

Introduction
Sudden benchmark glow-ups always give me the same feeling as a too-clean Git history. Interesting, maybe impressive, but I want to see what got squashed. GLM-4.7 landed with that exact energy, a flagship model claiming big jumps in coding, tool use, and long-horizon reasoning, paired with a price that feels almost disrespectful to the rest of the market.
Some people collect leaderboards. Most developers collect unfinished tasks. If GLM-4.7 matters, it will show up in your workflow, fewer dead-end agent loops, fewer “wait, why are we doing this” turns, and less time spent rewriting generated UI by hand.
Here’s the fastest way to orient yourself.
GLM-4.7 Snapshot Table
| What You Care About | What You Get |
|---|---|
| Entry price | Z.ai coding plan starts at $3 per month, aimed at agent tools like Cline and Roo Code |
| Context and output | 200K context window, up to 128K output tokens |
| Core pitch | Stronger agentic coding, better front-end “vibe coding”, improved tool calling |
| Headline benchmark | 42.8% on Humanity’s Last Exam with tools enabled |
| Local option | Open weights, so you can run it yourself if you have the hardware |
Table of Contents
1. The GLM-4.7 Hype: “Benchmaxxing” Or Real Breakthrough?
The $3 headline matters because it changes who gets to test serious models. When a system shows up inside popular agent shells and costs less than a streaming subscription, it stops being a weekend experiment. It becomes a daily-driver candidate.
That also explains the skepticism. r/singularity users have seen enough “big jump” releases to ask the obvious question, did capability really move, or did the eval harness get friendlier?
My read is blunt. The interesting story is not one heroic number. It is a set of engineering choices aimed at making agentic workflows less fragile. The marketing talks about intelligence. The docs talk about stability and control.
1.1 My Expert Take
If you are hunting the best LLM for coding 2025, watch failure modes, not highlights. Great models keep their bearings across hours of back-and-forth, adapt when tools return messy output, and stay consistent when you change requirements mid-task. GLM-4.7 is clearly optimized for that style of work.
2. Spec Sheet: What Makes GLM-4.7 Different??
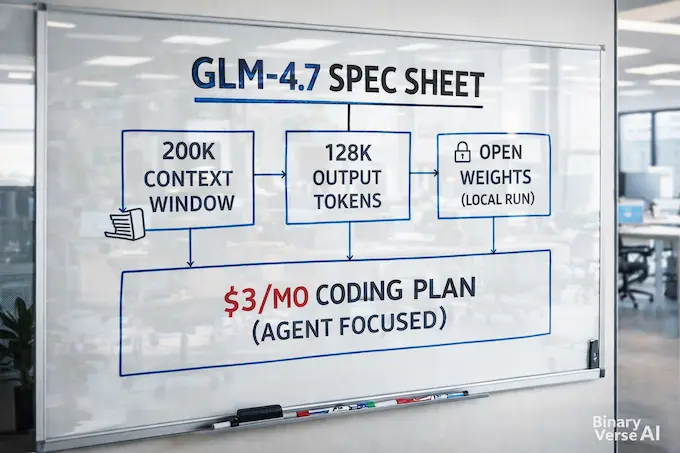
Specs are boring until they stop your workflow from breaking. A 200K context window is not a flex, it is permission to keep your design notes, logs, code, and constraints in one place without playing token Tetris. With GLM-4.7, that context ceiling is high enough to feel practical, not theoretical.
The headline specs are straightforward:
- 200K context length.
- Maximum output up to 128K tokens.
- Open weights release, with a permissive license in the model card.
That last bullet is the quiet one. It means you can take the model out of the hosted environment and into infrastructure you control. For privacy, for compliance, or for the simple joy of not being rate-limited mid-sprint, that matters.
2.1 The Capability Menu That Actually Matters
The feature list hits the modern essentials: thinking modes, streaming, function calling, context caching, and structured outputs like JSON. The differentiator is how much of that is tuned for agent loops. Z.ai GLM is selling “model plus agent ergonomics,” not a raw autocomplete engine.
3. The “Preserved Thinking” Feature Explained

This is the feature that made me stop scrolling. Preserved Thinking means the model retains its internal reasoning blocks across turns in coding agent scenarios, instead of re-deriving its plan from scratch each time.
In human terms, it reduces the goldfish problem. Many agents do something impressive, run a tool, then come back and narrate a slightly different universe. That inconsistency compounds. You end up debugging the agent instead of your code.
GLM-4.7 pairs Preserved Thinking with Interleaved Thinking, meaning it thinks before responses and tool calls. It also supports turn-level control so you can disable deep reasoning when you just want formatting, not philosophy.
3.1 Why This Changes Agent Stability
In agent work, the enemy is drift. Plans slowly mutate because the system forgot a constraint or lost a conclusion. Preserved Thinking is a direct countermeasure. It is a stability feature dressed up as a reasoning feature, and it matches the way real coding sessions unfold.
4. GLM-4.7 Vs Claude 4.5 Sonnet And GPT-5.2: The Coding Face-Off
If you are comparing top models for coding, you care about three outcomes:
- It fixes real bugs and writes real code.
- It survives long agent loops without babysitting.
- It generates UI you would not be embarrassed to ship.
GLM-4.7 is positioned directly against Claude Sonnet 4.5 in the agent-coder lane. The published benchmark table includes SWE-bench Verified, multilingual SWE-bench, Terminal Bench, and tool benchmarks like τ²-Bench and BrowseComp. The margins are close enough that behavior will matter more than rank.
4.1 Vibe Coding, The Unsexy Metric
“Vibe coding” sounds like a meme until you have to ship front-end. UI generation has a brutal threshold. Either the output is clean enough to keep, or you toss it and do it yourself.
The release notes claim a real jump in front-end aesthetics, cleaner pages, better slide layouts, and more accurate sizing. If that holds in your stack, it translates into fewer edits, fewer layout bugs, and faster iteration.
4.2 My Expert Take
Claude often feels like a careful senior engineer. GPT-5.2 tends to feel like a fast generalist. GLM-4.7 is trying to feel like a persistent agent teammate that keeps state. If that “statefulness” sticks, it is a competitive advantage you will notice on day two, not day one.
5. Analyzing The Benchmarks: The Truth About “Humanity’s Last Exam”
Humanity’s Last Exam is the benchmark keyword everyone is repeating because it is hard and because it sounds like a movie trailer. The number attached to this launch is 42.8%.
That score is for the tool-enabled setting. The same table shows a much lower score without tools. The delta is the story. Tool use gives a big lift compared to the previous generation’s tool setting.
That changes how you should interpret it. Tool-assisted evaluation is not a memory quiz. It is a workflow test. The model has to decide when to call tools, how to form calls, and how to integrate results without losing the thread.
5.1 Tool Use Is Not Cheating, It Is The Job
Real work looks like this: read context, form a hypothesis, run a command, adjust. Benchmarks that force tool use are closer to that loop. If GLM-4.7 is genuinely better at multi-step tool use, the payoff will show up in agent frameworks, not in a single one-shot answer.
6. Pricing Reality: The $3 Coding Plan Vs GLM API Costs
The $3 plan is not “the API is cheap now.” It is a subscription wrapper designed for AI-powered coding workflows, especially agents running through a dedicated coding endpoint. It is meant to be frictionless inside tools like Cline and Roo Code.
If you are integrating directly, you care about the GLM API pricing. The published numbers for the flagship text model are $0.60 per 1M input tokens and $2.20 per 1M output tokens, with discounted cached input and limited-time free cached storage. Built-in web search is billed per use.
6.1 The Second Order Cost People Miss
Agent costs spike on output. A model that rambles is an expensive model. If you are doing GLM-4.7 vs Claude 4.5 Sonnet LLM API pricing math, track output length and tool chatter, not just input rates. Turn-level thinking control matters because you can be strict about when it “thinks hard” and when it just returns an answer.
GLM-4.7 Scenario Fit Table
| Scenario | Best Fit | Why |
|---|---|---|
| You want cheap daily coding help inside an agent | Z.ai coding plan | Low entry price, designed for agent shells |
| You are building product features | GLM API | Predictable billing, full control over prompts and tools |
| You need maximum privacy or fewer content filters | run GLM-4.7 locally | You control data flow, moderation, and logging |
7. Roleplay And Creative Writing: The Reddit Verdict
Coding is the headline, but creative communities care about different failure modes. Users want character consistency, lore tracking, and prose that does not collapse into repetitive “AI voice” filler.
The reported vibe is positive. People describe less “slop,” fewer stock phrases, better character continuity, and stronger handling of established universes. RWBY lore pops up as a common stress test because small continuity errors expose weak models quickly.
If you are using SillyTavern or a similar front-end, start with temperature 1.0 and top_p 0.95. Those defaults keep the writing lively without turning it into chaos.
8. Local Deployment Guide: Hardware And VRAM Requirements

Best open source LLM is a fun phrase until you price the hardware. “Open weights” still means you need enough VRAM to breathe.
For Macs, the practical path is MLX-style tooling on Apple Silicon, and people have reported success on high-end configs like an M3 Ultra when serving GLM-4.7. For PCs, smooth performance often means multi-GPU setups, think dual 3090s or 4090s for 4-bit quants.
On the serving side, GLM-4.7 supports vLLM and SGLang, both popular for OpenAI-style APIs and tool calling. The official notes point to main-branch support and Docker-based installs.
8.1 A Practical Local Checklist
- Start with a quantized GGUF build if you are in llama.cpp ecosystems.
- If you want throughput plus tool calling, vLLM is the direct path.
- If you want preserved thinking template controls exposed, SGLang has explicit knobs.
Local is not the cheapest route. It is the most controllable route.
9. How To Migrate From GLM-4.6 To 4.7
Migrate is refreshingly boring. Update the model identifier, keep your prompts crisp, and decide how you want thinking and streaming handled.
Two details matter:
- Default sampling: temperature 1.0 and top_p 0.95, tune one at a time.
- Streaming tool calls: enable tool_stream=true to receive arguments as they form.
Minimal OpenAI-style SDK example:
from openai import OpenAI
client = OpenAI(
base_url="https://api.z.ai/api/paas/v4",
api_key="YOUR_ZAI_API_KEY",
)
resp = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "Briefly describe the advantages of GLM-4.7 for coding agents."}],
thinking={"type": "enabled"},
temperature=1.0,
)
print(resp.choices[0].message.content)Endpoints, depending on product surface:
Streaming tool-call pattern, trimmed to the essence:
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "Get weather for Beijing, then summarize."}],
tools=[...],
stream=True,
tool_stream=True,
)
final_args = {}
for chunk in response:
delta = chunk.choices[0].delta
if delta.tool_calls:
for tool_call in delta.tool_calls:
idx = tool_call.index
final_args[idx] = final_args.get(idx, "") + tool_call.function.argumentstool_call.index to rebuild the full JSON.
10. Safety And Privacy: The Open Source Advantage
Hosted platforms enforce policies. Local models enforce your policies. That split is the real “open” advantage.
If your work touches private repos, sensitive documents, or regulated data, running locally is less about edgy content and more about control. You decide what gets logged. You decide what leaves your machine. You decide how strict your environment should be.
Hosted still wins on convenience and updates. For many teams, the GLM API route is the cleanest compromise.
11. Pros And Cons Summary
Pros
- Cheap entry via the Z.ai coding plan, easy to plug into agent tools.
- Strong tool use focus, with competitive tool-assisted results.
- Preserved Thinking for multi-turn agent stability.
- Open weights option for local control and privacy.
Cons
- Local runs demand serious VRAM, often multi-GPU territory for good latency.
- Hosted filtering can clash with some creative scenarios.
- Long outputs can get expensive fast if you do not control verbosity.
12. Final Verdict: Who Is GLM-4.7 For?
For developers, the $3 plan is the obvious starting point. Drop it into your agent shell and give it real work, a failing test, a messy log, and a UI request. Demos are easy. Long sessions are where models earn trust.
For product builders, the GLM API path offers predictable costs and clean integration, especially if you rely on function calling, streaming, and structured output.
For hobbyists and privacy maximalists, run GLM-4.7 locally. You get freedom and control, plus the delightful experience of debugging drivers when you would rather be writing code.
My closing take is simple. GLM-4.7 is not interesting because it claims to be smart. It is interesting because it is engineered to stay on task inside an agent. If you have been waiting for a model that feels less like a chatty assistant and more like a persistent coworker, test it on a real repo this week.
Make it earn its keep. If it saves you time and keeps you confident enough to ship, that is the only benchmark that matters.
Is the Z.ai Coding Plan really just $3?
Yes. The Z.ai GLM Coding Plan starts at $3/month and is a subscription designed for coding tools like Claude Code, Cline, OpenCode, and Roo Code. It uses a quota system (resetting every 5 hours) and does not convert into pay-as-you-go token billing. If you want direct API usage beyond those supported tools, you use the standard GLM API with per-token pricing (e.g., GLM-4.7 is billed per 1M tokens).
Is GLM-4.7 better than Claude 4.5 Sonnet?
It depends on what you mean by “better.” GLM-4.7 looks strongest when you run agentic, tool-using workflows and long multi-step tasks. Claude 4.5 Sonnet can still feel cleaner for some zero-shot coding prompts and “vibe” polish, especially for minimal-instruction tasks.
Can I run GLM-4.7 locally on my GPU?
Yes, but plan for real hardware. GLM-4.7 is big, so most people rely on 4-bit quantized builds. Practical setups include high-VRAM GPUs (often multi-GPU) or Apple Silicon configurations that can sustain large memory footprints.
What is “Humanity’s Last Exam” (HLE) in AI?
HLE is a reasoning-heavy benchmark designed to stress test real problem solving. The headline number people cite is GLM-4.7’s tool-assisted score, which signals the model can combine reasoning with external tool calls instead of only “answering from memory.”
Does Z.ai train on my code and private data?
For API usage, Z.ai’s API Data Processing Addendum says the company does not store the content you or your users provide or generate via API calls, it’s processed in real time. If you need maximum privacy and control, running open-weights locally keeps everything on your own machine.