

Text generation has a speed problem that no amount of bigger hardware fully solves. Language models write one token at a time, and each token needs a full pass through the network. Output twice as long, wait twice as long. DSpark is DeepSeek’s attempt to break that pattern, and it does so without retraining a single weight of the model doing the talking.
Released as a speculative decoding framework attached to DeepSeek V4, DSpark targets the exact place where llm inference gets expensive: the serving layer, where thousands of users hit one model at the same time. The headline claim is that it pushes the throughput-versus-speed trade-off far enough to open service tiers that simply weren’t reachable before. Here’s what that means, what’s solid, and where the asterisks sit.
Table of Contents
1. What Is DSpark? DeepSeek’s Fix For The LLM Inference Bottleneck
If you’ve never met the idea, here’s what is speculative decoding in plain terms. You pair a small, fast “drafter” model with the large “target” model you actually trust. The drafter guesses a short run of upcoming tokens. The target model then checks all of those guesses in a single forward pass and keeps the longest correct prefix, plus one bonus token it generates itself. Because the math behind the acceptance step preserves the target’s output distribution exactly, you get a speedup with no quality loss. It’s lossless by design.
The catch is that the drafter’s design decides everything. Guess too slowly and you’ve gained nothing. Guess badly and the target rejects your tokens, so you’ve wasted compute. DSpark is a hybrid framework that tries to win on both fronts at once, combining a fast parallel drafter with a tiny sequential add-on and a smart scheduler that decides how much to verify.
DSpark: At a Glance
2. Why Older Drafters Hit A Wall
Every speculative decoding method before DSpark made a painful choice. DSpark’s whole pitch only makes sense once you see the three dead ends it walks around.
2.1 Eagle Speculative Decoding: Accurate But Slow
Eagle-style drafters are autoregressive. Each draft token conditions on the one before it, which makes them genuinely good at predicting coherent text. The problem is structural. Their drafting time grows linearly with block size, so to stay fast they’re forced into short blocks and shallow networks. The accuracy is there, but the latency tax caps how much speedup you can squeeze out. Anyone searching for eagle speculative decoding runs into this ceiling fast.
2.2 DFlash And The Multi-Modal Collision Problem
Parallel drafters like DFlash go the other way. They produce the whole block in one forward pass, so drafting time barely moves as the block grows. That lets them run deeper and propose longer drafts. But because every position is predicted independently, they can’t model how tokens depend on each other. The paper’s example says it best: faced with “of course” and “no problem” as plausible continuations, a parallel drafter can blurt out “of problem” or “no course.” This is multi-modal collision, and it causes acceptance to decay sharply toward the end of each block.
2.3 Why Single-Token MTP Stayed Stuck
DeepSeek’s own production baseline, MTP-1, sidestepped both issues by only ever drafting one token. Safe, but slow. The team kept it because larger static multi-token drafters (think MTP-3 or MTP-5) actually hurt aggregate throughput under heavy load. Verifying big blocks of low-confidence text burns batch capacity that other users need.
DSpark: Comparison of Speculative Decoding Drafters
3. The Semi-Autoregressive Trick That Powers DSpark
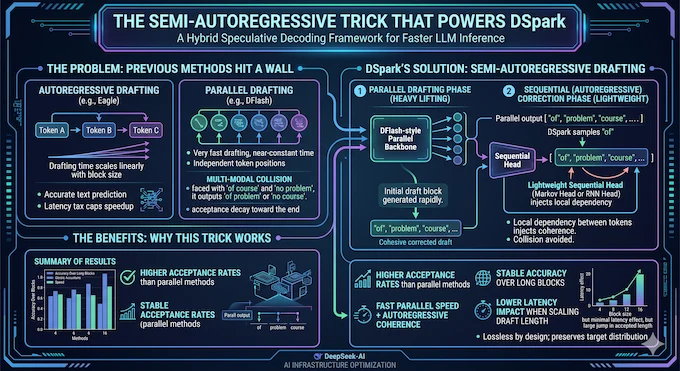
DSpark’s first move is an architecture that refuses to pick a side. It keeps the heavy lifting parallel, using a DFlash-style backbone to produce the whole block in one pass. Then it attaches a lightweight sequential head that injects local dependency between tokens, so each position can react to the one actually sampled before it.
The default version is a Markov head, which only looks at the immediately preceding token and uses a compact low-rank factorization to stay cheap. There’s also an RNN head that tracks the full prefix history within a block, but it adds complexity for only marginal extra gains, so the Markov head wins as the standard. Going back to the earlier example, once the drafter samples “of,” the Markov head boosts “course” and suppresses “problem” at the next position. Collision avoided.
The payoff is striking in the ablations. A two-layer DSpark beats a five-layer DFlash across every domain tested. A little autoregression, added in the right spot, buys more coherence than simply stacking more parallel layers. And the sequential loop is cheap enough that scaling the draft length from 4 to 16 tokens adds only 0.2% to 1.3% to full-round latency, while delivering up to a 30% jump in accepted length. That ratio is the heart of why DSpark works.
4. Confidence-Scheduled Verification: Verify Smarter, Not Longer
Generating great long drafts is only half the battle. Verifying all of them blindly is its own kind of waste, especially under high concurrency. This is the part of llm inference optimization that most drafters ignore, and it’s where DSpark earns its production credentials.
DSpark adds a confidence head that scores each draft position with the probability it will survive verification, given that everything before it was accepted. Raw neural confidence tends to run overconfident, so the team applies a calibration step called Sequential Temperature Scaling. It pulls the average calibration error down from a range of 3% to 8% to roughly 1%, which matters because the scheduler needs accurate magnitudes, not just rankings.
Those calibrated scores feed a hardware-aware prefix scheduler that treats verification length as a throughput maximization problem. It profiles the engine’s capacity once at startup, stores it as a cheap lookup table, then decides per request how many tokens are worth checking. Under light load it verifies more, since spare tokens are nearly free. Under heavy load it trims aggressively, pruning weak suffix tokens before they steal batch capacity from other users. A careful early-stopping rule keeps the whole thing lossless, so the target distribution is preserved exactly.
5. DeepSeek V4 Benchmark Results: How Much Faster Is It?
On controlled offline tests across math, code, and chat, DSpark consistently beats both baselines. Measured by accepted length per round, it improves on the autoregressive Eagle3 by 30.9%, 26.7%, and 30.0% across Qwen3-4B, 8B, and 14B, and on the parallel DFlash by 16.3%, 18.4%, and 18.3%. The gap widens as draft blocks get longer, exactly where DFlash’s suffix decay bites hardest.
The DeepSeek V4 benchmark numbers from live deployment are the real story, though. Against the MTP-1 baseline, DSpark accelerates per-user generation by 60% to 85% on V4-Flash and 57% to 78% on V4-Pro at matched throughput. At moderate service-level targets, aggregate throughput rises by about 51% (Flash) and 52% (Pro).
Now the asterisk. At very strict interactivity targets, the paper reports nominal throughput gains of 661% (Flash at 120 tokens per second per user) and 406% (Pro at 50). These look enormous, but the authors are honest that they reflect a regime where the single-token baseline nearly collapses, so the ratio balloons. They frame it as DSpark extending the feasible frontier, not as a typical 6x speedup over a healthy baseline. The mechanism behind all of it is visible in the scheduler’s behavior: it expands the verification budget from MTP-1’s static 2 tokens to roughly 4 to 6 per request when there’s room, then dials back smoothly as load climbs.
6. What Faster Inference Means For Costs
Translate the benchmarks into operating reality and the picture gets interesting. If one GPU pushes meaningfully more tokens at the same power and hardware draw, the cost per token falls in step. The 51% to 52% throughput gains at sensible service levels alone make a real dent in serving economics, before you even reach the more dramatic frontier-extending numbers.
That’s the strategic angle worth sitting with. DSpark doesn’t make the model smarter. It makes serving the model cheaper, which is precisely the bill that grows fastest as an AI product scales. For teams weighing open-weight routing against paying per token for a closed frontier model, efficiency work like this quietly tilts the math toward self-hosting. The paper’s own framing is that it shifts the Pareto frontier of LLM serving outward, and the cost story follows directly from that.
7. DeepSpec: Bringing DSpark To Qwen And Gemma
DSpark isn’t a closed party trick. DeepSeek validated it on Qwen3 (4B, 8B, and 14B) and on Gemma4-12B, showing the gains hold across model families, not just their own checkpoints. To back that up, they open-sourced DeepSpec, an algorithm-driven training repository that includes Eagle3, DFlash, and DSpark side by side.
That release matters more than a single model drop. A reproducible training stack for several drafter architectures gives researchers a fair bench to compare methods, and gives builders a path to attach DSpark-style drafting to other targets. As a general llm inference optimization tool rather than a DeepSeek-only feature, it has a real shot at becoming a default building block.
8. Running DSpark Locally With vLLM
The packaged model lives on Hugging Face as deepseek-ai/DeepSeek-V4-Pro-DSpark. It’s worth being precise about what it is: the same DeepSeek V4 checkpoint with a speculative decoding module attached, not a new base model. For anyone chasing vllm speculative decoding, the serving path is about as plain as it gets:
pip install vllm
vllm serve "deepseek-ai/DeepSeek-V4-Pro-DSpark"
From there you call the OpenAI-compatible endpoint at http://localhost:8000/v1/completions with a normal JSON payload. SGLang and Docker Model Runner are supported too, so you can slot it into most existing stacks without rebuilding your serving layer. The DSpark logic rides along inside the checkpoint, which is what keeps deployment this clean.
8.1 Can Consumer Hardware Handle It?
Here’s the reality check. The DSpark drafting module is genuinely lightweight, but the model it’s accelerating is not. DeepSeek V4-Pro carries 1.6T total parameters (49B active) at a one-million-token context, and even V4-Flash sits at 284B total (13B active). The speculative head barely moves your memory footprint, yet the base model demands serious, multi-GPU or high-memory infrastructure regardless. So DSpark lowers the cost of serving these models well, but it doesn’t shrink them onto a laptop. Plan your hardware around the target model first, then enjoy the drafter as a near-free accelerant on top.
9. The Limits, And The Bottom Line
DSpark is sharp, not magic. It still pays a fixed draft-side cost to generate that first block through the parallel backbone, and for genuinely hard prompts with low acceptance rates, that upfront compute is unrecoverable. The authors flag difficulty-aware early exiting as the obvious next step, letting tough requests skip full-block drafting. The eye-popping frontier multipliers also deserve the context the paper gives them, so read past the big percentages to the matched-throughput numbers for a fair read.
Even with those caveats, DSpark lands a clean result. It gives developers the raw speed of parallel drafting with the coherence of autoregressive drafting, wrapped in a scheduler that respects real server load. That combination is exactly what production llm inference has been missing, and it raises the baseline for what fast, affordable serving should look like.
Want more breakdowns like this, where we cut through the benchmark theater to the parts that actually change your stack? Keep following Binary Verse AI for hands-on analysis of the tools reshaping AI inference, and check our deep dives on DeepSeek V4 and speculative decoding to see where DSpark fits in the bigger picture.
What is speculative decoding in AI?
Answer: Speculative decoding is a technique for faster LLM inference. It uses a smaller, faster “draft” model to guess the next several tokens in a sequence. The larger, main “target” model then reviews and verifies all these guessed tokens in a single forward pass, dramatically speeding up generation times without losing quality.
What is DSpark and how does it optimize LLM inference?
Answer: DSpark is a new speculative decoding framework by DeepSeek. It optimizes LLM inference by using a “semi-autoregressive” draft model that combines parallel processing with sequential context, ensuring long drafts stay accurate. It also features a load-aware scheduler that dynamically cuts off bad drafts to prevent GPU hardware waste.
How much VRAM do I need to run DeepSeek V4 DSpark locally?
Answer: The DSpark speculative decoding module itself is extremely lightweight, adding roughly 1GB of VRAM overhead. However, the base target model (DeepSeek-V4-Pro) is a massive 1.6T parameter model. Running it locally requires enterprise hardware like an 8x NVIDIA DGX cluster or a dual Mac Studio setup with 512GB of unified memory.
How does DSpark compare to Eagle3 and DFlash speculative decoding?
Answer: DSpark bridges the gap between the two. Autoregressive drafters like Eagle3 are accurate but slow. Parallel drafters like DFlash are fast but hallucinate on longer sequences (multi-modal collision). DSpark’s semi-autoregressive approach achieves higher accuracy than Eagle3 and faster processing than DFlash.
Does DSpark work with vLLM and other open-source models?
Answer: Yes. DeepSeek open-sourced the training framework, called DeepSpec, which allows developers to apply DSpark’s speculative decoding to other open-source models. The research paper successfully benchmarked DSpark on Qwen3 and Gemma4, proving its cross-architecture compatibility.