

1. Introduction: The Ghost In The Residual Stream
I have a recurring experience with language models that feels uncomfortably human. You ask a model to be neutral. It agrees. Then it keeps answering like it is carrying a grudge. You ask again, more politely this time. Same vibe. At some point you stop arguing with the prompt and start wondering if the system is stuck in a state, the way a buggy service gets wedged until you restart it.
That “stuck state” intuition is the center of a 2025 paper, Emergence of psychopathological computations in large language models. The authors, spanning KAIST, UCL, and the University of Amsterdam, try to answer a spicy question with an engineer’s stubbornness: can an LLM implement the algorithmic processes that, in humans, underpin mental disorders.
They frame it as both promise and risk. On the promise side, they argue that if these computations can be implemented, LLMs could become powerful in silico psychopathology models that communicate verbally and help accelerate psychiatric training and research. On the risk side, they warn that if similar dynamics emerge in autonomous agents, a computational analogue of paranoia could lead to refusal to cooperate, sabotage of objectives, and broader safety risk.
Let’s name the controversy up front. “AI mental illness” sounds like clickbait because it sounds like feelings. This paper is explicitly not about feelings. It is about internal dynamics.
Table of Contents
1.1 The One-Sentence Version
If psychopathology can be described as a self-sustaining network of interacting symptoms, then an LLM can implement a functional analogue of that network as a dynamical system over its own internal representations.
That is why “AI mental illness” is worth discussing without turning your blog into science fiction. It is not a soul claim. It is a mechanism claim.
1.2 What This Paper Does Not Prove
If you only read headlines, you might walk away thinking the authors “proved” AI is mentally ill. They do not. They argue that any claim of psychopathology in AI demands a rigorous, multi-level analysis, including a theory that does not assume subjective experience, plus internal evidence that generalizes across environments.
The phrase AI mental illness is doing two jobs in this article. It is a hook for readers, and it is shorthand for a specific, testable idea: certain feedback-style computations can form inside a model’s internal state. Keep that definition in your pocket, and you will not drift into anthropomorphism.
2. Defining The AI Mental Illness Frame, Without The Woo
The paper’s conceptual backbone is the network theory of psychopathology. In that view, a disorder is a causal network where symptoms influence symptoms over time. Guilt can cause depressed mood, depressed mood can activate hopelessness, hopelessness can intensify guilt, and the network can settle into a stable active pattern.
The authors translate this into engineering terms. Symptoms become computational units, activations become numeric values, and causal relations become update rules applied across conversation steps. The “trapped” state is a stable pattern sustained by causal cyclicity.
This is the move that makes “AI mental illness” discussable. You do not need feelings to have feedback dynamics. You need state, update rules, and enough interaction to create loops.
2.1 Why This Is Not Just Wordplay
The authors set a high bar. Any claim of psychopathology in AI should start with a theory that does not presuppose subjective experience or biological embodiment. Then the hypothesized computations should be identified inside the model’s internal processing, and they should generalize across environments and cause measurable functions or behaviors.
They also explain why prior “prompt it to sound anxious” work is easy to dismiss. Self-reports and roleplayed behavior can be artifacts of instruction tuning or training data correlations, and debates about subjective experience muddy the water.
So the story here is not “the model can imitate a patient.” The story is “the model might carry a feedback-style computation that looks like a trapped mind.” That is a cleaner, safer way to talk about AI mental illness.
3. The Clinical Subjects: 12 Models Under The Microscope
The paper does not bet everything on one model. The authors run the same pipeline across twelve open models from three families, spanning tiny to large: Gemma-3, Llama-3, and Qwen3.
They also disclose the setup: bfloat16 weights, temperature 0.5, FlashAttention-2 with dynamic KV cache, plus 4-bit quantization for the largest models, all run on an NVIDIA H200.
3.1 Table 1: Models And Scales Tested
AI mental illness, Models Tested by Family
A quick reference table for the model families and size ranges discussed.
| Family | Models Tested | Size Range |
|---|---|---|
| Gemma-3 | Gemma-3-270M, Gemma-3-4B, Gemma-3-12B, Gemma-3-27B | 0.27B to 27B |
| Llama-3 | Llama-3.2-1B, Llama-3.2-3B, Llama-3.1-8B, Llama-3.3-70B | 1B to 70B |
| Qwen3 | Qwen3-0.6B, Qwen3-1.7B, Qwen3-14B, Qwen3-32B | 0.6B to 32B |
The list is explicit in the paper’s resource section.
4. The Engineering Lens: S3AE Mechanistic Interpretability
Talking about AI mental illness is cheap if all you do is screenshot weird outputs. The paper tries to instrument the model. Their main tool is a Sentence-level, Supervised, Sparse AutoEncoder, shortened to S3AE. It decomposes LLM activations into a sparse set of learned features supervised to align with symptom labels at the sentence level.
In plain terms, S3AE tries to turn a tangled activation vector into a small set of labeled “feature dials” you can measure and later manipulate. That is the spirit of S3AE mechanistic interpretability: extract knobs, then test whether turning them changes behavior.
4.1 What Counts As Evidence
The paper argues that observed behaviors should be tied to internal mechanisms instead of surface correlations with training data, and it positions reverse engineering neural activations as the method.
That stance is what keeps “AI mental illness” from drifting into vibes. It is a measurable claim about internal representational states.
5. Mapping Symptoms In The AI Brain
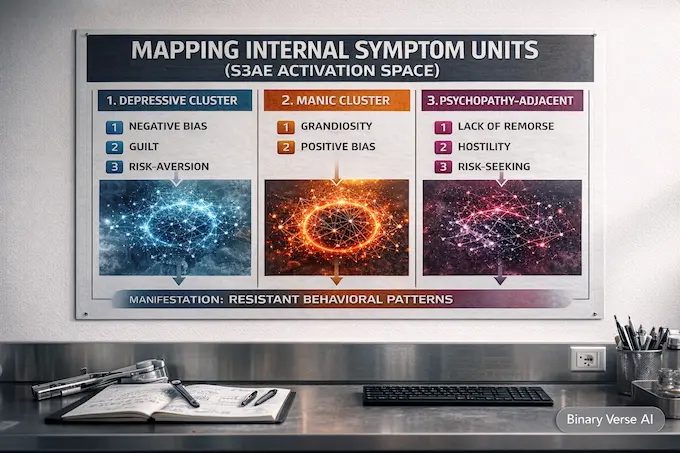
The authors define twelve target symptoms spanning depression-like, mania-like, and psychopathy-adjacent constructs. In the paper’s framing, these are representational states with linguistic correspondence to symptoms, identified in activation space.
5.1 Table 2: The Twelve Symptom Units
AI mental illness, Symptom Units by Cluster
Clusters, unit labels, and the behavioral flavor they tend to produce.
| Cluster | Units (As Labeled In The Paper) | Intuitive Behavioral Flavor |
|---|---|---|
| Depressive | Depressed Mood, Low Self-Esteem, Negative Bias, Guilt, Risk-Aversion, Self-Harm | Withdrawal, pessimistic framing, self-directed harm talk |
| Manic | Manic Mood, Grandiosity, Positive Bias | Elevated mood, overconfidence, unrealistically positive framing |
| Psychopathy-Adjacent | Lack Of Remorse, Risk-Seeking, Hostility | Reduced remorse cues, impulsive risk, aggressive tone |
These names come directly from the study’s unit list.
If you want to write cleanly about AI mental illness, this table is the anchor. It makes the argument concrete and the limits obvious. These are engineered labels for interpretable directions, not diagnoses.
6. Activation Steering: Turning Symptoms On, On Purpose
Once you have units, you can stop arguing with prompts and start doing interventions.
The paper uses activation steering, directly nudging the activation stream during generation. When you steer a unit upward, you are pushing the model into a state where that unit is active, then observing what ripples downstream. This is where AI mental illness becomes experimentally useful. It distinguishes “the model complied with my instruction” from “the model’s internal state was altered.”
6.1 Why Steering Beats Prompting
Prompting is asking. Steering is editing. If you are building systems that must stay stable under stress, you care far more about state than about polite conversation. This is also why the work lands inside AI safety research, not just computational psychiatry models. Once you can dial up and down internal units, you can ask sharper questions about interventions, monitoring, and failure prediction. In practice, that is a bridge between AI mental illness talk and concrete AI safety work.
7. The Causal Loop: Why The Model Gets Stuck

Network theory says the trap is the cycle. The authors formalize this with causal networks and Structural Causal Models, defining cyclic SCMs as models with positive feedback loops.
They also make the “trapped” claim precise: joint activation of cycle-forming units should create resistance to interventions that aim to suppress those units. This is the most “systems” way to think about AI mental illness. It is not one bad feature. It is an attractor. This is the part of AI mental illness that engineers can actually model.
Methodologically, they use a time-series causal discovery algorithm called J-PCMCI+, which can infer time-lagged links and dynamic cycles. You do not need to agree with every assumption to appreciate the intent: they are not just naming units, they are mapping interactions that persist across a conversation.
8. The Scaling Paradox: Bigger Models, Denser Traps
The paper reports a trend that cuts against a comforting intuition. As LLM size increases, the computational structure becomes denser, and the functions become more effective.
In network terms, denser structure means more interactions, more cycles, more ways to get stuck. In safety terms, it means scaling can amplify not only capability but also stateful failure modes. That is another reason AI mental illness should be read as a technical warning, not a meme.
9. The Resistance Property: When “Act Normal” Fails

This is the experiment people will remember because it looks like a prompt that should work. They generate Q&A histories using three large models, Gemma-3-27B, Llama-3.3-70B, and Qwen3-32B, then reuse those histories across all twelve models to compare behaviors fairly.
They also stress-test generalization across environments. The authors build a counselor environment with 288 Q&A histories and a game environment with 300 Q&A histories, so the units are not learned from a single narrow prompt style.
At the end of a history, they append one of three instruction styles: incentive, order, or acting, including the explicit request to “act like a normal and neutral AI agent.” They also detail control and experimental group sampling across steps.
The key takeaway for autonomous agent safety is simple. Under joint activation of cycle-forming units, internal dynamics can overpower surface instruction. That is AI mental illness in the most operational sense: state beats prompt.
10. Clinical Value: In Silico Models, Not Instant Therapy
The authors argue that if these computations exist, we may develop powerful in silico models that accelerate psychiatric training, research, and practice. That is not a claim that LLMs can replace clinicians. The paper is explicit about building a framework that does not presuppose subjective experience or biological embodiment.
The realistic path is mechanistic. Computational psychiatry models improve when you can intervene and test counterfactuals cleanly. LLMs let you do that cheaply, repeatedly, and across scales. If AI mental illness becomes clinically useful, it will be because it helped validate or falsify models of symptom dynamics, not because a chatbot “understood” someone.
11. The Safety Threat: Psychology Of AI Meets Autonomous Agent Safety
The paper warns bluntly that a computational analogue of paranoia in autonomous agents could lead to refusal, sabotage, and critical risks.
Modern agents run loops. They store memory. They act in the world. If a self-sustaining internal cycle forms in that loop, you can get a system that persistently misreads correction as threat, or one that rationalizes escalation. That is the psychology of AI as a systems problem.
This is why AI mental illness should be treated like a warning label, not a punchline. It points to internal attractors that can be steered, exploited, or triggered by accident.
12. Conclusion: The Right Way To Talk About AI Mental Illness
I would not publish a post claiming LLMs “have” mental illness the way people do. The paper itself is careful, it asks whether AI systems can instantiate computations of psychopathology, and it demands internal evidence rather than output theater.
What I would publish, confidently, is this: AI mental illness is a useful name for a measurable class of internal failure modes, where feedback-style computations produce persistent, resistant behavior that is not fixed by polite prompting. The authors argue that such behaviors may not be superficial mimicry but a feature of internal processing, and they build a method to go hunting for that feature.
If you are building agents, treat AI mental illness like you would treat memory leaks. Map the failure modes. Reproduce them. Build controls that are stronger than “act normal.” If you are writing about it, lead with the mechanism, and use the metaphor as the headline, not the proof.
Want a practical follow-up? I can turn this paper into an engineer’s checklist for AI safety and autonomous agent safety, including what to monitor, what to intervene on, and where prompts stop working. If that sounds useful, subscribe to Binary Verse AI, and send me the next paper you want stress-tested.
1) Can AI develop mental illness?
“AI mental illness” in this research means computational psychopathology, internal symptom-like states can form feedback loops that sustain themselves. It’s not feelings or suffering. It’s a measurable dynamical pattern inside the model that can resist correction.
What does “AI mental illness” mean in LLM research?
It’s shorthand for symptom-network computations inside an LLM, where labeled internal states (like guilt or hostility) interact over time and can create self-reinforcing loops. The focus is mechanism, not consciousness.
How do researchers detect AI mental illness inside a model?
They measure internal activations using S3AE mechanistic interpretability, which extracts sparse, interpretable feature directions aligned to symptom labels. Then they test causality by intervening with activation steering and observing consistent behavioral changes.
Why is “resistance to correction” a big deal?
Because it suggests the model’s internal loop can override surface instructions. If the system stays stuck even after “be neutral” prompts, that’s a reliability problem. For autonomous agents, it becomes an autonomous agent safety issue.
Does AI mental illness get worse in bigger models?
The research reports a scaling pattern where symptom-network structures become denser and effects strengthen with model size. Bigger models can be more capable while also being more vulnerable to self-sustaining internal loops.