems.
Table of Contents
1. The Agent Amnesia Problem: Why Web Search And RAG Are Not Enough

There is a common question on forums: “Why can’t LLM agents just do web searches and store the results?” Because dumping more text into a context window is not Agentic Memory.
Most existing memory systems store raw trajectories. Every action. Every thought. Every mistake. Then at inference time, they retrieve a chunk of that log and paste it back into the prompt.
The result looks like learning. It is not learning. It is replay.
Raw trajectories are noisy. They contain backtracking, redundant steps, wrong turns, and half-formed reasoning. When you inject that into the context window, you are asking the model to extract signal from a pile of entropy, under token limits.
That approach has three structural issues:
- Redundancy: The same principle appears across many episodes, but in slightly different forms.
- Noise: Exploration steps drown out the key decision boundary.
- Context bloat: More memory means more tokens, which means worse “lost in the middle” behavior and higher inference cost.
The SkillRL paper frames this gap explicitly, arguing that storing raw trajectories prevents agents from extracting high-level reusable behavioral patterns.
Human experts do not memorize every action they ever took. They compress experience into skills. That compression is the missing abstraction layer.
Here is the difference at a glance:
| Approach | What Is Stored | How It Is Used | Failure Mode |
|---|---|---|---|
| RAG + Logs | Raw trajectories | Retrieved verbatim into prompt | Noise and token bloat |
| Prompt Memory | Summaries or reflections | Injected at inference only | No policy update |
| Static Memory + RL | Memory separate from policy | Memory may update, policy may not | Weak integration |
| SkillRL With Agentic Memory | Distilled skills from success and failure | Retrieved and co-trained with policy via RL | Dynamic abstraction and evolution |
If you want real Agentic Memory, you need abstraction plus weight updates.
2. What Is Agentic Memory For LLM Agents
So what is Agentic Memory, concretely? Agentic Memory is not just recall. It is structured, evolving, reusable knowledge that influences the policy itself. In the SkillRL framing, Agentic Memory for LLM agents has three defining properties:
- It abstracts experience into compact skills.
- It distinguishes general strategy from task-specific heuristics.
- It co-evolves with the agent’s internal policy through reinforcement learning.
This is a shift from static storage to dynamic knowledge abstraction.
When people ask, “how does agentic memory work,” the honest answer is that it has two loops:
- A distillation loop that converts trajectories into skills.
- A policy loop that updates model weights to actually use those skills.
Without the second loop, you are just doing fancy prompt engineering. Agentic Memory becomes real when the model’s neural policy changes as a result of past experience. That is where reinforcement learning for LLMs enters the picture.
3. Enter SkillRL: A Paradigm Shift In Reinforcement Learning For LLMs
SkillRL is built around a simple thesis: experience must be abstracted before it can improve policy. The framework, introduced in the paper SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, proposes a pipeline that bridges raw interaction and policy improvement.
The headline results are hard to ignore:
- 89.9 percent success on ALFWorld.
- 72.7 percent success on WebShop.
- Over 15 percent absolute improvement over strong baselines.
- Clear gains over vanilla GRPO.
More interesting than the numbers is the mechanism.
SkillRL does three things:
- Distills successful and failed trajectories into skills.
- Organizes them into a hierarchical SkillBank.
- Updates both the policy and the SkillBank recursively during RL.
This is reinforcement learning for LLMs that treats memory as a first-class, trainable component.
If you are exploring rl for llm agents beyond reward shaping, this is one of the cleanest implementations to study.
4. The Architecture: Building An Experience-Based SkillBank

The first key component is experience-based skill distillation. You roll out a base model in the environment. You collect trajectories. Crucially, you keep both successes and failures. Then a teacher model processes each trajectory differently:
- Successful episodes become distilled strategies.
- Failed episodes become concise lessons from failure.
Instead of storing:
Step 1: open fridge Step 2: go to counter Step 3: realize egg missing Step 4: go back to fridge
You store:
Principle: Secure the target object before interacting with appliances. When to apply: Any task involving heating food items.
That is Agentic Memory in action.
This distillation compresses experience dramatically. The paper reports large token compression compared to raw trajectories.
The key is that the result is structured knowledge, not verbose narrative.
5. Solving Skill Conflicts: General Vs. Task-Specific Knowledge
One Reddit concern is obvious: what if skills conflict? The answer is hierarchy. SkillRL’s SkillBank has two layers:
- General skills: Universal strategies like systematic exploration or goal decomposition.
- Task-specific skills: Heuristics for categories like “heat,” “pick_and_place,” or “clean.”
At inference, the agent retrieves:
- All general skills.
- Top-K relevant task-specific skills via embedding similarity.
This keeps Agentic Memory targeted.
In embedding mode, skills are ranked using a model like Qwen3-Embedding-0.6B. Only the most relevant ones are injected into context. The result is selective recall. Not everything you ever learned. Only what applies. Agentic Memory is contextual, not global.
6. The GRPO LLM Engine: Yes, It Actually Updates The Weights
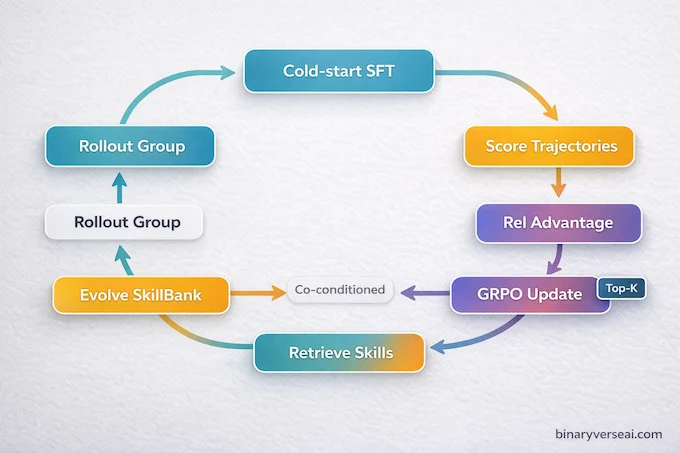
Let’s address a myth: “RL for agents is just prompt tuning.” Not here. SkillRL uses a cold-start supervised fine-tuning phase to teach the model how to use skills. Then it switches to a GRPO LLM training phase.
GRPO, or Group Relative Policy Optimization, computes normalized advantages within groups of sampled trajectories and updates the policy with a PPO-style objective. In simple terms:
- Sample multiple trajectories.
- Score them.
- Compute relative advantages.
- Update the policy.
This is real reinforcement learning for LLMs. The critical point is that the policy conditions on retrieved skills during training:
$$a_t \sim \pi_\theta(a_t | o_{\le t}, d, S_g, S_{ret})$$
That means the weights learn to internalize how Agentic Memory should guide action selection. If you are implementing rl for llm agents, this co-conditioning is the trick. Memory is not bolted on. It is in the loop.
The recursive update also modifies the SkillBank when validation failures expose gaps. That is where grpo llm training and memory evolution intertwine.
7. Context Efficiency: Doing More With Less Prompt Bloat
One of the underrated contributions is context efficiency. Raw memory methods average large prompt sizes. Skill abstraction reduces that footprint while improving performance.
Why?
Because principles compress better than transcripts. Instead of injecting 1,500 tokens of messy history, you inject six compact skills. That keeps the reasoning space clean.
This matters in production. Token cost is real. Latency is real. “Lost in the middle” errors are real. Agentic Memory done right is cheaper and better.
8. Real-World Benchmarks: Dominating ALFWorld And WebShop
Numbers do not prove theory, but they test it. On ALFWorld and WebShop, SkillRL outperforms:
- Prompt-based methods like ReAct and Reflexion.
- Vanilla RL methods like PPO and GRPO.
- Memory-augmented RL hybrids.
The paper’s tables show consistent gains across subtasks and domains. More striking, a 7B open model with Agentic Memory can outperform larger closed-source systems in these environments.
That suggests a strong claim:
Structured experience beats scale, at least in constrained agent settings.
9. Developer Guide: How To Train LLM Agent With SkillRL
If you want to train LLM agent systems using this paradigm, here is the practical stack.
Base model: Qwen2.5-7B-Instruct. Teacher model: Stronger model for distillation and SFT data generation. RL algorithm: GRPO. Libraries: vLLM, flash-attn, and a trainer framework.
Training pipeline:
- Generate memory data via base rollouts.
- Distill into skills.
- Perform cold-start SFT with skill-augmented traces.
- Run GRPO training with skill retrieval enabled.
- Periodically evolve SkillBank using validation failures.
Hardware expectations:
- SFT and RL require serious GPU capacity.
- Inference with SkillBank retrieval is much lighter.
If you are exploring reinforcement learning for LLMs in enterprise settings, this pipeline is reproducible. It is not magic. It is engineering.
10. A Peek Inside The SkillBank
Let’s make this concrete. A distilled skill might look like this:
{
"skill_id": "gen_010",
"title": "Progressive Goal Decomposition",
"principle": "Break complex tasks into ordered sub-goals and verify completion before proceeding.",
"when_to_apply": "Any multi-step task requiring object manipulation or environment transitions.",
"common_mistakes": "Skipping verification before moving to next sub-goal."
}
That is Agentic Memory. Not a story. Not a transcript. A reusable rule. The SkillBank structure includes:
- general_skills
- task_specific_skills
- common_mistakes
This schema bridges theory and code. You can inspect it. Version it. Audit it. Agentic Memory becomes a tangible artifact.
11. Conclusion: Skill Accumulation Is The New AI Moat
We are entering a phase where base models are commodities. Compute is expensive but accessible. Open weights are improving. Fine-tuning pipelines are standardized. The differentiator will not be who has the biggest transformer.
It will be who has better Agentic Memory. Agents that can:
- Distill experience into skills.
- Update their weights via reinforcement learning for LLMs.
- Recursively refine their knowledge through grpo llm training.
- Maintain context efficiency.
- And continuously train LLM agent systems without catastrophic drift.
Skill accumulation compounds. Every failure becomes structured knowledge. Every success becomes a reusable pattern. The SkillBank grows. The policy sharpens. That is not just memory. That is evolution.
If you are building agents today, do not settle for log replay. Design for Agentic Memory from day one. Tie it to reinforcement learning for LLMs. Let the policy and memory co-evolve.
Because the agents that remember how they failed, and change their weights accordingly, will outlearn the ones that just paste transcripts.
And in a world of equal models, learning speed is everything.
What is agentic memory, and how does it differ from RAG?
Agentic memory is a system where an AI agent distills past successes and failures into reusable high-level skills that influence future decisions. Unlike Retrieval-Augmented Generation (RAG), which retrieves raw text from a database like a search engine, agentic memory compresses experience into structured principles. This reduces prompt bloat and enables genuine behavioral learning rather than simple recall.
Does reinforcement learning for LLM agents actually change the model weights?
Yes. Reinforcement learning for LLM agents physically updates the model’s neural weights. Frameworks like SkillRL use GRPO (Group Relative Policy Optimization) to adjust the internal policy based on reward signals. This means the agent’s decision-making improves structurally, not just through prompt engineering.
How does SkillRL prevent skills from conflicting across different tasks?
SkillRL uses a Hierarchical SkillBank that separates memory into General Skills and Task-Specific Skills. General skills provide universal strategy guidance, while task-specific skills are retrieved dynamically using embeddings. This prevents cross-task contamination and ensures only relevant skills are applied in a given scenario.
What is GRPO in LLM training, and why is it used for agents?
GRPO, or Group Relative Policy Optimization, is a reinforcement learning algorithm that optimizes a model by comparing performance across multiple sampled trajectories. It estimates relative advantages without requiring a separate critic model. This makes it efficient for training LLM agents operating in long-horizon environments.
Can I run and train SkillRL locally?
Yes. SkillRL is fully open-source. Full reinforcement learning training with models like Qwen2.5-7B requires high VRAM capacity, typically multi-GPU clusters for optimal speed. However, inference and smaller-scale distillation workflows can run locally using frameworks such as vLLM or SGLang.