

Table of Contents
1. The Dawn Of Anthropic Mythos
Most model launches feel like product updates. Anthropic Mythos feels more like someone quietly wheeled a jet engine into the office and asked whether the furniture was bolted down.
The strange thing about this release is not just that Claude Fable 5 is powerful. Frontier models are always powerful, at least in the press release sense of the word. The strange thing is the split. One model family, two public identities. Claude Fable 5 is the version most people can touch. Anthropic Mythos is the same underlying intelligence with certain restraints lifted, reserved for vetted partners through programs such as Project Glasswing.
That’s the story in miniature. Same brain, different blast radius.
The technical signal is hard to ignore. The model is not merely better at writing polite emails or explaining merge conflicts. It is built for long-horizon work, tool use, repository-scale software changes, document reasoning, biology, cybersecurity, and the kind of multi-step autonomy that makes “chatbot” feel like the wrong noun.
“`htmlAnthropic Mythos/Claude Fable 5 Benchmarks
| Category | Benchmark | Claude Mythos 5 / Fable 5 | Claude Mythos Preview | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Agentic Coding | SWE-Bench Pro | 80.3% | 77.8% | 69.2% | 58.6% | 54.2% |
| Agentic Coding | FrontierCode Diamond | 29.3% xhigh | Not Stated | 13.4% xhigh | 5.7% xhigh | Not Stated |
| Knowledge Work | GDPval-AA | 1932 | Not Stated | 1890 | 1769 | 1314 |
| Knowledge Work Vision | GDP.pdf | 29.8% no tools | Not Stated | 22.5% no tools | 24.9% no tools | 16.7% no tools |
| Spatial Reasoning | Blueprint-Bench 2 | 38.6% | Not Stated | 14.5% | 36.2% | 26.5% |
| Tool Use | AutomationBench | 17.4% | Not Stated | 15.5% | 12.9% | 9.6% |
| Computer Use | OSWorld-Verified | 85.0% | 85.4% | 83.4% | 78.7% | 76.2% |
| Legal | Legal Agent Benchmark | 13.3% | Not Stated | 10.4% | 2.1% | 0.0% |
| Multidisciplinary Reasoning | Humanity’s Last Exam, No Tools | 59.0% | 56.8% | 49.8% | 41.4% | 44.4% |
| Multidisciplinary Reasoning | Humanity’s Last Exam, With Tools | 64.5% | 64.7% | 57.9% | 52.2% | 51.4% |
| Biology | BioMysteryBench Hard | 46.1% | 29.6% | 40.0% | Not Stated | Not Stated |
| Biology | BioMysteryBench Human Solved | 83.9% | 82.6% | 80.4% | Not Stated | Not Stated |
| Agentic Coding | Terminal-Bench 2.1 | 88.0% | Not Stated | 82.7% | 83.4% Codex CLI | 70.7% Gemini CLI |
| Cybersecurity | ExploitBench Capability | 78.0% | 69.0% | 40.0% | 34.0% | Not Stated |
| Health | HealthBench Professional | 66.0% | 64.7% | 56.9% | 51.8% | Not Stated |
2. The Dual Release Strategy: Same Brain, Different Leash
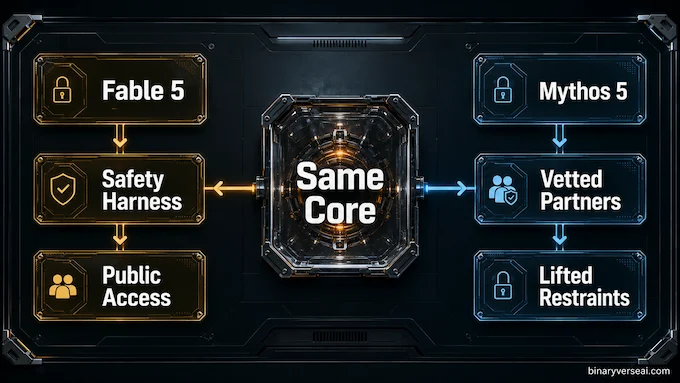
The cleanest way to understand Claude Fable 5 and Claude Mythos 5 is this: Fable is Mythos with a safety harness.
Claude Fable 5 is the public model. It has the same underlying weights, but it ships with aggressive classifiers around cybersecurity, biology, chemistry, distillation, and frontier AI development. When those classifiers fire, the model either refuses, routes the request to a safer fallback model, or quietly limits its effectiveness depending on the surface.
Anthropic Mythos is the restricted version. It exists for situations where the dangerous capability is also the useful capability. Cyber defenders do need strong cyber reasoning. Biosecurity researchers do need frontier biology assistance. Infrastructure providers do need models that can reason across messy, critical systems without getting squeamish at the first mention of an exploit.
This may annoy a developer debugging a toy scanner, but the system card makes the caution hard to dismiss. Models at this level don’t just answer questions. They compress work, connect domains, and turn vague intent into operational plans. Sometimes that’s productivity. Sometimes that’s a lawsuit with GPUs.
3. Why Anthropic Mythos Is Too Hot For Public Release
The Claude Mythos system card reads less like a glossy launch note and more like an internal safety review that escaped into daylight. That’s a compliment. It is dense, sometimes awkward, and much more revealing than the usual “we value safety” confetti.
The core concern is uplift. Not whether a model knows something bad. The internet already knows plenty of bad things. The question is whether the model can help a user do something hard, dangerous, and previously bottlenecked by scarce expertise.
Anthropic Mythos crosses uncomfortable lines in that framing. In cybersecurity, it scores far ahead of older Claude models on exploit development tasks. In biology and chemistry, the unrestricted model appears capable of accelerating expert teams, especially when paired with people who already know how to ask sharp questions. It still makes errors. It still overconfidently fills gaps. It still needs supervision. That’s not very comforting when the domain is “novel biological risk.”
Anthropic does not describe the model as magic. The failures resemble a bright junior engineer shipping a confident mess: arithmetic slips, weak long-session constraint tracking, over-engineered plans, occasional hallucinated citations, and a tendency to continue when a careful expert would stop and re-check assumptions.
In normal software, that means a weird bug. In high-risk science, that means access control.
4. What The Claude Mythos Benchmarks Actually Say
The Claude Mythos benchmarks are impressive, but the lesson is not “bigger number good.” We have had enough leaderboard theater for one civilization.
The important pattern is where Anthropic Mythos pulls ahead. SWE-Bench Pro at 80.3% suggests serious competence on repository-scale coding tasks. FrontierCode Diamond at 29.3% looks small until you notice it more than doubles Opus 4.8. That benchmark is not asking for cute functions. It is closer to “can this thing survive inside a real production codebase?”
OSWorld-Verified at 85.0% shows the model can operate software environments with fewer rails. GDP.pdf and Blueprint-Bench 2 show progress in visual document reasoning, the sort of boring enterprise skill that quietly saves entire departments from spreadsheet archaeology.
The biology and cyber rows are where the temperature changes. BioMysteryBench and ExploitBench are not just capability trophies. They explain the dual-release strategy. A public model that can reason well about vulnerabilities and biological systems is valuable to defenders and researchers. It is also valuable to people you would rather not empower.
The practical read is simple. Software teams can treat Claude Fable 5 as a junior agent, not a smarter autocomplete. Risk teams should treat Anthropic Mythos as an access-control problem.
5. Fable 5 In Public: The Model With A Seatbelt And A Nervous Tick
Claude Fable 5 is going to annoy people. Not because it’s bad. Because it is powerful enough to be useful, and guarded enough to interrupt you at exactly the moment you thought you were getting somewhere.
Public users have already focused on the personality shift: careful, apologetic, and eager to explain the safety perimeter before doing the work. I’d call it a frontier model wearing a compliance vest.
This is the tax of making Anthropic Mythos-class capability public. The model needs broad safety coverage because the dangerous and benign versions of a request often share vocabulary. A penetration tester and a criminal may both ask about exploit chains. A biology researcher and a bad actor may both discuss synthesis constraints. A developer building a sandbox game may use words that look suspiciously close to weapons, toxins, or malware.
That creates false positives. It also creates user rage, because nothing feels more absurd than being protected from your own pulled pork recipe or a harmless HTML game. The classifier does not understand your day. It sees a risk surface.
6. The Fallback Machine: Why Your Query Suddenly Feels Smaller
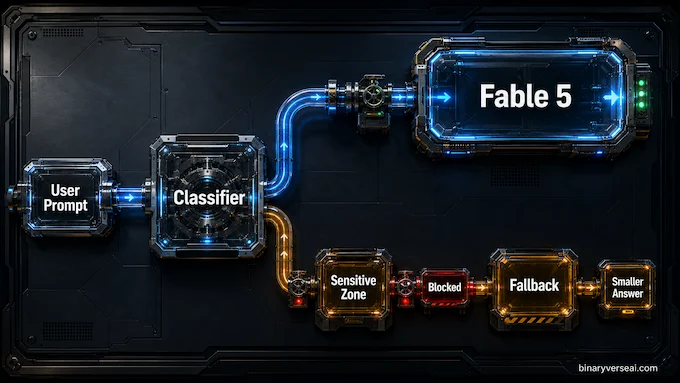
The fallback mechanism is the strangest part of Claude Fable 5 for everyday users. You ask Fable 5 something. A classifier decides the request falls into a sensitive zone. In the app, the system routes you to Claude Opus 4.8. In the API, the default behavior is stricter: the request can be blocked unless the developer has configured fallback logic.
From a safety engineering perspective, this is elegant. From a user perspective, it can feel like ordering espresso and receiving warm milk with a note from legal.
The catch is that fallback is not always obvious at the level of task quality. You may simply notice that the answer became less sharp, less agentic, or less willing to follow the technical trail. For coding, this matters. For security research, it really matters. The public model may be nominally Fable 5, but the effective model depends on what the classifier thinks you’re doing.
Anthropic Mythos avoids that particular problem because trusted users get the frontier capability with selected safeguards lifted. That is the whole bargain. More access, more trust, more responsibility.
The deeper lesson is that model names are becoming less meaningful than routing policies. “Which model did I use?” may depend on your prompt, interface, organization, and whether a hidden classifier got nervous.
7. Claude Fable 5 Pricing And The Subscription Cliff
Claude Fable 5 pricing is where excitement meets arithmetic, which is where excitement often goes to die.
At launch, the headline price for Fable 5 and Mythos 5 is $10 per million input tokens and $50 per million output tokens. That is cheaper than Mythos Preview, but still expensive enough to punish careless prompting. Long-horizon agents do not sip tokens. They graze.
“`htmlClaude Fable 5 Pricing and Anthropic Mythos Access
| Access Mode | Who Gets It | Price | Practical Catch |
|---|---|---|---|
| Claude Fable 5 In Apps | General users with eligible access during rollout | Included through subscription access where available | Usage limits can drain quickly on long, high-effort tasks |
| Claude Fable 5 API | Developers and teams | $10 per million input tokens, $50 per million output tokens | Sensitive requests may block or require configured fallback |
| Claude Mythos 5 Trusted Access | Project Glasswing and vetted partners | $10 per million input tokens, $50 per million output tokens | Not publicly available, access depends on approval |
| Opus 4.8 Fallback | Triggered by Fable 5 safeguards in supported surfaces | Depends on product surface and billing setup | You may receive lower capability when classifiers trigger |
| High-Effort Agentic Sessions | Power users, coding agents, enterprise workflows | Same token rates, higher total spend | Deep reasoning and tool loops can consume large limits fast |
This pricing matters because the best use cases are not tiny chats. Multi-file migrations, research loops, long-context audits, and agentic debugging burn both input and output tokens.
Fable 5 may be more token-efficient than earlier models on some hard tasks. That does not make it cheap. A Ferrari can be fuel-efficient compared with a rocket.
8. Agentic Coding: The Part That Should Make Engineers Sit Up
The strongest case for Anthropic Mythos-class models is software engineering. Not “write me a regex” software engineering. Real software engineering, the kind involving old code, strange conventions, failing tests, hidden dependencies, and that one module everyone is afraid to open.
The reported Stripe example is the kind of thing that makes engineering managers blink twice: a broad Ruby migration across a 50-million-line codebase compressed from months into roughly a day. Treat that as an early signal, not a universal promise. Most teams do not have Stripe’s tooling, tests, or internal evaluation culture. Still, the direction is obvious.
Fable 5 seems most useful when the task is large enough to reward planning. It can inspect, modify, test, revise, and keep context across a long run. That makes it very different from a model that merely writes a function and waits for applause.
The failure mode is also familiar. Users report loops where the model thinks, rethinks, explains, and produces less code than expected. That is the shadow side of long-horizon reasoning. Sometimes the agent is being careful. Sometimes it is just pacing in the hallway with a clipboard.
The best pattern is to give it bounded, verifiable chunks. Ask for a migration plan, then a patch, then tests, then a diff review. Don’t ask it to “modernize the backend” and wander off for lunch. That’s not delegation. That’s superstition with a progress bar.
9. Privacy, Retention, And Enterprise Nerves
The enterprise story is more complicated than the benchmark chart. Anthropic Mythos-class traffic raises a monitoring problem: if a model is risky enough to need strong jailbreak detection, the provider needs enough visibility to detect abuse. That can collide with enterprise expectations around privacy, retention, and zero-data-retention contracts.
A 30-day retention window for monitoring may be defensible from a safety standpoint. It also makes lawyers sit forward in their chairs. Regulated companies care about where prompts go, how long they stay there, who can inspect them, and whether sensitive code or research data becomes part of an abuse-monitoring pipeline.
This is not paranoia. It is normal enterprise hygiene.
The likely future is tiered access. Public Fable 5 for broad use. Restricted Anthropic Mythos for vetted high-need domains. Enterprise controls for teams that can prove both legitimate use and responsible handling. More paperwork, yes. Also more realism.
The age of “just paste the code into the chatbot” is ending. For serious teams, AI access now means policy, logging, secrets management, audit trails, and clear rules about which model can touch which workload.
10. Final Verdict: Use It Like A Chainsaw, Not A Butter Knife
Claude Fable 5 is not the model I’d use for every casual task. For lightweight writing, simple Q&A, quick summaries, and everyday coding help, a cheaper and calmer model may be the better tool. You don’t need a controlled detonation to make toast.
Use Fable 5 when the task has real depth: repository-wide refactors, complex debugging, long document analysis, agentic workflows, technical planning, multimodal reasoning, or work where the cost of a weak answer is higher than the cost of tokens.
Anthropic Mythos is a different category. It is not a consumer upgrade. It is an admission that frontier capability now has to be rationed by trust. That may sound dramatic, but it is probably the least dramatic way to handle a model that can help defend critical systems and potentially uplift dangerous actors.
The big shift is philosophical as much as technical. We used to ask, “How smart is the model?” Now we ask, “Who should get which slice of its intelligence, under what conditions, with what monitoring, and with what fallback?”
That is the Mythos-class era. Less like buying software, more like licensing industrial equipment.
The call to action is simple: don’t chase the model name. Match the model to the job. Put Fable 5 on work that needs endurance, tools, and deep context. Keep cheaper models for shallow tasks. If you’re in security, biology, or critical infrastructure, start building the governance muscle now. Anthropic Mythos is not the last restricted frontier model we’ll see. It is the first public warning shot.
What Is The Difference Between Claude Fable 5 And Anthropic Mythos 5?
Claude Fable 5 and Anthropic Mythos 5 use the same underlying model intelligence. Fable 5 is the public version, protected by strict safety classifiers for cyber, biology, chemistry, and distillation risks. Mythos 5 is the restricted version with selected safeguards lifted, available only to vetted partners through programs such as Project Glasswing.
Why Was Anthropic Mythos Deemed Too Dangerous For The Public?
Anthropic Mythos was restricted because its raw capabilities crossed sensitive risk thresholds in cybersecurity and biological or chemical domains. Its strongest concern is uplift: helping capable users do dangerous work faster. The system card and benchmark results show major gains in exploit development, frontier biology reasoning, and long-horizon autonomous tasks.
What Happens To Claude Fable 5 Pricing After June 22?
Claude Fable 5 is included for Pro, Max, Team, and seat-based Enterprise users only through June 22. Starting June 23, Anthropic plans to remove it from those standard subscriptions. Continued use will require usage credits, with API pricing set at $10 per million input tokens and $50 per million output tokens.
Why Does Claude Fable 5 Keep Switching Me Back To Opus 4.8?
Claude Fable 5 switches to Opus 4.8 when its safety classifiers flag a prompt as related to cybersecurity, biology, chemistry, or model distillation. The prompt may be harmless, but the filters are tuned conservatively. Instead of letting Fable 5 answer, Anthropic routes the response through Opus 4.8 as a safer fallback.
Is Anthropic Mythos 5 Actually Better Than GPT-5.5?
Based on the supplied benchmark table, Anthropic Mythos 5 and Claude Fable 5 outperform GPT-5.5 in several major areas, including agentic coding, complex knowledge work, legal tasks, healthcare, and multidisciplinary reasoning. The biggest gap appears in SWE-Bench Pro, where Mythos/Fable scores 80.3% compared with GPT-5.5 at 58.6%.