

Introduction
People love the idea of a single finish line called “AGI.” One morning you wake up, open your laptop, and the machine on the other side has “arrived,” it writes proofs, plans projects, designs hardware, and stays useful without constant babysitting.
That picture sells. The real argument is messier and more important. It’s about what we mean when we say “general,” what we can build under finite compute, and which research bets are worth a decade of focus.
That’s why the phrase General intelligence vs universal intelligence matters. It sounds like vocabulary drama. It’s not. Definitions steer evaluation, funding, hiring, and the stories executives tell themselves. When Yann LeCun and Demis Hassabis talk past each other, the subtext is a real fork: scale today’s paradigm harder, or pivot toward world-model-centric systems that learn by interacting.
Before we argue, let’s anchor the terms.
General intelligence vs universal intelligence, Key Terms
Fast definitions, debate implications, and the most common traps.
| Term | Plain-English Meaning | What It Usually Implies In Debates | Common Pitfall |
|---|---|---|---|
| AGI Artificial general intelligence | A system that can do a wide range of intellectual tasks at a high level | “Human-level” competence across many domains | People treat it like a single on/off milestone |
| GI General intelligence | Breadth of capability and transfer across tasks | Reuse skills, learn new things faster | Gets conflated with “optimal at everything” |
| UI Universal intelligence | A theoretical ideal that is optimal across all possible environments | “Perfect” prediction and decision-making | It’s elegant and computationally impossible |
| Turing Turing AGI | Generality framed through computability, “learn any computable task in principle” | A Turing-machine flavored notion of scope | “Computable” says nothing about efficiency or reliability |
| ASI Artificial super intelligence | Systems that surpass humans across most cognitive domains | Capability that keeps climbing past humans | People jump there without a bridge |
Tip, when you see claims framed as “universal,” ask what assumptions are being made about time, data, and compute. That usually reveals the real disagreement.
Table of Contents
1. The One-Sentence Disagreement And Why It Isn’t Just “Semantics”

Here’s the cleanest summary of General intelligence vs universal intelligence in one sentence.
LeCun: “Calling human-level intelligence ‘general’ is sloppy, humans are specialized, and universal intelligence is impossible anyway.”
Hassabis: “You’re mixing up general with universal, general means learn any computable task in principle, not be optimal at every task.”
Both sentences can be true, which is why the debate survives. The fight is about which framing produces useful engineering constraints. If your definition quietly assumes unlimited time, data, and memory, you can “win” by definition while building nothing robust.
2. Fast Definitions: AGI, GI, Universal Intelligence And The Tax-AGI Trap
Let’s get the low comedy out of the way. When people say “AGI” in this argument, they mean artificial general intelligence, not “adjusted gross income.” No one is debating the IRS.
Now the useful split:
2.1. Artificial General Intelligence As A Product Claim
In industry, “AGI” often means “a model that can replace or multiply many knowledge-worker roles without constant oversight.” That’s where people ask for Artificial general intelligence examples, like “can it do tax prep, write code, plan a trip, and debug a server?”
2.2. General Intelligence As Transfer Under Constraints
General intelligence, in an engineering sense, is transfer. You learn one thing, and it helps you learn the next thing faster. You don’t need perfection. You need reuse under cost, latency, and reliability constraints.
2.3. Universal Intelligence As A Theoretical Ceiling
Universal intelligence is the unattainable ideal where an agent is optimal across all possible environments. It’s where Solomonoff-style predictors live. Beautiful, unusable at real compute budgets.
That’s the core of General intelligence vs universal intelligence. General is about breadth in the real world. Universal is about optimality across an infinite space of worlds.
3. LeCun’s Core Claim: “General” Is A Misnomer Because Humans Are Specialized
LeCun’s argument lands harder when you translate it into biology and systems design.
Humans feel “general” because we’re inside our own competence bubble. We can solve the problems we can imagine, and we struggle to imagine the problems we can’t. That creates an illusion of generality. We’re not good at everything, we’re good at the slice of reality our species had to master.
3.1. Human-Level Isn’t A Synonym For General
Humans are great at navigating physical space, reading social cues, and learning from sparse experience. We’re also bad at brute-force search and doing exact math in our heads. A chess engine or a calculator beats you. That mismatch breaks the idea that “human” is a clean target distribution.
3.2. The Critique Of The LLM-Only Path
LeCun’s sharper claim isn’t only “humans are specialized.” It’s that scaling large language models, alone, is an off-ramp from the kind of intelligence that plans, acts, and grounds concepts in the physical world.
In his framing, intelligence is less about producing the next plausible sentence and more about predicting consequences, choosing actions, and building internal abstractions that survive contact with reality.
If that’s true, then General intelligence vs universal intelligence becomes a warning label: don’t sell a text model as a general mind just because it’s fluent.
4. Hassabis’s Core Claim: “General” Isn’t “Universal,” And Generality Is Turing-Flavored
Hassabis pushes back with a computer science instinct. He points to the idea behind Alan Turing’s framing in Computing Machinery and Intelligence: if a task is computable, then there exists a procedure that can solve it, at least in principle.
That “in principle” matters, and it’s where Turing AGI sneaks in.
4.1. Approximate Turing Machines In Plain Language
A Turing machine is a theoretical device that can implement any computable algorithm with enough time and memory. Hassabis’s move is to treat brains, and modern foundation models, as approximate versions of that idea. Not infinite, not perfect, but structurally general.
So “general” means: with the right learning dynamics and enough resources, the same underlying architecture can learn chess, quantum physics, or airplane design. Humans weren’t evolved for those tasks, yet we do them anyway. That’s evidence of breadth.
4.2. Scope Without A Blank Check
Hassabis doesn’t deny constraints. Finite systems have to specialize around the distributions they learn. He refuses to equate “not optimal everywhere” with “not general.”
This is the heart of General intelligence vs universal intelligence from his side. Universal is optimality. General is scope.
5. The No Free Lunch Theorem: What It Actually Means For Real-World Intelligence
The No Free Lunch theorem gets used online like a mathematical mic drop. It’s not.
NFL says that averaged over all possible problems, no learning algorithm outperforms any other. If you demand optimal performance across the space of all conceivable tasks, you lose. Every learner must have inductive biases, and biases mean you do better on some families of problems and worse on others.
So NFL separates the two goals:
- Universal intelligence, meaning “optimal across everything,” is blocked.
- General intelligence, meaning “capable across many relevant environments,” stays on the table.
That distinction is why General intelligence vs universal intelligence isn’t wordplay. It’s the difference between an impossible goal and a brutal engineering goal.
6. Why “Turing-Complete” Doesn’t Automatically Mean “Intelligent”
A recurring category error is: “If a model is Turing-complete, it can do anything, so it’s intelligent.”
No.
Turing-complete means a system can represent any computation, given unlimited resources. It says nothing about learning that computation from data. It says nothing about sample efficiency. It says nothing about robustness when inputs shift.
Intelligence is competence under constraints. The gap between “can represent” and “can learn efficiently” is where most hype burns out.
This is also where AGI vs ASI gets muddled. People smuggle artificial super intelligence into the room by pointing at computational universality, then act surprised when reality asks for data, memory, and time.
7. The Real Technical Fault Line: World Models, Causality, And Planning Vs Next-Token Prediction
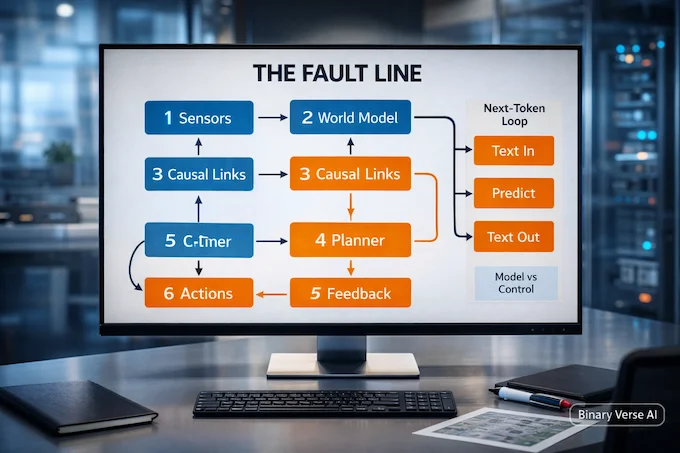
Strip away the tweets and you get a concrete engineering question: what internal machinery lets a system plan over long horizons in messy environments?
7.1. World Models As Prediction Of Consequences
A world model, in the useful sense, isn’t a Hollywood simulator that recreates every pixel. It’s a stack of abstractions that predicts the parts of reality that matter for action. Physicists don’t simulate every molecule to predict a planet’s orbit. They choose the right state variables and throw away entropy.
LeCun’s world-model emphasis is a bet that abstraction-first prediction is the missing ingredient for robust generalization.
7.2. Next-Token Prediction As A Tool, Not A Mind
LLMs are astonishing at language because language compresses human experience. But compression isn’t grounding. Next-token prediction optimizes for plausibility in text space. Planning requires causal structure, counterfactual reasoning, and the ability to test actions against predicted futures.
You can bolt tools and scaffolds onto an LLM and get impressive behavior. The debate is whether that route scales to robust competence, or whether it hits a wall of brittleness and data hunger.
That’s the technical center of General intelligence vs universal intelligence. It’s not “can it talk.” It’s “can it model and control.”
8. Are LLMs An Off-Ramp Or A Component? The Strongest Steelman Of Both Sides
The productive way to read this dispute is as two different failure modes being avoided.
8.1. The Best Pro-LeCun Case
If the goal is an agent that can operate in the physical world, purely text-trained systems will always be missing crucial structure. They can mimic explanations of physics without learning physics. They can answer object-permanence questions without having object permanence.
In this view, LLMs are excellent interfaces and assistants, but they aren’t the engine of agency. Betting exclusively on scaling them is betting on the wrong bottleneck.
8.2. The Best Pro-Hassabis Case
If you can build a single general-purpose architecture that absorbs modalities, uses tools, improves with interaction, and keeps extending its competence, then “general” is about the template, not the dataset. Today’s models are early approximations. Tomorrow’s will fold in better learning signals, better memory, and better evaluation, while still benefiting from scaling.
The overlap is bigger than the shouting suggests. Both sides want systems that learn abstractions, plan, and behave reliably. They disagree about whether the transformer-LLM lineage is the main road or a side road.
And yes, this is still General intelligence vs universal intelligence, because the moment you say “finite system,” you’re negotiating where specialization lives.
9. AI Bottlenecks: Data, Compute, Memory, And Evaluation
AGI arguments often dodge bottlenecks, which is like arguing about rockets while refusing to talk about fuel.
- Data: Text is huge, but it’s thin. Interaction data is smaller in hours, richer in structure.
- Compute and memory: Finite budgets force tradeoffs. Universal intelligence collapses here. General intelligence is about spending wisely to maximize transfer.
- Evaluation: We measure what’s convenient. Long-horizon planning, grounded reasoning, and OOD behavior are still hard to score at scale.
This is why General intelligence vs universal intelligence becomes an evaluation problem. Universal is unmeasurable in practice. General can be measured, but only if we stop treating fluent answers as competence.
10. What Would Actually Settle The Debate? Concrete Tests And Falsifiable Predictions

If you want to end the argument, don’t demand a philosophical confession. Demand a test suite.
10.1. Long-Horizon Planning Under Uncertainty
Drop an agent into a partially observable environment where it must explore, learn dynamics, and plan. Measure success rate, safety, and sample efficiency.
10.2. Out-Of-Distribution Transfer
Train on one family of tasks, then shift the distribution. Measure how quickly it adapts, and how gracefully it fails.
10.3. Grounded Causality
Ask counterfactual questions that require a causal model. Not “what usually happens,” but “what happens if I change this mechanism.”
Here’s a practical scoreboard of what would persuade each camp.
General intelligence vs universal intelligence, Evidence That Ends The Debate
What would actually change minds on both sides, framed as falsifiable evidence.
| Evidence Type | Would Move A LeCun-Style Skeptic | Would Move A Hassabis-Style Optimist |
|---|---|---|
| Evidence Robust embodied competence from interaction, not massive text memorization | Strong signal that world-model learning works | Confirms general architectures can absorb grounding |
| Evidence OOD transfer with small data and stable behavior under shift | Proves “general” isn’t just dataset matching | Shows practical generality, not just theoretical scope |
| Evidence Planning with explicit prediction of consequences and constraint satisfaction | Validates “intelligence as control” | Supports scalable agency without brittle hacks |
| Evidence Clear scaling limits for LLM-only systems on grounding-heavy tasks | Confirms off-ramp diagnosis | Forces architectural evolution beyond pure language |
If you want this table to drive more clicks from featured snippets, consider adding one sentence above it that defines OOD as “out-of-distribution.”
11. Industry Implications: Where The Money Goes If LeCun Is Right Vs If Hassabis Is Right
This argument already shapes budgets. If LeCun is right, the next decade pushes toward interaction learning, world models, and architectures built for continuous, high-dimensional signals. You invest in robotics, simulation-to-real transfer, representation learning that avoids naive pixel reconstruction, and planning systems that satisfy safety constraints by design.
If Hassabis is right, the scaling story continues, but it matures. Tool use, memory, better post-training, and tougher evaluations become the main levers. The model becomes an operating system for cognition, and “general” means you keep adding competencies without rewriting the core.
Either way, the endgame people whisper about, artificial super intelligence, isn’t the next step after a clever prompt. It’s the far end of a pipeline that must survive data limits, compute limits, and the fact that reliability is expensive.
12. Bottom Line: A Clean Way To Talk About “AGI” Without Talking Past Each Other
Here’s a vocabulary upgrade that dissolves most confusion.
- Use “universal intelligence” only for the theoretical ideal of optimality across all environments.
- Use “general intelligence” for broad transfer under finite resources.
- Use “human-level” when you literally mean “as good as humans at the things humans are good at.”
- Use “AGI” as a product claim only when you can specify reliability, cost, and task scope.
Once you adopt that language, General intelligence vs universal intelligence stops being a tribal chant and becomes a design constraint. It forces the questions that matter: What distribution are we targeting. What inductive biases are we baking in. What failures are acceptable. What tests would convince us we’re wrong.
That’s the real value of the LeCun-Hassabis clash. It’s a reminder that the word “general” can hide lazy thinking. It can also point at a real engineering dream, building systems that learn, adapt, and plan across the messy variety of the world.
If you’re building or buying AI this year, take the debate personally. Pick your definition, then pick your metrics, then pick your research bets. If your team can’t articulate which side of General intelligence vs universal intelligence they’re optimizing for, you’re not doing strategy, you’re doing vibes.
Now do the useful thing. Tighten the words you use. Pressure-test your roadmap against the bottlenecks. Then share this piece with the one person in your org who keeps saying “AGI is coming” without defining what they mean. That conversation is where progress starts.
What is the difference between intelligence and general intelligence?
Intelligence is the ability to solve problems or achieve goals. General intelligence means you can learn new skills and transfer them across many domains, not just perform one narrow task. In AI, this usually implies adaptability, broad transfer, and stable performance when the problem changes.
What are the two types of general intelligence?
People commonly mean two different things:
Theoretical generality: in a Turing-style sense, a system can learn any computable task given enough time, data, and memory (this is where “Turing AGI” language shows up).
Practical generality: the system transfers well under finite resources, like limited compute, limited data, and real deadlines.
What’s the difference between AI and GI (general intelligence)?
AI is any system that performs tasks we associate with intelligence, including narrow systems. GI implies breadth: the ability to handle many domains, adapt quickly, and reuse learning instead of restarting from scratch. Most modern products are AI, but only some aim at GI or artificial general intelligence.
What is an example of general intelligence?
Humans are the canonical example because we transfer learning across radically different tasks, like language, tools, math, and engineering, under strict limits on memory and time. In discussions of artificial general intelligence examples, the bar is usually “human-level breadth plus reliable transfer,” not a single benchmark win.
What is the difference between general intelligence and universal intelligence?
Universal intelligence is often used in a formal, theoretical sense (notably in academic definitions) and can drift toward “optimal across all environments,” which runs into No Free Lunch style limits. General intelligence is closer to “capable across many tasks and distributions,” even if not optimal. This is the heart of the AGI vs ASI confusion too: ASI implies beyond-human capability, while “universal” often implies a kind of unattainable optimality.