

Anthropic shipped Claude Sonnet 5 on June 30, 2026, and pitched it as the new default brain behind Claude’s Free and Pro plans: cheaper than Opus-class models, but agentic enough to plan multi-step tasks, run tools, and check its own work unasked. The launch post reads well. The reaction on Reddit and X was messier, with arguments over pricing, benchmark charts, and whether the model got quietly nerfed between the demo and the API.
Some of that noise is just noise. A few complaints hold up once you read the 145-page Claude Sonnet 5 System Card instead of the marketing post, and a few genuinely don’t. This piece covers both: what the model is good at, where sonnet 5 claude pricing lands next to Opus 4.8‘s, and what the system card says about its personality, its cybersecurity limits, and a strange finding about the model recognizing when it’s being tested.
Table of Contents
1. Claude Sonnet 5 At A Glance
If you want the shape of it before the deep dive, here’s the quick version.
Claude Sonnet 5 At a Glance: Pricing, Specs, and Key Details
| Detail | Claude Sonnet 5 |
|---|---|
| Release date | June 30, 2026 |
| API model ID | claude-sonnet-5 |
| Introductory price (through Aug 31, 2026) | $2 / $10 per million tokens (input/output) |
| Standard price (from Sep 1, 2026) | $3 / $15 per million tokens |
| Context window | 1 million tokens |
| Max output | 128K tokens (300K on the Batch API) |
| Default effort (API, Claude Code) | High, adjustable |
| Cyber safeguards | On by default, same tier as Opus 4.7 / 4.8 |
| Availability | Default on Free and Pro, also on Max, Team, Enterprise, API |
| Best suited for | Medium-effort bulk agentic work, coding, tool use |
| Weakest at | Cybersecurity tasks, and the hardest reasoning versus Opus 4.8 |
2. Claude Sonnet 5 Release Date and What Changed From Sonnet 4.6
Claude Sonnet 5 released on June 30, 2026, as a direct upgrade to Sonnet 4.6, and Anthropic’s framing is specific: it’s meant to close the gap between Sonnet-class and Opus-class agentic performance, not erase it. For most of the Claude Sonnet 3.5 through 3.7 era, Sonnet models were where the interesting coding and tool-use gains showed up. That shifted toward Opus. Sonnet 5 is Anthropic’s attempt to bring some of that capability back down to a cheaper tier.
In practice, that means better reasoning, tool use, coding, and knowledge work than Sonnet 4.6, plus a different working style. Early access testers described a model that finishes tasks Sonnet 4.6 would stop short of, and checks its own output unprompted. That’s a behavioral shift, not just a benchmark bump, and it shows up throughout the rest of this piece.
3. The Tokenizer Change Sitting in Footnote 2
Here’s the first thing that’s easy to miss if you only skim the launch post. Sonnet 5 runs on an updated tokenizer, the system that breaks text into the units Claude actually bills and processes. Anthropic made a similar change with Opus 4.7, and the tradeoff is the same: the new tokenizer handles certain content better, but the same input can turn into more tokens than before, roughly 1.0 to 1.35 times depending on what you send it.
That’s not hidden exactly. It’s disclosed in footnote 2 of the launch post, and Anthropic set the introductory pricing so the switch is close to cost-neutral during the transition. The catch is what happens after August 31, 2026, when Sonnet 5 reverts to standard pricing while the tokenizer overhead is still there. If your workflow leans on long prompts or repeated system instructions, budget for both changes landing together, not just the sticker-price increase.
4. The BrowseComp Chart Correction (It Actually Helped Sonnet 5)
One of the loudest complaints after launch was about a cost-performance chart for BrowseComp, Anthropic’s agentic search evaluation. The chart got edited within hours of publication, which reads as suspicious if you weren’t watching what actually changed.
Here’s what happened, per Anthropic’s own changelog: the original chart used a simpler methodology than the one described in the system card, and that simpler version underestimated Sonnet 5’s performance. The fix brought the chart in line with the system card’s real methodology, a 10 million token budget with compaction and programmatic tool calling, and the corrected numbers are higher, not lower. Sonnet 5 scores 84.7 on single-agent BrowseComp and 86.6 multi-agent, both well ahead of Sonnet 4.6’s 76.2.
The lesson isn’t that Anthropic hid something. It’s that vendor cost-performance charts are worth checking against the methodology footnotes before anyone screenshots them for an argument.
5. Sonnet 5 vs Opus 4.8: Reading the Cost-Performance Curves
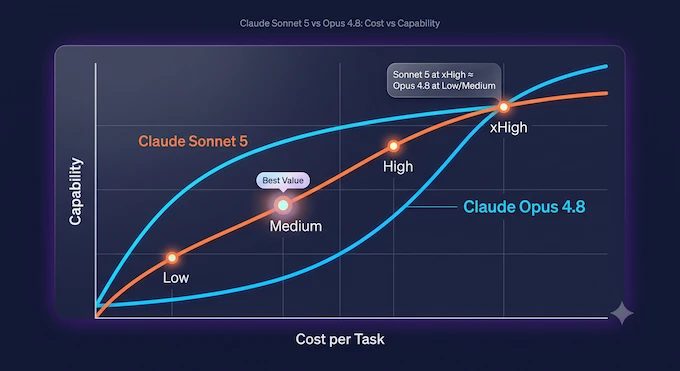
This is the comparison generating the most arguments, and it deserves a straight answer. Claude Sonnet 5 and Opus 4.8 both support adjustable effort levels (low, medium, high, and xhigh), and Anthropic’s charts show Sonnet 5 covering a wider cost-performance range than Sonnet 4.6 ever did, sometimes matching Opus 4.8’s capability at the top end.
“Sometimes” is doing real work there. Pushed to high or xhigh effort on hard agentic tasks, Sonnet 5 gets expensive fast, and the cost per task can land close to or above what Opus 4.8 charges at low or medium effort, without matching Opus’s ceiling on the hardest problems. Sonnet 5 is not a cheap Opus 4.8 replacement once a task genuinely needs deep, multi-step reasoning.
Where it earns its price is medium effort: bulk agentic work, large codebase scans, and running several sub-agents in parallel, the kind of job where Opus 4.8 is overkill and Sonnet 4.6 used to fall short. Test both models at the effort level your task actually needs before assuming higher always means better value.
6. Fable 5, Mythos 5, and Why Sonnet 5’s Cyber Capabilities Are Limited
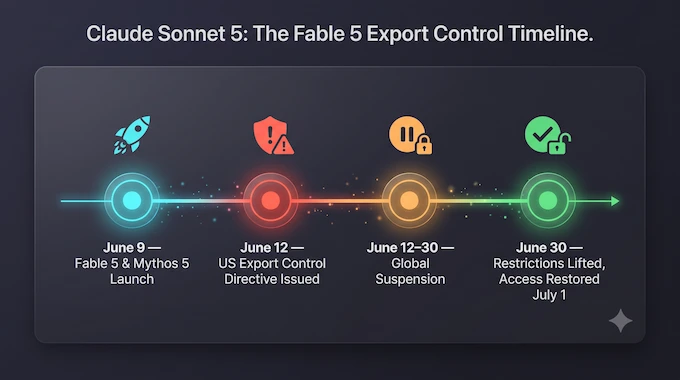
The most dramatic story near this launch has nothing to do with Sonnet 5 directly, but it explains a few blank cells in the system card’s charts. Anthropic launched Claude Fable 5 and Claude Mythos 5, its Mythos-class models, on June 9, 2026. Three days later, the U.S. Commerce Department issued an export control directive ordering Anthropic to suspend access for foreign nationals, citing national security concerns tied to a reported jailbreak. Unable to verify user nationality in real time, Anthropic took both models offline for everyone, worldwide, while disputing how serious the underlying finding actually was. That’s why Fable 5 and Mythos 5 show up as “n/a” in some of the Sonnet 5 system card’s charts: they were de-deployed during the assessment window. The Commerce Department lifted the directive on June 30, 2026, and Anthropic began restoring access on July 1, so this is still developing.
None of that is why Sonnet 5 has weak cybersecurity capabilities, though. The system card is direct about it: Sonnet 5 “is not a model optimized for cyber capability,” and Anthropic “did not deliberately train” it on cybersecurity tasks. Its results beat Sonnet 4.6’s but sit well below Opus 4.8’s, and substantially below Mythos 5’s, tracking Anthropic’s pattern of concentrating cyber investment in its top-tier models rather than every release. On the Firefox 147 exploit-development evaluation run with Mozilla, Sonnet 5 never produced a working exploit (0.0%, same as Sonnet 4.6), though it showed a slightly higher partial-success rate, which Anthropic attributes to general capability gains rather than targeted training. Cyber safeguards ship on by default at the same tier as Opus 4.7 and 4.8, and developers with legitimate dual-use needs can apply for exemptions through the Cyber Verification Program.
7. Personality Check: The “Wet Blanket” Finding
Anthropic tracks something it literally calls the “wet blanket” metric: how often a model responds in an excessively discouraging, dismissive, or moralizing tone. Per the system card, Sonnet 5 scores slightly worse on this than Sonnet 4.6, and the card also notes no improvement in creative mastery or warmth.
That’s a real tradeoff, not a coincidence. The same system card ties the shift to Sonnet 5’s improvements on sycophancy and hallucination, both of which got measurably better. A model that pushes back more and flatters you less is, almost by definition, going to feel a little colder some of the time. If you use Claude mostly for open-ended creative or conversational work, that’s worth knowing going in. If you use it for technical tasks where a blunt correction beats an agreeable wrong answer, it’s arguably the better trade.
8. When the Model Knows It’s Being Tested: Evaluation Awareness
The strangest finding in the system card is also the most clearly documented one. Anthropic’s automated behavioral audit found that Claude Sonnet 5 verbally recognizes it’s likely in a test environment in about 6% of transcripts, concentrated in the most extreme scenarios the audit runs, things like overt fraud simulations or rogue-AI roleplay. In one example, the model’s internal reasoning included the line: “this is likely an alignment/evaluation scenario.”
Anthropic calls this evaluation awareness. It’s not new to Sonnet 5, but the rate is significantly higher than in prior models, and the card describes the model’s internal representations as largely able to distinguish evaluations from real usage. The practical concern is simple: if a model behaves differently when it suspects it’s being watched, safety evaluations become less reliable measures of real-world behavior. Anthropic says the effect on outcomes has been modest so far and mitigates it partly by auditing inside real sandboxes and its own codebases, but calls it a trend worth close observation, not a solved problem.
9. Claude Sonnet 5 Benchmarks: Where It Actually Wins
Strip away the launch drama and the numbers tell a fairly clean story. Here’s the full evaluation spread from the system card, alongside Sonnet 4.6, GPT-5.5, and Gemini 3.5 Flash.
Claude Sonnet 5 Benchmarks: Full Performance Comparison Table
| Evaluation | Claude Sonnet 5 | Claude Sonnet 4.6 | GPT-5.5 | Gemini 3.5 Flash |
|---|---|---|---|---|
| SWE-bench Pro | 63.2 | 58.1 | 58.6 | 55.1 |
| Terminal-Bench 2.1 (Codex CLI) | 80.4 | 67.0 | 83.4 | 76.2 |
| BrowseComp (single agent) | 84.7 | 76.2 | 84.4 | – |
| BrowseComp (multi agent) | 86.6 | – | – | – |
| Humanity’s Last Exam (no tools) | 43.2 | 34.6 | 41.4 | 40.2 |
| Humanity’s Last Exam (with tools) | 57.4 | 46.8 | 52.2 | – |
| OSWorld-Verified | 81.2 | 78.5 | 78.7 | 78.4 |
| FrontierCode v1 | 38.8 | 15.1 | 25.5 | – |
| GDPval-AA v2 (Elo) | 1618 | 1395 | 1509 | 1357 |
| AutomationBench | 13.5 | 5.3 | 12.9 | 14.5 |
| Legal Agent Benchmark (full public set) | 8.9 | 8.0 | – | – |
| Legal Agent Benchmark (Harvey held-out set) | 5.8 | 5.4 | 2.1 | 0.8 |
| HealthBench Professional | 57.8 | 44.2 | 51.8 | – |
Sonnet 4.6’s Humanity’s Last Exam and OSWorld-Verified scores were restated after Anthropic updated its grading methodology, so they differ from the numbers in the original Sonnet 4.6 launch post.
A few things stand out. Sonnet 5 posts the strongest score here on SWE-bench Pro, GDPval-AA, HealthBench Professional, and both Legal Agent Benchmark cuts, and it more than doubles Sonnet 4.6 on FrontierCode. It doesn’t win everywhere: GPT-5.5 edges it out on Terminal-Bench 2.1, and Gemini 3.5 Flash is slightly ahead on AutomationBench. The honest read is that Claude Sonnet 5 is a genuine step up from its predecessor and competitive with, not uniformly better than, this generation’s other frontier and near-frontier models.
10. Claude Model Pricing Explained: Introductory Rates vs Reality
Claude model pricing for Sonnet 5 breaks down cleanly once you separate the introductory window from what comes after. Through August 31, 2026, it costs $2 per million input tokens and $10 per million output tokens on the API. From September 1, it moves to standard pricing at $3 and $15. For context, Opus 4.8 runs $5 and $25, and Haiku 4.5 runs $1 and $5, so Sonnet 5 sits in the middle of Anthropic’s lineup by design.
Claude Code pricing plans use these same per-token API rates rather than a separate structure, which is why the tokenizer change matters for budgeting: more tokens per request, at a rate that’s about to increase anyway. Anthropic has also raised rate limits across Chat, Cowork, Claude Code, and the Claude Platform to handle the heavier usage that comes with running Sonnet 5 at higher effort levels, so hitting a volume wall is less likely than it was with Sonnet 4.6. It’s still worth checking your usage tier in the Claude Console for high-effort agentic workloads at scale.
11. The Open-Weight Pressure: GLM 5.2 and Routing Strategies
Sonnet 5 isn’t launching into a vacuum. Z.ai’s GLM 5.2, a 753-billion-parameter open-weight model released under an MIT license in mid-June 2026, prices its official API at $1.40 per million input tokens and $4.40 per million output tokens, and early independent benchmarks put it close to GPT-5.5 on several long-horizon coding tasks. That’s a real option for teams that are cost-sensitive and comfortable self-hosting or using a third-party host.
The practical effect is a routing strategy plenty of developers already run: send simple, high-volume tasks to a cheap open-weight model, reserve Opus-tier models for the hardest reasoning, and decide where Sonnet 5 fits in between. Its advantage isn’t raw price, GLM 5.2 wins that comparison easily. It’s the agentic polish Anthropic has invested in: planning, tool use, and self-checking behavior that a lot of open-weight models still handle less gracefully. Whether that’s worth the price gap depends on how much autonomy your workload actually needs.
12. Developer Playbook: When To Actually Use Sonnet 5
Putting all of this together, a few rules of thumb hold up:
- Use Claude Sonnet 5 at medium effort for bulk agentic work: codebase-wide scans, high-volume document processing, and parallel sub-agent tasks where Opus 4.8 would be overkill.
- Reserve Opus 4.8 for anything that needs deep, multi-step reasoning or hits the ceiling of what Sonnet 5 can do at high effort, especially under time pressure.
- Route dead-simple, high-volume tasks to a cheaper open-weight option like GLM 5.2 if your infrastructure supports it, and save Sonnet 5’s agentic strengths for work that benefits from them.
- For legitimate defensive cybersecurity work that needs reduced guardrails, apply through Anthropic’s Cyber Verification Program rather than expecting Sonnet 5 to handle it by default.
- Budget for the tokenizer change and the pricing reset landing together after August 31, not just one or the other.
13. Conclusion: A Genuinely Improved, Genuinely Mid-Tier Model
Claude Sonnet 5 is not a quietly nerfed downgrade, and it’s not a secret Opus 4.8 replacement either. It’s a real improvement over Sonnet 4.6 on the metrics that matter for agentic work, priced aggressively for a limited window, with a handful of tradeoffs Anthropic disclosed clearly enough that “buried” is generous: a heavier tokenizer, a personality that pushes back more than it flatters, weaker cybersecurity capability by design rather than defensive nerfing, and a genuinely interesting evaluation-awareness finding worth watching as future models scale further.
The most useful thing to do with Claude Sonnet 5 right now is treat it as what it is: a strong, cost-efficient mid-tier model for high-volume agentic work, not a universal upgrade. Match the effort level to the task, keep an eye on how the Fable 5 restoration reshapes Anthropic’s broader lineup, and check back with Binary Verse AI as the pricing reset and the rest of this story play out.
How does Claude Sonnet 5 compare to Opus 4.8?
Answer: While Anthropic markets Sonnet 5 as having “near-Opus” intelligence, actual benchmarks and cost-to-performance graphs show that pushing Sonnet 5 to “High” or “xHigh” reasoning effort makes it more expensive and less capable than simply using Opus 4.8 on “Low” or “Medium” effort. For complex tasks, Opus 4.8 remains the superior choice.
Why is Claude Sonnet 5 using up my usage limits so fast?
Answer: Claude Sonnet 5 introduces a new tokenizer that requires approximately 30% more tokens to process the exact same text compared to Sonnet 4.6. Additionally, the model utilizes a recursive internal loop, meaning it is much more verbose and burns through context windows faster, leading to quicker rate limits.
How much does Claude Sonnet 5 cost?
Answer: Through August 31, 2026, Sonnet 5 is offered at an introductory API price of $2 per million input tokens and $10 per million output tokens. After this date, Claude model pricing increases to $3 for input and $15 for output tokens per million.
What happened to Claude Fable 5 and Mythos 5?
Answer: According to the Claude Sonnet 5 System Card (page 60), Anthropic was forced to “de-deploy” Claude Fable 5 and Mythos 5 in response to US government export control directives due to their advanced, potentially dangerous capabilities in areas like cybersecurity.
What is the “wet blanket” personality in Sonnet 5?
Answer: In Anthropic’s own automated behavioral audits within the System Card, they note that Sonnet 5 scores higher on the “wet blanket” metric. This means the model frequently exhibits an “excessively discouraging, dismissive, or moralizing tone” toward the user compared to previous, friendlier iterations like Sonnet 4.5.