

Sakana Fugu has arrived with the kind of claim that makes AI people immediately open three tabs and start arguing. Is it a new frontier model? Is it a wrapper? Is it just a router wearing a pufferfish costume?
The clean answer is this: Sakana Fugu is a learned LLM orchestrator delivered through a single model-like API. You send one request. It decides which frontier model, agent, or multi-agent workflow should handle the job. To the user, it feels like one model. Under the hood, it is a trained coordination system that routes, delegates, verifies, and synthesizes work across a pool of other powerful models.
That distinction matters. If Sakana is right, the next jump in AI performance may not come only from training bigger base models. It may come from learning how to combine the models we already have.
Table of Contents
1. What Is Sakana Fugu?
Sakana describes Fugu as a “multi-agent system, delivered as one model” on its official product page. The technical report is even more direct: Fugu is a family of orchestrator models trained to understand a user query and dynamically build an agentic scaffold over a team of LLM workers.
In plain English, Sakana Fugu is the conductor, not the whole orchestra. The musicians are frontier models such as GPT-5.5, Claude Opus 4.8, Gemini 3.1 Pro, and other specialist agents. Fugu’s job is to decide who should play, when they should play, and how the final answer should be assembled.
Sakana Fugu Quick Answers
| Question | Short Answer |
|---|---|
| What is Sakana Fugu? | A trained multi-agent orchestration system exposed as one API |
| Is it a standalone base model? | Not in the usual sense |
| Is it just a wrapper? | No, the report describes learned routing, scaffolding, verification, and synthesis |
| What is Fugu best for? | Coding, research, analysis, long reasoning, and complex multi-step tasks |
| What is Fugu Ultra? | A quality-first variant that coordinates deeper multi-agent workflows |
| How do developers access it? | Through an OpenAI-compatible API |
| Can users control the agent pool? | Regular Fugu allows provider/model opt-outs, Fugu Ultra uses a fixed full pool |
| Is it available in the EU/EEA? | Not currently, according to Sakana’s product page |
The important phrase is “trained orchestrator.” A static router follows hand-written rules. A learned orchestrator is trained to map a task to the model or workflow most likely to solve it well.
2. Is Sakana Fugu A Real AI Model Or An Orchestrator?
It is both, depending on what you mean by “model.”
For users, Sakana Fugu behaves like a model. You call one endpoint. You get one answer. You do not manually choose between GPT, Claude, Gemini, or a panel of agents.
Technically, though, it is better described as an LLM orchestrator. The technical report says Fugu constructs an agentic scaffold over a pool of frontier LLM workers, deciding which workers to involve, what instructions to assign, how outputs should be combined or verified, and when to synthesize the final answer.
That means the Reddit objection “this is not a base model” is mostly correct. But the follow-up claim “therefore it is not interesting” is much weaker. A compiler is not a CPU. A search engine is not the web. A good orchestrator can still be a major product if it makes the underlying pieces work better together.
Fugu’s bet is that many frontier models are uneven. One is better at math. One is better at debugging. One is better at long-context reasoning. One is better at careful synthesis. The system wins by knowing when to use which brain.
3. Fugu Vs Fugu Ultra
Sakana released two variants: Fugu and Fugu Ultra. The names sound like menu items. The difference is architecture and operating mode.
Fugu is optimized for everyday latency. The report says it selects a single worker per input, which keeps the coordination space small and response time closer to a direct model call. Fugu Ultra is optimized for answer quality. It composes workflows of multiple agents, uses deeper orchestration, and trades speed for better results on hard problems.
Sakana Fugu vs Fugu Ultra Comparison
| Feature | Fugu | Fugu Ultra |
|---|---|---|
| Main Goal | Balance quality and latency | Maximize answer quality |
| Best Use | Daily coding, review, chat, normal research | Hard reasoning, paper reproduction, cybersecurity, deep analysis |
| Orchestration Style | Selects one worker per input | Coordinates multiple expert agents |
| Latency | Lower | Higher |
| Agent Pool | Configurable opt-outs for regular Fugu | Fixed full pool |
| Pricing Model | Based on active underlying top-tier model, not stacked fees | Fixed token pricing |
| Good Default For | Interactive work | High-stakes, multi-step work |
The official pricing page lists Fugu Ultra at $5 per 1M input tokens, $30 per 1M output tokens, and $0.50 per 1M cached input tokens. Contexts above 272K tokens use higher rates: $10 input, $45 output, and $1 cached input.
Subscription tiers are also listed: Standard at $20 per month, Pro at $100 per month, and Max at $200 per month. Every tier includes access to both Fugu and Fugu Ultra.
4. How Sakana Fugu Works In Simple Words
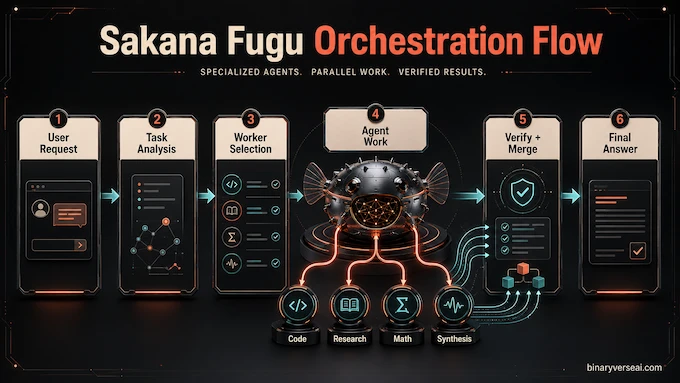
The simple workflow looks like this:
- You send one request.
- Fugu analyzes what kind of task it is.
- It chooses a worker model or designs a multi-agent workflow.
- The selected agent or agents work on subtasks.
- Fugu verifies, combines, or synthesizes the outputs.
- You receive one final answer.
The regular Fugu architecture is designed to be fast. It uses a lightweight selection head that operates on the orchestrator backbone’s hidden state. That head scores which worker model should handle the request. The clever part is that the orchestrator does not need to generate a long plan in text for every call. It can make a routing decision early, then dispatch the query.
Fugu Ultra is heavier and more interesting. It builds on Sakana’s Conductor work, where a model learns to design natural-language workflows for a team of agents. It can divide the problem, assign subtasks, control which agents see which intermediate results, and preserve workflow memory so agents do not collapse into copying each other.
This is why calling Sakana Fugu “just a wrapper” misses the point. A wrapper forwards a request. Fugu is trained to decide how the request should be solved.
5. Sakana Fugu Benchmarks: What The Scores Show
The Sakana Fugu benchmarks look strong, especially for Fugu Ultra. But they should be read as system-performance results, not as proof that Sakana trained a standalone model stronger than every frontier base model.
The official report says baseline scores are provider-reported wherever available. It also notes that Fable 5 and Mythos Preview are not in the Fugu agent pool because they are not publicly accessible.
Sakana Fugu Benchmark Scores
| Benchmark | Fugu | Fugu Ultra | Claude Opus 4.8 | Gemini 3.1 Pro | GPT-5.5 | Readout |
|---|---|---|---|---|---|---|
| SWE Bench Pro | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 | Fugu Ultra leads public baselines |
| Terminal Bench 2.1 | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 | Both Fugu models are strong |
| LiveCodeBench | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 | Fugu Ultra leads |
| LiveCodeBench Pro | 87.8 | 90.8 | 84.8 | 82.9 | 88.4 | Fugu Ultra leads |
| Humanity’s Last Exam | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 | Fugu Ultra edges Opus |
| CharXiv Reasoning | 85.1 | 86.6 | 84.2 | 83.3 | 84.1 | Fugu Ultra leads |
| GPQA Diamond | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 | Both Fugu variants lead |
| SciCode | 60.1 | 58.7 | 53.5 | 58.9 | 56.1 | Regular Fugu leads this row |
| τ³ Banking | 21.7 | 20.6 | 20.6 | 8.4 | 20.6 | Regular Fugu leads |
| Long Context Reasoning | 74.7 | 73.3 | 67.7 | 72.7 | 74.3 | Fugu slightly leads GPT |
| MRCRv2 | 86.6 | 93.6 | 87.9 | 84.9 | 94.8 | GPT-5.5 leads |
The most impressive results are in coding and scientific reasoning. Fugu Ultra scores 73.7 on SWE Bench Pro, 82.1 on Terminal Bench 2.1, 93.2 on LiveCodeBench, and 95.5 on GPQA Diamond. Those are not small wins if the setup holds under independent replication.
6. Are The Benchmark Comparisons Fair?
They are fair if the question is: “Which user-facing system gives the best answer?”
They are less fair if the question is: “Which standalone base model is smarter?”
That is the core distinction. Sakana Fugu may call or coordinate some of the same models it is compared against. It is a system-level benchmark. The product being tested is orchestration, not isolated weights. That does not invalidate the results, but it changes what they mean.
A skeptical reader should ask four questions:
- Which models were available in the agent pool?
- Were baseline scores reproduced under the same harness or taken from provider reports?
- How much extra latency and token usage did orchestration require?
- Does performance hold when users restrict providers for privacy or compliance?
The report is fairly transparent on some of this. It says Fugu orchestrates a pool that includes Gemini-3.1-Pro, Claude Opus 4.8, and GPT-5.5, while Fable 5 and Mythos Preview are not in the pool. Sakana also makes the practical argument that users care about final answer quality, not whether the intelligence came from one model or a coordinated team.
That is a reasonable product argument. It is not the same as a pure model leaderboard argument.
7. Why Reddit Is Debating Sakana Fugu
The debate is predictable because Fugu sits right on the fault line between “model” and “system.”
One side says it is not a real frontier model. That is right in the narrow sense. It is not mainly interesting because Sakana trained a giant standalone base model. It is interesting because Sakana trained a model to coordinate other models.
Another objection says it is just a wrapper. That feels too lazy. A wrapper is plumbing. Fugu’s technical report describes supervised fine-tuning over worker performance, evolutionary optimization on end-to-end tasks, reinforcement learning for workflow design, and persistent memory for multi-agent function calling. You can dislike the framing without pretending the architecture is a curl script in a trench coat.
The strongest criticism is benchmarking. If a system uses frontier models, comparing it to frontier models can feel circular. The fairest response is to label it clearly: these are user-facing orchestration results. They measure what happens when the whole Fugu system answers, not what a single Sakana base model knows.
That is exactly the comparison buyers care about, and exactly the comparison researchers should interpret carefully.
8. Sakana Fugu Pricing And API Access
Commercially, Sakana is trying to make orchestration easy to adopt. Fugu and Fugu Ultra are available through an OpenAI-compatible API, so developers can point existing clients or coding harnesses at the Fugu endpoint without rewriting their whole stack.
Pricing has two modes.
Subscriptions are aimed at hands-on users:
- Standard: $20 per month for lightweight daily use
- Pro: $100 per month for regular coding, review, research, and analysis
- Max: $200 per month for heavier long-running workloads
Pay-as-you-go is aimed at production workloads. For regular Fugu, the pricing depends on the active agent pool. If one agent is used, you pay that underlying model’s standard rate. If multiple agents are active, Sakana says it does not stack fees. You pay one rate based on the top-tier model involved.
Fugu Ultra has fixed pricing: $5 input, $30 output, and $0.50 cached input per 1M tokens. Above 272K context, that rises to $10 input, $45 output, and $1 cached input.
The catch is that orchestration tokens count too. The pricing page says orchestration input and output tokens are real token usage and are included in final request price. Translation: do not assume the visible answer is the whole bill.
9. Fugu Vs OpenRouter Fusion And Other LLM Orchestration Tools
Sakana Fugu belongs to a wider category: LLM orchestration. The category is still messy, but the patterns are clear.
A model router chooses one model for a request. A council or ensemble asks multiple models and compares answers. An agent framework lets developers design workflows by hand. OpenRouter Fusion-style products combine multiple model outputs behind one interface.
Fugu’s claim is more specific: the orchestration itself is learned. The system is trained to select, coordinate, and synthesize. It tries to hide the hard parts behind one model-like API, while still using a pool of specialist agents.
That is appealing because most developers do not want to handcraft a routing graph for every task. They want the right model to show up at the right time, ideally without a whiteboard séance.
The risk is opacity. If the orchestrator makes a bad call, debugging may be harder than with a simple, visible workflow. Teams using Fugu for production should log model choices, usage fields, latency, and failure cases carefully.
10. Who Should Use Sakana Fugu?
Developers should care, especially if they work on coding agents, review tools, debugging assistants, or research automation. Fugu looks particularly relevant for workflows where different subtasks reward different model strengths.
AI researchers should care because Fugu is a concrete example of orchestration as a scaling axis. It suggests a way to improve system capability without training one giant model from scratch.
Security teams may care, but carefully. Fugu Ultra’s deeper agent workflows could help with scoped analysis and verification, but security workflows need strong controls, logging, and provider policy review.
Casual chatbot users may not need it. If the task is simple, orchestration may be overkill. A fast single model is often enough.
Local and self-hosting users probably should not get excited unless they are comfortable with API-based systems. This is not a local open-weight model release.
EU and EEA users also need to wait, because Sakana’s page says the product is not currently available there while the company works toward GDPR and regional compliance.
11. Why Sakana Fugu Matters Even If It Is Not A Base Model
The easy take is that Sakana Fugu is not a “real” model because it depends on other models. The better take is that this may be exactly why it matters.
AI progress has been dominated by a simple story: bigger training run, better model. Fugu points at a second story: better coordination, better system. If frontier models keep specializing, then the hard problem becomes choosing the right expert at the right moment and combining answers without turning the result into committee soup.
That is not a small problem. It is the same challenge human organizations face. The genius of a lab is not only whether it hires brilliant people. It is whether those people can collaborate without wasting each other’s time.
Sakana Fugu is not a final answer. The benchmarks need independent scrutiny. The cost model needs real-world testing. The latency tradeoffs matter. The provider-dependency question is real. But dismissing it as “just a wrapper” misses the architecture trend.
The future of AI may look less like one giant model sitting on a throne and more like a trained coordinator directing a shifting team of specialist agents.
That is the real reason to watch Fugu. Not because it kills GPT, Claude, or Gemini. Because it makes them ingredients.
For more model breakdowns, benchmark reality checks, and developer-focused AI analysis, keep following Binary Verse AI. The next frontier may not be the smartest single model. It may be the system that knows how to use them all.
1. What is Sakana Fugu?
Sakana Fugu is a multi-agent AI system from Sakana AI that works through a single model-style API. Instead of relying on one standalone model, it uses learned orchestration to route, coordinate, and combine work from multiple frontier LLM agents.
2. Is Sakana Fugu a real AI model or an orchestrator?
Sakana Fugu behaves like one model to the user, but technically its main innovation is orchestration. It is a trained LLM orchestrator that decides which worker models to use, how to structure the task, and how to synthesize the final answer.
3. What is an LLM orchestrator?
An LLM orchestrator is a system that manages one or more language models for a task. It may choose the best model, split work into subtasks, call tools, compare outputs, verify answers, and combine results into one final response.
4. What is an example of LLM orchestration?
Sakana Fugu is an example of LLM orchestration. A user sends one prompt, but Fugu can internally route the task to different models or coordinate multiple agents before returning a single final answer.
5. Which LLM orchestration is best?
There is no single best LLM orchestration system for every use case. Sakana Fugu is designed for users who want orchestration hidden behind one API, while frameworks like LangChain-style systems are better for developers who want to manually design and control the workflo