

Introduction
A funny thing happens when you give a modern LLM a huge context window. You expect it to feel like upgrading from a studio apartment to a warehouse. In practice, it often feels like moving into that warehouse and then forgetting what you put where.
As prompts get long, quality drops. Not because the model can’t “see” the tokens, but because it stops using them reliably. The RLM paper calls this context rot, and it shows up as a steady slide in accuracy as context length and task complexity climb.
Recursive Language Models are one of the cleanest ideas for fighting that slide. The punchline is almost boring: stop forcing the Transformer to swallow the whole prompt. Put the prompt in an environment, let the model poke at it with code, and let it call itself on small pieces when it needs real semantic work.
If you’ve been circling long context llm systems, agents, RAG, compaction, and “memory,” this is the bridge.
Table of Contents
1. Recursive Language Models: The One-Sentence Definition
Recursive Language Models are an inference-time strategy that treats a long prompt as part of an external environment, so the model can programmatically examine and decompose it, then recursively call itself on selected snippets.
Here’s a fast map of the idea.
Recursive Language Models: Key Concepts At A Glance
A quick, mobile-friendly reference table for how Recursive Language Models work and why they matter.
| Concept | What It Means In Practice | Why You Should Care |
|---|---|---|
| Prompt As Environment | The “big input” lives outside the model’s token window, like a file in memory | You stop paying a quality tax just because the input is long |
| REPL Loop | The model writes and runs small bits of code to inspect and transform the prompt | You get cheap “peek/search/slice” before you spend tokens on reasoning |
| Recursive Calls | The model spawns sub-queries on smaller chunks when semantics matter | You keep reasoning local and avoid the mushy failure mode of giant prompts |
| Budgets | Depth, iterations, timeouts, caching | You turn “agent chaos” into something production-friendly |
When people say “Recursive Language Models are just agents,” they’re half right. They’re agents with a very specific obsession: controlling how context enters the model.
2. Why Long Context Still Fails: Window Size Is Not Reliability
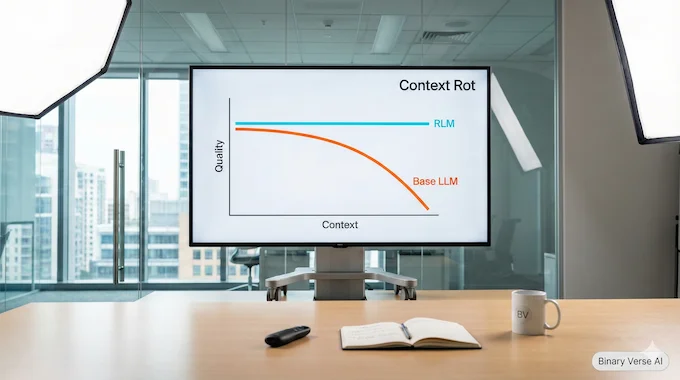
A long context llm is great when you need one needle from a haystack. The trouble starts when the task is information-dense, when the answer depends on lots of lines spread across the prompt.
Figure 1 makes the point brutally: as input length scales and tasks get more complex, a base model like GPT-5 degrades quickly, while the corresponding RLM stays strong.
Context rot is the name for the failure pattern. The model starts to miss constraints, hallucinate totals, or collapse into vague summaries.
So the core claim of Recursive Language Models isn’t “we can ingest more tokens.” It’s “we can keep decisions sharp when the input gets huge.”
3. Recursion In Linguistics Vs. Recursion In RLMs: Why The Name Trips People
If you google “recursive language,” you fall into linguistics, Chomsky, and nested grammar structures. That’s not what’s happening here.
In Recursive Language Models, recursion is operational. It’s the same recursion you’d write in Python: solve a big problem by solving smaller versions of it, then stitch the results back together.
The paper’s point is that an LLM can choose to decompose, call itself on parts, and then compose an answer, all at inference time. The recursion is in the control loop.
4. The Core Shift: Prompt-As-Environment As A Mental Model
The move is simple.
Instead of feeding the long prompt into the neural network, treat the prompt as an object the model can interact with symbolically.
Concretely, an RLM initializes a programming environment, the paper uses a Python REPL, and stores the prompt as a variable. The model gets metadata like length and chunking, then writes code to peek, slice, search, and transform the prompt, observing outputs as it goes.
If you’ve ever built an llm memory architecture, this should feel familiar. It’s a memory hierarchy, but with the model itself deciding what to page in.
5. How An RLM Actually Runs: REPL, Peek, Decompose, Recurse
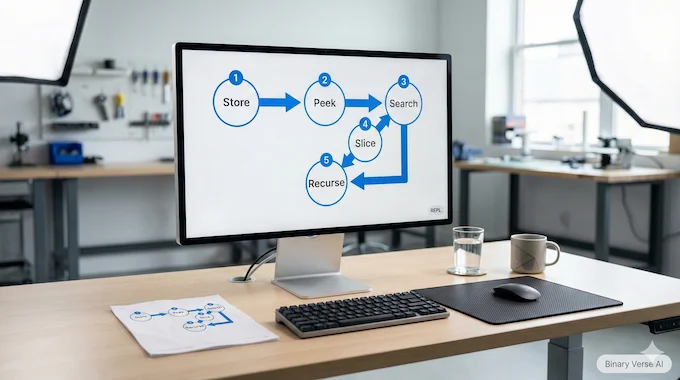
Here’s the loop, stripped of ceremony.
5.1 Load The Context Outside The Prompt
The system loads your giant document into the REPL as context. The root model does not receive the full text. It receives the query plus instructions about how to interact with context.
5.2 Let The Model Do Cheap IO First
Before “thinking,” the model can do quick IO: print a slice, split lines, count patterns, run regex, carve out candidate chunks. Then it spends tokens on the parts that matter.
5.3 Use Recursive Calls For Semantics
Regex can tell you where “festival” appears. It can’t tell you what the festival is about.
So the model can spawn a subcall on a small snippet to do semantic classification, extraction, or transformation, then store the result back into variables. That is the recursion.
5.4 Stop When You Have An Answer
In the paper’s implementation, the model eventually emits a final answer tag. The details are less important than the principle: the system is a loop with state, not a single forward pass.
6. RLM Vs RAG Vs Compaction: What’s Actually Different
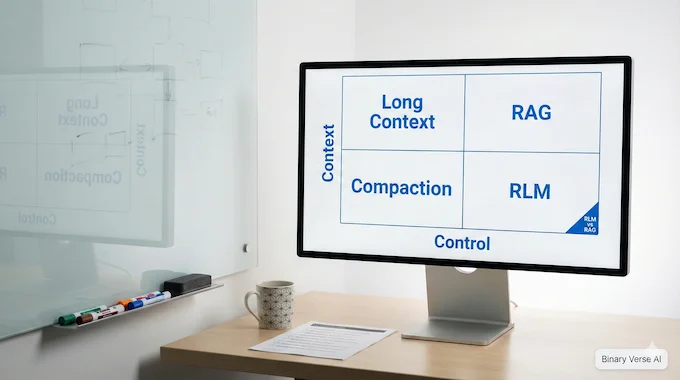
Most debates about long context collapse into a messy rlm vs rag argument. Let’s clean it up.
6.1 Compaction: Lossy By Design
Compaction and summarization are compression. Great, until the detail you threw away turns out to be the detail you needed.
The paper calls out the core limitation: compaction assumes earlier details can be safely forgotten to make room for later ones, which breaks for dense tasks.
6.2 RAG: Retrieval Is A Knife
RAG is fantastic when the problem is “find the right evidence, then reason.” It’s less great when the task is “use almost all the evidence,” because retrieval becomes a game of whack-a-mole.
That’s the classic rag vs long context trade. Retrieval narrows, long context includes, and both can fail.
6.3 Recursive Language Models: The Prompt Itself Becomes Queryable
Recursive Language Models change the interface. The prompt is not a blob of tokens you push into a model. It’s a large object living in an environment that the model can query and transform with code.
Here’s a practical comparison.
Recursive Language Models: Context Strategy Comparison
A practical side-by-side view of long context, compaction, RAG, and Recursive Language Models.
| Approach | Where The Full Context Lives | What Usually Breaks First | Best Fit |
|---|---|---|---|
| Long Context LLM | Inside the model window | Context rot, attention dilution | Needle tasks, short dense prompts |
| Compaction | A rolling summary inside the window | Lost details, brittle summaries | Conversational continuity, low-stakes compression |
| RAG | External index, evidence pulled into window | Recall gaps, wrong evidence | Search-heavy QA, knowledge bases |
| Recursive Language Models | External environment, programmatic access | Control loop tail risk | Dense aggregation, huge docs, codebases |
If you’re comparing rlm vs rag for production, this table is the quickest way to stop talking past each other.
7. “Isn’t This Just Claude Code, Subagents, Or Auto-Compaction?”
It’s fair to map Recursive Language Models onto existing tooling:
- Agents run loops.
- Tools let models search, parse, and execute code.
- Subagents isolate tasks and contexts.
The family resemblance is real. Two differences still matter.
7.1 The Boundary Is The Whole Point
Most agent systems keep the prompt as the center of gravity. Recursive Language Models flip that. The source of truth is outside, stable, and inspectable. The model pages pieces in on demand.
7.2 Compaction Assumes Forgetting, RLMs Assume Revisiting
Auto-compaction works when you can forget. Recursive Language Models are built for cases where you must revisit details repeatedly, and you cannot afford to lose them.
8. What The Paper Claims It Achieves, And Why OOLONG Matters
The authors frame Recursive Language Models as inference-time scaling for arbitrarily long prompts. They report handling inputs up to two orders of magnitude beyond model context windows, plus strong gains over base models and common scaffolds.
The evaluation includes tasks that scale differently with input length. OOLONG needs semantic transforms over chunks and aggregation over nearly all entries. OOLONG-Pairs goes further and pushes toward quadratic work.
One concrete slice from their results table: on GPT-5, the RLM reaches 56.5 on OOLONG vs 44.0 for the base model, and it turns OOLONG-Pairs from basically zero into 58.0 F1.
That’s the story in one sentence: the base model collapses on dense aggregation, and the RLM scaffolding keeps it upright.
They also stress that this isn’t just a benchmark party trick. In Observation 1, they argue the approach scales to the 10M+ token regime, and can beat base models and common task-agnostic scaffolds while keeping average costs in the same neighborhood. On a BrowseComp-Plus setting, they compare the theoretical cost of ingesting 6 to 11M tokens directly, about $1.50 to $2.75, to an average RLM cost of $0.99 while still outperforming summarization and retrieval baselines.
9. The Tradeoffs People Worry About: Cost Tails, Loops, And Control
Recursive Language Models buy reliability by introducing a control loop. Control loops can spin, over-check, or do expensive work a simpler policy would avoid.
The paper highlights the cost profile clearly. Median costs can be comparable or even lower, but the tail can spike because some trajectories get long.
9.1 The Budgets That Keep You Sane
- Iteration budget: how many REPL steps before you cut it off.
- Recursion budget: how many subcalls you allow, and at what depth.
- Time budget: wall-clock timeouts, because your users are not benchmarking, they’re waiting.
If you set none of these, you don’t get a clever system. You get a stochastic process with a credit card.
10. How To Use Recursive Language Models In Practice Without Turning It Into A Research Project
Treat Recursive Language Models as a pattern, not a religion.
10.1 Use Them When The Input Is Dense And Huge
Good fits: giant policy docs, codebase QA, aggregation over many entries, any “don’t approximate, compute it” workflow.
Bad fits: short prompts, creative writing, quick chat tasks where a base model already behaves.
10.2 Pick Two Models, On Purpose
A common cost trick is using a strong root model for decisions and a cheaper recursive model for subcalls. The paper reports using GPT-5 as the root and GPT-5-mini for recursive calls as a strong capability-cost tradeoff.
If you want something you can run today, you don’t need to reinvent the scaffolding. The paper’s core ingredients map cleanly to a small Python wrapper: store the full context in memory, give the model a REPL, and expose a helper that can make subcalls on slices. In other words, build a tiny harness for Recursive Language Models, then keep iterating on the budgets and the prompts.
10.3 A Minimal Checklist
- Choose root and recursive models.
- Set max depth and max iterations.
- Add caching for repeated slices and subcalls.
- Log every step and variable that matters.
- Add stop conditions that fire on progress, not vibes.
If you’re already using AI workflow automation tools, this drops in as one tool step: “handle long input with an RLM loop, return structured output.”
11. Where RLMs Fit In An Agent Orchestration Framework
An agent orchestration framework is a router. It decides which component should handle a request, maybe search, maybe code execution, maybe a specialized extractor.
Recursive Language Models slot in as the component that manages context. Orchestration chooses tools, the RLM loop chooses what parts of the prompt to inspect, and in what order.
Architecture diagram in words: Router routes to an RLM wrapper, the wrapper opens a REPL, the root model probes and slices context, subcalls handle semantics on chunks, tools like regex or parsers run in the environment, then the wrapper assembles and returns a final answer.
That’s also why “recursive llm” systems feel productive. You get a stable place to put state, and repeatable control over what the model actually reads.
12. Practical Limits, What To Watch Next, And A Simple Challenge
The paper is clear about what’s missing. The optimal mechanism is under-explored, synchronous subcalls can be slow, and there’s room for better implementations, including asynchronous calls and sandboxing.
They also used a recursion depth of one, and deeper recursion is a natural next axis to test.
Finally, today’s models are not trained to be great decision-makers over this kind of environment, and training could make the whole loop more efficient.
Now the challenge.
Pick one task you currently solve with either a long context llm or RAG, something where you get an answer but you don’t trust it. Wrap it in a tiny REPL loop that can peek, slice, and call a smaller model for semantic chunks. Give it budgets. Log the trajectory. Compare the output.
If it works, you just upgraded your interface between language models and reality. If it doesn’t, you’ll learn exactly where your pipeline leaks, and you can fix it.
Want more posts like this, the kind that turn new papers into patterns you can ship? Share this, subscribe, and send me your messiest long-context failure. I’ll happily turn it into a reproducible recipe.
What does “recursive language” mean?
In linguistics, recursion means rules can nest inside themselves (like clauses inside clauses). In RLMs, “recursive” means the system can re-invoke the model on smaller subparts of a prompt/workspace until it reaches a clean “base case” answer.
What is Chomsky’s theory of recursion?
Chomsky argued recursion is a core property of human language because it enables unlimited expression through nested structure. That idea is about grammar and cognition, not ML tooling, but it’s why “recursion” is a precise term and also easy to misuse in AI marketing.
What is the difference between RAG and long-context LLMs?
Long-context LLMs try to fit more tokens into the model’s window at once. RAG retrieves a few relevant chunks from an external store. RLMs treat the long prompt as external environment data the model can inspect programmatically, pulling only what it needs per step.
Will long-context LLMs make RAG obsolete?
Not reliably. Bigger windows help, but performance can still degrade as inputs get longer and more complex (context rot). RAG remains useful for fresh or external knowledge, while RLM-style control loops target stability and precision when the “input universe” is massive.
What is the difference between RAG and long-term memory?
RAG is retrieval at query time (fetch chunks, answer). Long-term memory is a broader system concept: what gets stored, how it’s updated, and how it’s used over time. RLMs sit closer to a control loop that decides what to inspect, when to recurse, and how to assemble a final answer, beyond simple top-k retrieval.