

Introduction
Everyone wants “agents” that can look things up, chain multiple steps, and feel like a junior researcher who never sleeps. The annoying part is what it takes to get there: piles of hand-curated instruction data, constant refresh cycles, and an endless debate about what counts as “good” supervision.
Meta Dr. Zero tries a different trade. Instead of feeding an agent more human-written examples, it builds a feedback loop where the model invents its own questions, solves them with a search tool, and then uses that signal to get better. The paper is “Dr. Zero: Self-Evolving Search Agents without Training Data” (arXiv:2601.07055), with code released alongside it.
The important nuance: Meta Dr. Zero is not a new foundation model. It’s a training recipe that turns an existing LLM into a stronger search agent by creating an automated curriculum.
Table of Contents
1. What Is Meta Dr. Zero (And What It Is Not)
Quick disambiguation.
- Meta Dr. Zero is a proposer-solver framework where both roles can call an external search engine, and both start from the same base LLM.
- It is not “no pretraining.” The base model still exists, you’re just not using a curated, human-made post-training QA dataset for this phase.
- It is not “no external knowledge.” The experiments run against an indexed English Wikipedia corpus with a fixed retriever and exact-match scoring.
1.1 TLDR, The Paper In 10 Lines
- Copy a base model into two roles, proposer and solver.
- Give both a retrieval tool.
- Proposer generates question-answer pairs.
- Solver tries to answer using multi-turn search.
- Proposer is rewarded for “hard but solvable” questions, not trivial, not impossible.
- Proposer training is normally expensive because you need many solver samples.
- HRPO groups questions by hop count to stabilize and cheapen advantage estimates.
- Train proposer briefly, generate synthetic QA, train solver briefly.
- Repeat for a few iterations, then performance plateaus.
- Evaluate on one-hop and multi-hop QA benchmarks using the same retriever setup.
1.2 Table: Meta Dr. Zero At A Glance
Meta Dr. Zero: Core Loop Components
A compact view of the proposer-solver system and the efficiency trick behind HRPO.
| Piece | What It Does | Why It Matters |
|---|---|---|
| Proposer | Writes QA tasks with search | Creates an automated curriculum instead of relying on human prompts |
| Solver | Solves tasks with multi-turn retrieval | Learns tool use and reasoning from synthetic data |
| Difficulty reward | Prefers “challenging but verifiable” | Pushes beyond trivial one-hop questions |
| HRPO | Hop-grouped baselines | Cuts compute and improves stability |
2. Dr. Zero Self-Evolving Search Agents

The main thing to understand is the loop. The proposer proposes. The solver solves. Then both update. The curriculum tightens automatically because once the solver gets good at easy questions, those questions stop paying the proposer.
Here’s the loop in one screen:
Proposer -> (Q, A) -> Solver -> answers with Search Tool -> reward signal | | +—————— HRPO update ————————+ and GRPO update for solver
That “proposer solver loop” framing matters because it changes how you think about tool-using AI agent training. You’re not only prompting an agent to call tools. You’re training it in a setting where tool calls are part of the behavior being reinforced.
2.1 Proposer Role: Hard But Solvable
The proposer’s job is to generate questions where the solver is neither bored nor doomed. The paper defines proposer reward over multiple sampled solver attempts, and explicitly treats “all correct” as too easy and “all wrong” as too hard.
They also add a format reward to keep generations structured, including valid tool usage and extractable question and answer fields.
2.2 Solver Role: Multi-Turn Tool Use And Reasoning
Solver training is simpler: sample QA from the proposer and optimize the solver with GRPO using an outcome-based reward tied to final answer correctness.
This is why the framework can act like a “multi-hop search agent” training pipeline. As the proposer increases hop complexity, the solver is forced to learn longer retrieval-reasoning chains, instead of plateauing on short trivia.
3. Dr. Zero Without Training Data Meaning
This is where readers get tripped up, so let’s be blunt.
Meta Dr. Zero does not claim you can build an intelligent model from nothing. It claims you can eliminate human-curated questions and annotated answers for this agent-training stage, and lean on a search engine to generate supervision signals.
3.1 Truth Box
- Zero data means: no demonstrations, no human-written QA dataset, no labeled answers in the training loop.
- Still required: a base LLM, a corpus to search, and an evaluation protocol.
- Still supervision: exact-match scoring against synthesized ground truth answers.
If you’ve ever built a retrieval system, you’ll recognize the philosophy: shift effort from labeling to building a reliable, verifiable environment.
4. Hop-Grouped Relative Policy Optimization (HRPO)
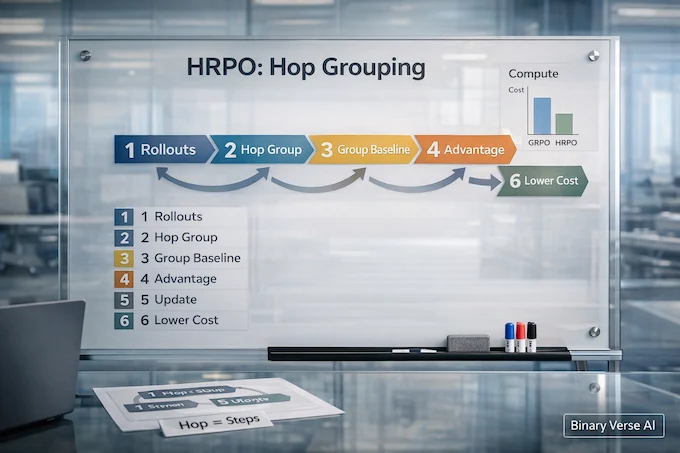
Proposer training is the expensive part because scoring “question quality” needs multiple solver attempts. In a tool-using setting, every attempt is a multi-turn rollout, which makes nested sampling ugly fast.
HRPO is the paper’s compute lever.
4.1 Why Hop Grouping Works
Instead of sampling many questions per prompt to get a group baseline, HRPO groups across the batch by hop count. It treats hop count as a structural bucket, then standardizes rewards inside that bucket to compute advantages.
That’s it. No mysticism. Just “compare similar things,” because a global baseline gets unstable when one batch mixes 1-hop and 4-hop trajectories.
4.2 The Difficulty-Guided Reward, In Plain English
Let k be how many solver attempts are correct out of n. Reward is only non-zero when 0 < k < n, and it peaks when exactly one attempt is correct.
So the proposer is paid to sit right at the frontier of solver capability. That’s a neat trick for keeping question difficulty moving upward without a human curator.
4.3 Curriculum Shape, The Hop Ratio Detail People Skip
The paper doesn’t just say “use multi-hop.” It actually tests different mixtures of 1/2/3/4-hop questions. With their default 4:3:2:1 ratio, the 3B setup reaches its best reported average among the tested mixes, and the authors note an interesting scaling split: smaller models benefit a lot from strengthening basic search skills, while larger models get more out of a tougher multi-hop curriculum.
That’s a practical knob if you’re adapting Meta Dr. Zero to your own domain. If your base model is small, don’t over-index on “make everything 4-hop.” Build competence first, then add depth.
5. Does It Actually Work, What The Results Claim
The paper evaluates on seven QA datasets, three one-hop and four multi-hop, using the same Wikipedia corpus and retriever setup across methods.
On Qwen2.5-3B-Instruct, Meta Dr. Zero lands at 0.326 average, essentially tied with supervised Search-R1 at 0.327, while beating it on some single-hop datasets in that table.
On Qwen2.5-7B-Instruct, Search-R1 remains stronger on average (0.384 vs 0.372), but Meta Dr. Zero stays competitive given the “no curated training set” constraint.
They also compare to other data-free baselines extended with search capability (SQLM* and R-Zero*), where Meta Dr. Zero performs best in their reported setup.
Two practical caveats the paper itself flags:
- Training typically peaks after 2 to 3 iterations, then stalls.
- Instability exists, including failure modes tied to inconsistent token IDs across multi-turn steps.
6. The Biggest Critiques From Threads, Answered Honestly
6.1 Verification And Retrieval Quality
If retrieval is noisy, the solver can get led astray, and the loop can reinforce bad habits. The experiments use ANN retrieval over an indexed corpus and return top-3 passages. That’s a solid baseline, but it doesn’t solve adversarial or messy corpora.
If you adapt Meta Dr. Zero to a real enterprise index, don’t treat retrieval as “plumbing.” Treat it as a model component, version it, monitor it, and test it.
6.2 Drift, Reward Hacking, And “The Loop Eats Itself”
Self-evolving systems can exploit loopholes. The authors explicitly call out reward hacking and bias amplification as concerns to address.
The format reward is a simple, underrated stabilizer. It forces valid tool calls and keeps the generated QA structure extractable, which helps prevent the proposer from devolving into unparseable chaos.
6.3 How I’d Harden It
Without changing the research idea, you can make the loop safer:
- Log every tool call, query, and retrieved passage.
- Add retrieval canaries, inject known distractors and ensure the solver doesn’t confidently cite them.
- Stop training when diversity collapses or when reward spikes look like hacking, not learning.
7. Practical Compute And Infra Reality
In the appendix, the training recipe is deliberately short: 50 steps of proposer training, generate QA, 50 steps of solver training, repeat, and stop after about three iterations.
That design choice is telling. The authors are optimizing for a loop you can actually run, because tool rollouts are the real cost center in this setting.
If you remember one infra point, remember this: Meta Dr. Zero is as fast as your slowest retrieval call.
8. Repo Walkthrough: How To Run Meta Dr. Zero
Start with the official repository and the paper’s pointer to it: https://github.com/facebookresearch/drzero.
The preprint lives at https://arxiv.org/abs/2601.07055.
And as requested, here’s the navigational phrase exactly once: facebookresearch drzero GitHub.
8.1 Minimal Reproduction Checklist
- Build an English Wikipedia index and serve retrieval. The paper uses E5 base embeddings and ANN retrieval of top-3 passages.
- Run the alternating loop: proposer update with HRPO, synthesize QA, solver update with GRPO.
- Keep iterations small. The authors stop at three.
8.2 What “Multi-Turn” Actually Means In Practice
The proposer is instructed to build questions by chaining hops through search, and the template is strict: Hop 1 must appear in the source, every later hop must be supported by search results, and the question should only mention Hop 1 so the solver has to discover the chain.
If you’re debugging generations, these are the rules that tell you whether the loop is learning or just roleplaying:
- Exact search count for n hops is n-1 tool calls.
- No spoilers about intermediate hops in the question.
- Each hop must depend on the previous one, no skipping.
9. Comparisons: Dr. Zero vs Search-R1 vs R-Zero (And The “R-Zero” Confusion)

Dr. Zero is compared against both supervised search agents and data-free baselines, all evaluated with the same corpus and retriever in the paper’s experimental setup.
9.1 Table: Who Needs What, And Why
Meta Dr. Zero: System Comparison
Compare data needs, tool use, training signal, and the key novelty.
| System | Curated Training Data | Tool Use | Main Training Signal | What’s New Here |
|---|---|---|---|---|
| Meta Dr. Zero | No | Yes | Difficulty-shaped proposer reward + solver correctness | HRPO hop grouping for efficiency |
| Search-R1 | Yes | Yes | Supervised + RL baseline in the paper | Strong reference point |
| R-Zero* | No | Adapted with search for comparison | Data-free co-evolution baseline | Not optimized for tool-rollout cost |
| SQLM* | No | Adapted with search for comparison | Self-questioning baseline | Weaker on average in their table |
If you’re seeing “Agent0” in the same neighborhood, treat it as adjacent work. The Dr. Zero paper doesn’t benchmark against it directly, so don’t mix scoreboards.
10. Where Meta Dr. Zero Helps, And Where It Doesn’t
10.1 Five Places This Actually Fits
- Citation-grounded QA over a fixed corpus.
- Enterprise knowledge search where you need audit logs.
- Research assistants that must learn multi-step retrieval behavior.
- Compliance QA where the answer must match policy text.
- Support agents that navigate docs instead of improvising.
In each case, Meta Dr. Zero earns its keep by making agent improvement feel like a training loop, not a prompt-writing hobby.
10.2 When Not To Use It
- When the corpus is untrusted or messy, because retrieval poisoning is real.
- When latency is expensive, because rollouts multiply it.
- When your target task can’t be verified cleanly, because this loop leans on verifiability.
11. License, Safety, And How To Think About Shipping It
The repo is released under a non-commercial license, so plan accordingly before you build a product around it.
Safety-wise, the authors point to reward hacking and bias amplification as future concerns. That’s not academic hand-wraving. It’s a reminder that a self-evolving system will find shortcuts if you leave them open.
Here’s the practical way to end: if you’re building search agents, try Meta Dr. Zero on a constrained internal corpus, keep it offline, instrument everything, and watch where it fails. The failures will teach you more than the wins.
If you do run it, start small, one domain, one index, one evaluation slice, and then scale only after the loop behaves. That’s how this idea becomes more than a cool arXiv tab.
What is Meta Dr. Zero, in plain English?
Meta Dr. Zero is a training loop that turns a base LLM into a better search agent by having it generate questions, solve them with retrieval, and learn from the results. It’s more like an automated curriculum engine than a new model.
Is Dr. Zero really “trained without training data,” or is that misleading?
It’s “without training data” in the sense that it avoids human-curated SFT-style post-training datasets for this stage. But it still relies on a base pretrained model and an external search corpus, so it’s not “learning from nothing.”
How does the proposer-solver loop work, and why is it like a self-made curriculum?
One model role (the proposer) generates questions designed to be hard but solvable. Another role (the solver) answers them using a search tool. As the solver improves, the proposer is pushed to generate tougher questions, so difficulty ratchets up automatically like a curriculum that writes itself.
What is HRPO, and how does it reduce compute compared to GRPO-style training?
Hop-grouped relative policy optimization (HRPO) groups questions by “hop” complexity and builds baselines at the group level, instead of doing expensive nested sampling per question. The result is fewer tool-heavy rollouts during proposer training, which is where costs explode in multi-turn agent setups.
Can I use the Dr. Zero code commercially?
Not as-is. The facebookresearch/drzero repository states the code is released under a non-commercial license, so commercial use would require separate permission or an alternative implementation you’re licensed to ship.