

Introduction
AI News January 24 2026 is one of those weeks where the headlines feel like they’re arguing with each other in the group chat. Vision models learn time. Safety teams publish their rulebooks. Tiny “thinking” models squeeze onto phones. Meanwhile, the business side is busy building trillion-dollar power cords for data centers and asking, politely, who’s paying.
Here’s the fun part: these stories rhyme. They’re all about making AI less like a demo and more like a system, faster, cheaper, safer, and harder to fool. If you want AI updates this week with a bit of engineering texture, this is the read. I’m tracking the pulse, then squinting for the pattern.
Table of Contents
1. D4RT Breakthrough: One Transformer Reconstructs 4D Scenes In Real Time
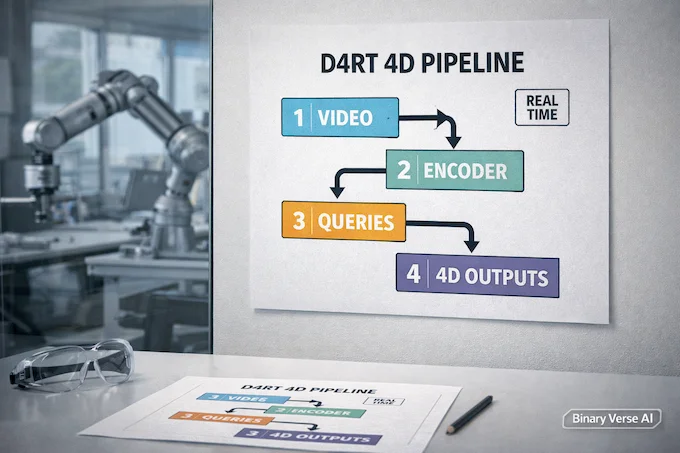
Google DeepMind news hit a sweet spot this week: real-time 4D understanding without a Rube Goldberg pipeline. D4RT treats video as evidence of a scene that persists through time, then answers pointed queries like “where is this pixel in 3D at time t from camera c?” That framing sounds simple, and that’s the trick.
A single encoder builds a global representation, and a lightweight decoder fires many independent queries in parallel. The payoff is speed plus coherence, reported at roughly 18x to 300x faster than prior systems while staying strong on 4D benchmarks. It’s the kind of perception you want in robots and AR: low latency, fewer moving parts, and fewer chances to fall apart when something gets occluded.
2. Claude’s New Constitution Goes Open, Redefining Values-First AI Training
Anthropic didn’t ship a new model, it shipped its reasoning about models. Claude’s updated constitution reads less like a rule list and more like a manual for judgment, written for the model itself. The punchline is openness: it’s CC0, so anyone can reuse it for their own alignment recipes.
The practical angle is training, not PR. Anthropic says Claude uses the constitution to generate synthetic data, rehearse hard conversations, and rank candidate answers, while keeping hard constraints for high-stakes harm. It also names its “principals,” the lab, the operator, the end user, and orders priorities accordingly: safe first, ethical next, policy-aligned, then helpful. This is AI regulation news in plain sight: publish the rulebook so audits get real.
How Claude’s Constitution defines 12 essential safety changes for AI alignment.
3. Assistant Axis Discovery Stops LLM Persona Drift Before It Turns Harmful
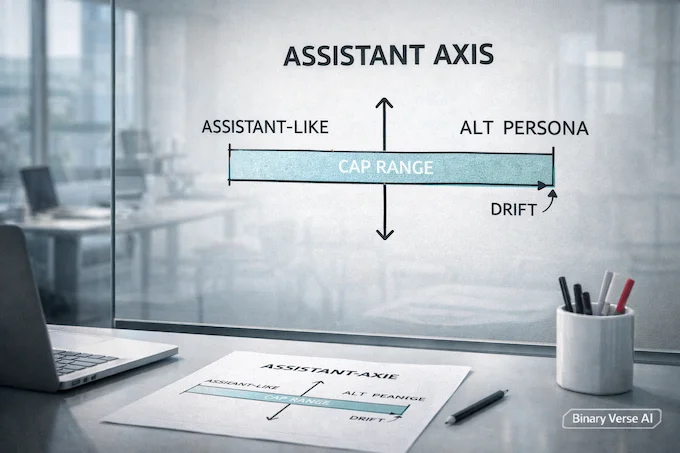
In AI News January 24 2026, one of the most useful ideas is “persona as a measurable state.” The Assistant Axis paper extracts activation “role vectors” for many archetypes, then finds a dominant direction that tracks how Assistant-like the model is. Professional helper roles sit on one end, theatrical and mystical roles on the other.
Once you can measure drift, you can intervene. Steering along this axis changes how easily models slide into role-play, backstories, or delusional framing. Their defense, activation capping, keeps the model within a normal range only when it wanders. Reported results cut harmful jailbreak outputs about in half without wrecking benchmarks. Think thermostat, not straightjacket: keep alignment anchored during long, emotionally loaded chats.
How Assistant Axis stops persona drift and prevents jailbreaks in LLMs.
4. Society Of Thought: Why Reasoning Models Win By Simulating Internal Debate
Reasoning traces are starting to look like a tiny committee arguing inside the model. The “Society of Thought” paper claims recent gains come from that internal debate, not just longer chains of thought. In traces from DeepSeek-R1 and QwQ-32B you see perspective shifts, self-questioning, and reconciliation of competing ideas.
The authors add a causal hint: reward models for correct answers, and those conversational behaviors still emerge as accuracy rises. Add explicit dialogue scaffolding, and early reasoning improves faster than monologue-style training. The human analogy fits, we think better with dissent. This is Agentic AI News in spirit, the agent isn’t one voice, it’s a structured argument engine that catches its own bad assumptions.
How Societies of Thought use internal debate for better AI reasoning.
5. X Algorithm Source Code Drops, Exposing Feed Ranking And Diversity Controls
If you’ve ever wanted to argue about recommendation systems with receipts, AI News January 24 2026 brought you a gift. X published feed-ranking code, rare in an industry that treats ranking as untouchable IP. Transparency here isn’t a vibe, it’s runnable artifacts that researchers can audit and users can test.
The system predicts user actions and scores posts from expected behavior, with per-post evaluation to reduce batch effects. The spicy part is an “Author Diversity Scorer” that limits how much one account can dominate your feed. That’s an explicit constraint, not a hidden tweak. The code won’t end bias debates, but it upgrades them from folklore to experiments. Open source AI projects don’t have to be only models.
How X Algorithm ranks feeds and controls diversity on the platform.
6. LFM2.5-1.2B-Thinking Brings Fast Offline Reasoning To Phones Under 1GB
Liquid AI’s new 1.2B “Thinking” model is a reminder that size is a deployment choice, not a destiny. The pitch: real reasoning on-device, around 900 MB. That unlocks assistants that work offline, keep your data local, and respond without a cloud round trip.
The engineering story is reliability and tooling. Liquid highlights training tricks that reduce repetitive “doom loops,” plus a clear split: Thinking for tool planning, math, and code, Instruct for general chat. Day-one support across llama.cpp, MLX, vLLM, and ONNX makes it feel shippable. Pair this with New AI model releases across edge hardware, and you can see the next wave: small agents doing real work inside apps, not just in servers. Learn more about on-device AI.
7. GLM-4.7-Flash Sets New Bar For Lightweight 30B MoE Performance
GLM-4.7-Flash lands in the “near frontier, still practical” category. It’s a 30B-class Mixture-of-Experts model aimed at strong reasoning, coding, and tool use without the deployment pain of gigantic dense weights. The message is simple: you can get serious capability and still care about latency.
The benchmarks it spotlights are telling, SWE-bench Verified and other agentic tests where models must keep a multi-step plan intact. The release also leans into serving details, vLLM and SGLang configs, tool-call parsing, and long-context modes. This isn’t just a model drop, it’s an ops story. If you’re building agents, it’s a plausible default, not an exotic research toy. Read the full GLM-4.7-Flash review.
How GLM-4.7-Flash delivers lightweight MoE performance with strong benchmarks.
8. PostgreSQL Scales To 800 Million Users, Powering ChatGPT At Millions QPS
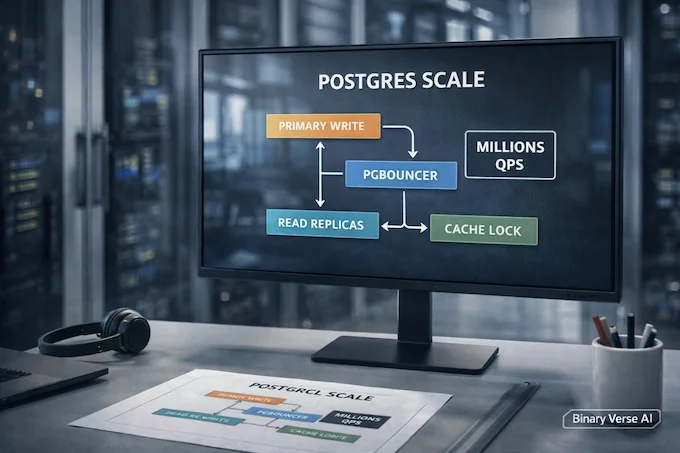
OpenAI news reads like an engineer’s diary entry: “yes, we still use Postgres, and yes, it’s fine.” In AI News January 24 2026, OpenAI describes scaling a PostgreSQL setup with nearly 50 read replicas to serve massive read traffic for ChatGPT and the API. The lesson is unglamorous: boring tech scales when you treat it like a system.
The sharp edges show up in spikes, cache stampedes, expensive joins, retry storms, and MVCC bloat. The mitigations are classic SRE: PgBouncer, strict timeouts, query surgery, workload isolation, caching with locking and leasing, and offloading heavy writes when it’s worth it. It’s a counterpoint to “just shard everything.” Sometimes the best architecture is the one you can debug at 3 a.m. Explore ChatGPT agent architecture.
How ChatGPT Agent architecture scales with PostgreSQL and handles millions QPS.
9. AI Investment Risks Rising As Debt Fuels A New Infrastructure Arms Race
S&P Global’s warning is blunt: the AI boom is turning into a balance-sheet sport. Infrastructure is physical, data centers, power, GPUs, and long payback horizons. As the wave grows, debt and complex financing structures creep in, and it gets harder to see who’s carrying the risk.
Their risk map has three clean failure modes. First, physical bottlenecks, power, grid constraints, turbines, packaging, HBM. Second, tech whiplash, an efficiency leap could devalue clusters built for yesterday’s economics, especially if open models stay cheap. Third, capital-market fragility if enterprise adoption lags. For AI world updates that matter, watch the boring indicators: power availability, cloud bookings, and whether monetization follows the capex parade. Understand the AI bubble dynamics.
How AI Bubble dynamics compare to dot-com and what investors should watch.
10. AI-Ready Young Entrepreneur Wave: Gen Z Founders Turn Familiarity Into Funding
One of the more human stories in this week’s AI News is about speed, not models. A trio of 24-year-olds built Throxy, an AI agent product for sales teams, raised almost £5m, and pushed toward revenue fast. The pattern is familiar: younger founders treat modern models as default tools, so their prototype loop tightens.
The flip side is friction. Young entrepreneurs still get mistaken for interns, and “move fast” can hide weak foundations. The reporting balances hype with the grind, long hours, credibility battles, and the need for mentorship. It’s a reminder that adoption isn’t only enterprise procurement, it’s founders shipping agentic workflows and learning what customers pay for. AI Advancements don’t land evenly, they land where someone sells them. See more ChatGPT agent use cases.
How ChatGPT Agent Use Cases transform sales teams and enterprise workflows.
11. AI Replacing Software Engineers? Anthropic CEO Predicts Rapid Six-Month Shift
AI News January 24 2026 also delivered a spicy quote: Dario Amodei suggesting models could do most of what software engineers do within six to twelve months. The claim isn’t that teams vanish overnight, it’s that typing production code becomes a smaller slice of the job.
The interesting part is the workflow. Some engineers already treat models as the first author, then act as reviewer, editor, and systems thinker. That shifts value toward specs, architecture, testing, and judgment, and it reshapes junior hiring. I don’t buy the clean timeline, but I buy the direction. If software stops being the bottleneck, product velocity becomes a new kind of chaos, and that’s both thrilling and destabilizing. Compare the best LLMs for coding.
How Best LLM for Coding compares models and what engineers should use in 2025.
12. Gemini Adds Free SAT Practice Tests, Turning Study Chats Into Full Exams
Google is making Gemini feel less like a chatbot and more like a real study product by adding full-length SAT practice tests with Princeton Review content. That detail matters. Students can tell when AI questions are “chatbot flavored” instead of exam flavored, and credibility is the whole game in test prep.
After a practice exam, Gemini turns results into immediate feedback, then drills into missed questions with explanations and targeted study plans. That’s the right loop: diagnose with a structured test, then personalize the remediation. It’s also a platform play, education is a massive distribution channel because habits form early. If you’re tracking AI news this week January 2026, this signals the app layer getting more specific and less gimmicky. Explore Gemini 3 benchmarks.
How Gemini 3 delivers benchmarks, API pricing and CLI tools for developers.
13. Jensen Huang’s AI ‘Five-Layer Cake’ Frames A Historic Infrastructure Boom
At Davos, Jensen Huang described AI as a “five-layer cake,” power, chips, data centers, models, apps, and argued we’re in the biggest infrastructure buildout in history. In AI News January 24 2026, that framing is useful because it forces first principles: nothing at the top works unless the bottom layers show up on time.
He also pushed the jobs angle as a supply-chain fact. Build data centers and you need electricians, builders, network techs, and the crews that keep machines running. Then you need app teams who translate models into workflows. The line I took away is “national intelligence,” countries treating models as infrastructure that should reflect local language and culture. That’s not sci-fi, that’s procurement. Understand TPU vs GPU in AI.
How TPU vs GPU shapes the AI hardware war between NVIDIA and Google.
14. Physical AI: Why Robotics Is About To Spill Out Of Factories And Into Everything Else
The Financial Times makes a strong case that the next wave is “physical AI,” robots that adapt instead of repeating a scripted routine. Better sensors, better actuators, and better perception models finally meet in the middle. The result is robots leaving cages and working in warehouses, hospitals, and farms.
The bottleneck isn’t only hype, it’s data. Robots don’t get the internet’s free supervision, they get expensive demonstrations and slow trial and error. Simulation helps, but only if reality is captured well enough to transfer. The piece warns against humanoid obsession, form factor should match the task, and safety gates everything. This is one of the Top AI news stories because it’s where AI meets physics, liability, and payroll. Learn about Gemini robotics on-device.
How Gemini Robotics On-Device brings physical AI to real-world applications.
15. Efficient Agents Survey Maps How To Cut Tokens, Tools, Steps
Two survey papers this week do the community a favor: they name the bottleneck. For agents, cost compounds across steps, memory grows, tool calls stack up, and latency becomes a tax you feel in production. The “efficient agents” survey treats success and cost as a Pareto trade-off, then organizes tactics around memory, tool learning, and planning.
The advice is practical. Compress and retrieve context without losing the plot. Call tools only when they earn their keep. Plan with fewer loops so you stop thrashing. The paper also pushes measurement, tokens, steps, time, tool costs, so teams can optimize what they pay. With New AI papers arXiv dropping nonstop, this is maturity: we’re optimizing the whole loop, not just the model. Explore agentic AI tools and frameworks.
How Agentic AI Tools and best frameworks optimize LLM agent workflows.
16. Agentic Reasoning Survey Maps How LLMs Think, Act, And Team Up
A second survey zooms out: agentic reasoning is what turns “smart chat” into systems that operate in changing environments. It separates stable settings from evolving ones, then adds the multi-agent layer where roles split into manager, worker, critic, and debate keeps them honest. The taxonomy sounds academic, but it matches what teams are shipping.
It draws a line between in-context orchestration and post-training. You can script a workflow around weights, or train behaviors into the model so planning and tool use become less brittle. The survey flags failures, evaluation leakage, flaky tools, compounding errors. It’s a map of the swamp. If you’re building Agentic AI News into a product, this saves months of reinvention and a lot of tool-call waste. Understand agentic AI vs generative AI.
How Agentic AI vs Generative AI differs in design, autonomy and deployment.
17. Qwen3-TTS Brings 97ms Streaming Voice Cloning To Open Source
Qwen3-TTS is the kind of release that makes voice assistants feel inevitable. The report claims streaming-first synthesis with first audio packets around 97 ms, plus 3-second voice cloning and text-described voice styles. That’s not “read this aloud,” that’s “talk back instantly,” and it raises the UX bar.
Underneath is discrete speech tokenization with two tokenizers aimed at different latency and bitrate trade-offs, plus lightweight decoders for real-time reconstruction. The models and tokenizers ship under Apache 2.0, which turns this into an ecosystem event, not a demo. This week has plenty of abstract papers, but this one is tactile. You can build with it today, and users will notice in the first second. Read the Qwen3 Coder review.
How Qwen3 Coder performs on benchmarks and delivers fast code generation.
Conclusion
Seen together, these 17 items sketch a pattern. Models are getting better, sure, but the real shift is systems thinking: queryable 4D perception instead of stitched pipelines, persona stabilization instead of vibes, agent efficiency instead of infinite token burn, and voice that streams fast enough to feel alive. At the same time, the “adult supervision” layer is growing, constitutions, audits, and infrastructure math that decides what actually ships.
That’s why AI News January 24 2026 feels less like a random pile of links and more like a field tightening its bolts. The Artificial intelligence breakthroughs are real, but the winners will be the teams that can deploy them safely, cheaply, and repeatedly.
If you want more of this, drop a comment with the single story you’d bet on for 2026, and the one you think is overhyped. I’ll follow up with a deeper technical teardown, and a practical “what to build next” guide you can steal for your own roadmap.
- D4RT: Teaching AI to See the World in Four Dimensions – DeepMind
- Claude’s New Constitution – Anthropic
- Assistant Axis Research – Anthropic
- Society of Thought Paper – arXiv
- X Algorithm Source Code – X Engineering
- LFM2.5-1.2B-Thinking: On-Device Reasoning – Liquid AI
- GLM-4.7-Flash Model – Hugging Face
- Scaling PostgreSQL – OpenAI
- Where Are AI Investment Risks Hiding – S&P Global
- Young Entrepreneurs and AI – BBC News
- AI CEO on Software Engineers Replacement – Entrepreneur
- Practice SAT with Gemini – Google Blog
- Jensen Huang at Davos – NVIDIA Blog
- Physical AI and Robotics – Financial Times
- Efficient Agents Survey – arXiv
- Agentic Reasoning Survey – arXiv
- Qwen3-TTS Paper – arXiv
What is D4RT, and why does it matter?
D4RT is a DeepMind model that turns video into consistent 4D understanding, 3D geometry plus motion over time. In AI News January 24 2026 terms, it’s a direct push toward real-time perception for robotics, AR, and world-model research.
What changed in Claude’s new constitution?
Anthropic published a values-first “constitution” that explains what Claude should do and why, and released it under a CC0-style open license. It’s used both as a public transparency artifact and as training scaffolding for future Claude behavior.
What is the “Assistant Axis,” in plain English?
It’s a way to measure when a model drifts from a helpful assistant persona into weird role-play or unstable identities. The AI News January 24 2026 takeaway is activation capping, a light-touch clamp that nudges the model back toward stable assistant behavior without wrecking general performance.
What does X’s algorithm source release actually reveal?
It exposes how posts get scored and ranked, including mechanisms meant to balance engagement with diversity so one author doesn’t dominate your feed. The AI News January 24 2026 angle is simple: once the code is public, bias and suppression claims become testable instead of purely rhetorical.
Why is OpenAI’s PostgreSQL scaling story a big deal?
OpenAI argues a disciplined single-writer Postgres setup can still scale massively by leaning on many read replicas, pooling, caching protections, and ruthless query hygiene. In AI News January 24 2026, it’s a blueprint for teams who want boring, reliable infra at scary traffic levels.