

Introduction
Open models used to come with a quiet warning label: fun for tinkering, risky for shipping. Then the new wave showed up and started taking points off the “frontier” scoreboard.
Qwen3.5 is firmly in that wave. If you build real systems, you care about three things more than hype: capability, cost to iterate, and how often the model makes you say, “Why did you do that.” This post is a practical, engineer-first qwen3.5 review of qwen 3.5 397b, specifically qwen3.5-397b-a17b, using the qwen3.5 benchmarks that actually map to work you do on Monday.
Table of Contents
1. Qwen3.5 In One Minute, The Verdict For Builders
If you only read one section, read this one.
You’re looking at an open-weight flagship that can play in the same neighborhood as top closed models on many “major rows”, and it has a very specific superpower: it’s unusually strong when the job looks like “search, synthesize, and don’t hallucinate while juggling lots of context.”
1.1 TL;DR, Best For, Avoid If
Best for
• Shipping agents that browse and summarize without melting down • Document-heavy pipelines: OCR, structured extraction, long reports • Multilingual workloads, especially if you mix English with CJK content • Teams that want leverage, meaning more experiments per dollar
Avoid if
• You need the single most reliable coding agent across messy repos • Your product breaks when tool calls get overconfident • Your latency budget is tight and you can’t tolerate slow “thinking” bursts • You want the simplest hosted experience with zero knobs
Below is a compact scoreboard. Treat it like a map, not a trophy shelf.
Table 1 — Language: major benchmarks (compact)
| Benchmark | GPT5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen3-Max-Thinking | K2.5-1T-A32B | Qwen3.5-397B-A17B |
|---|---|---|---|---|---|---|
| MMLU-Pro | 87.4 | 89.5 | 89.8 | 85.7 | 87.1 | 87.8 |
| SuperGPQA | 67.9 | 70.6 | 74.0 | 67.3 | 69.2 | 70.4 |
| IFEval | 94.8 | 90.9 | 93.5 | 93.4 | 93.9 | 92.6 |
| LongBench v2 | 54.5 | 64.4 | 68.2 | 60.6 | 61.0 | 63.2 |
| GPQA | 92.4 | 87.0 | 91.9 | 87.4 | 87.6 | 88.4 |
| HLE-Verified | 43.3 | 38.8 | 48.0 | 37.6 | — | 37.6 |
| LiveCodeBench v6 | 87.7 | 84.8 | 90.7 | 85.9 | 85.0 | 83.6 |
| SWE-bench Verified | 80.0 | 80.9 | 76.2 | 75.3 | 76.8 | 76.4 |
| TAU2-Bench | 87.1 | 91.6 | 85.4 | 84.6 | 77.0 | 86.7 |
| BrowseComp (best reported) | 65.8 | 67.8 | 59.2 | 53.9 | 74.9 | 78.6 |
Note: “BrowseComp (best reported)” uses the higher score when two strategies were listed.
2. What Qwen3.5 Is, And What Changed Vs Earlier Qwen
Let’s pin down the object we’re talking about: Qwen3.5-397B-A17B. This is the first open-weight release in the series, positioned as a native vision-language model, not “text-only with a vision adapter stapled on later.”
What changed, in plain terms:
• The training recipe leans hard into agent-style reinforcement learning and tool use, not just next-token prediction. • The architecture is built to keep inference efficient, even at a huge parameter count. • Multilingual coverage expanded a lot, which matters if your inputs are not polite English blog posts.
Also, “open” here is a practical promise: you can deploy it under your own constraints, audit behaviors, and avoid putting your core product behind someone else’s rate limit mood swings.
3. 397B-A17B Explained, Why The Name Matters In Practice
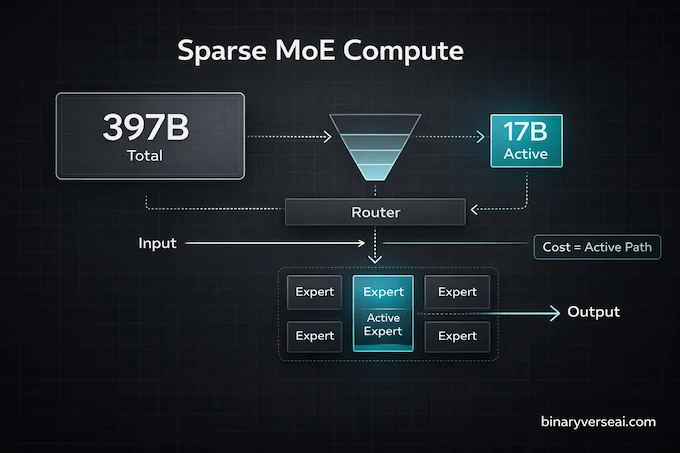
Model names usually read like GPU marketing. This one actually carries a useful hint.
• 397B is the total parameter count. • A17B means roughly 17B parameters are active per forward pass, which strongly suggests a sparse mixture-of-experts style of compute.
So yes, the short answer to the Reddit question is: it behaves like a sparse model in how it spends compute. You pay for the active path, not the full 397B every token.
Why you should care:
• Serving cost and latency are shaped more by active parameters than headline size. • Throughput can be surprisingly good if your stack is built for it. • It changes the economics of iteration, which is where engineering velocity hides.
4. Context And “Thinking Mode”, The Hidden Lever That Changes UX

There are two versions of “the model you tested” living inside every modern flagship.
Version one: fast, direct, good enough for most queries. Version two: slower, more deliberate, spends tokens on reasoning, and sometimes gets you that last 10 percent of correctness.
This family leans into that split. Long context is a big part of the pitch, with claims around the 262K range for the open model, and much higher for hosted variants. In real work, long context is less about bragging rights and more about reducing glue code.
Things long context enables:
• Retrieval where you can keep more raw evidence in the prompt • Long files, multi-document synthesis, and “read the whole repo” style tasks • Agents that keep tool output without pruning it into nonsense
Practical rule: if latency matters, cap reasoning. If correctness matters, let it think, but measure the token bill like an adult.
5. Benchmarks That Matter, A Clean Scoreboard And How Not To Get Fooled
Benchmarks are useful, but only if you treat them like lab instruments. Good instruments still lie when you use them wrong.
Here’s a quick mental model:
• Knowledge and exams correlate with broad training coverage and pattern recall. • Instruction following correlates with alignment and format discipline. • Agent and browsing benchmarks correlate with tool behavior, context management, and restraint. • Coding benchmarks correlate with both reasoning and the model’s ability to stay grounded in code structure over many steps.
5.1 Benchmark Hygiene, The Checklist People Skip
If you want results that survive contact with production, keep these straight:
• Prompting parity: same system prompt, same tool schema, same constraints • Tool harness parity: identical browsing pipeline, same truncation rules • Contamination risk: popular benchmarks leak into training data ecosystems • Iteration cost: latency plus token spend, not just accuracy
A model can “win” and still be the wrong pick for your stack if it costs twice as much per successful patch.
6. Where Qwen3.5 Beats Top Closed LLMs, With Receipts
This is the part everybody wants, and it’s also the part most reviews do lazily. The trick is to connect the score to a behavior you can predict.
6.1 Knowledge And Exams
The compact language table shows it in the same ballpark on MMLU-Pro and SuperGPQA. It is not the universal top, but it is competitive enough that “open model” no longer means “accept a big drop.”
What that usually looks like in practice: strong recall plus decent reasoning, especially when you provide context and ask for structured answers.
6.2 Agentic Search And Browsing
That BrowseComp number is loud. It suggests the model has a good instinct for search loops: query, read, revise, and avoid confidently inventing details.
That maps directly to:
• Research assistants that cite evidence • “Find the relevant paragraph, then answer” workflows • Competitive analysis, doc synthesis, and long-thread summarization
This is where Qwen3.5 can feel like it “punches above” because the wins show up as fewer broken loops.
6.3 Vision, Docs, And OCR
Now the fun part: vision-language. If your work involves PDFs, screenshots, dashboards, receipts, forms, or any “why is this table broken” pain, pay attention.
Table 2 — Vision-Language: major benchmarks (compact)
| Benchmark | GPT5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen3-VL-235B-A22B | K2.5-1T-A32B | Qwen3.5-397B-A17B |
|---|---|---|---|---|---|---|
| MMMU | 86.7 | 80.7 | 87.2 | 80.6 | 84.3 | 85.0 |
| MMMU-Pro | 79.5 | 70.6 | 81.0 | 69.3 | 78.5 | 79.0 |
| MathVision | 83.0 | 74.3 | 86.6 | 74.6 | 84.2 | 88.6 |
| RealWorldQA | 83.3 | 77.0 | 83.3 | 81.3 | 81.0 | 83.9 |
| HallusionBench | 65.2 | 64.1 | 68.6 | 66.7 | 69.8 | 71.4 |
| MMBenchEN-DEV-v1.1 | 88.2 | 89.2 | 93.7 | 89.7 | 94.2 | 93.7 |
| OmniDocBench1.5 | 85.7 | 87.7 | 88.5 | 84.5 | 88.8 | 90.8 |
| OCRBench | 80.7 | 85.8 | 90.4 | 87.5 | 92.3 | 93.1 |
| VideoMME (w sub.) | 86.0 | 77.6 | 88.4 | 83.8 | 87.4 | 87.5 |
| OSWorld-Verified | 38.2 | 66.3 | — | 38.1 | 63.3 | 62.2 |
Read those doc and OCR rows like a product spec. In day-to-day pipelines, “better OCRBench” often means “less time cleaning garbage text,” which means fewer brittle heuristics and fewer angry bug reports.
7. Where Qwen3.5 Does Not Beat Them, And Why You’ll Notice
Strong models still have sharp edges, and it’s better to name them now than to discover them in a user incident report.
7.1 Coding Agent Reliability
On SWE-bench Verified, the very top closed coding agents still look steadier. That matters if your product is “agent fixes issues in a repo and opens a PR” and you need success rates that don’t wobble with prompt tweaks.
7.2 Long Context Is Not The Same As Long Attention
Big context windows can produce a specific failure mode: the model “read it,” but didn’t use it. You’ll see summaries that sound plausible while missing the one line that mattered, or plans that ignore a constraint stated 30K tokens ago.
7.3 Tool Overconfidence And Planning Drift
When models get good at tools, they also get good at sounding like they used them. The gap between “I called the tool” and “I integrated the result correctly” is where drift lives.
If you deploy it in agent mode, add guardrails:
• Verify tool outputs are referenced, not just acknowledged • Demand structured intermediate artifacts, like checklists and extracted facts • Use evaluation prompts that punish confident errors
8. Qwen3.5 Vs GPT Vs Claude Vs Gemini, Pick By Job To Be Done
This section is where “model taste” becomes engineering decision-making.
8.1 Qwen3.5 Vs GPT
If you care most about strict instruction following and clean format discipline, GPT-style models often feel like a safer default. If your workload is more browse-heavy and document-heavy, the open model’s strengths can show up as fewer broken research loops.
8.2 Qwen3.5 Vs Claude
Claude tends to feel unusually reliable in long, messy coding or agent workflows where the model needs to keep a stable plan. If your main pain is PR-quality code changes, Claude often stays calmer. If your pain is documents, OCR, or multilingual inputs, the open model can claw back wins fast.
8.3 Qwen3.5 Vs Gemini
Gemini’s scores on several knowledge and long-context rows are hard to ignore, and it often looks extremely consistent on broad reasoning. If you want “strong everywhere” and you are fine living inside a closed ecosystem, it’s a strong pick. If your differentiator is owning the stack and squeezing iteration cost, open weights are the leverage play.
8.4 Qwen3.5 Vs Closed LLMs
Here’s the honest framing: closed models still dominate the “no excuses, ship it tomorrow” path. Open models dominate the “we want control, economics, and customization” path. The gap is shrinking, but your constraints decide which side wins.
9. Real-World Tests You Should Run Before Switching

Benchmarks are the trailer. Your workload is the full movie.
Run a tiny harness, not a week-long migration. Five tests, copy-paste simple:
- Function calling JSON: generate strict schema output, then validate it
- Repo bugfix: one failing test, one file edit, one PR-style explanation
- Long PDF: summarize, then answer targeted questions with quoted evidence
- Agent plan: multi-step tool plan with explicit stop conditions
- Refusal edge case: safety boundaries plus “offer safe alternative” behavior
Measure two numbers:
• Success rate • Cost per success, meaning tokens plus latency plus retries
That second number is where you’ll find your real ROI.
10. API + Pricing, Qwen3.5 Models And What You Actually Pay For
Keep pricing talk in one place. Here it is.
If you want hosted access, you’ll run into qwen3.5 api options and tiering like qwen3.5 pricing versus qwen3.5 plus pricing. The hosted “Plus” line, often written as qwen3.5-plus, is positioned as the smoother production experience, with larger context tiers and built-in tool support.
The phrase you’ll see in documentation and calculators is Alibaba Cloud Model Studio qwen3.5 pricing. That is the cluster to watch if your goal is to estimate tokens-per-feature and compare providers cleanly.
One practical note: if “thinking mode” is metered differently from “fast mode,” treat it like a product knob. You will tune it. Your users will tune it. Your finance team will definitely tune it.
11. Can You Run It Locally, Answering The Reddit Question Without Derailing
Open weights do not magically turn 397B into a weekend project.
The sane answer:
• You probably won’t run the full model locally unless you have serious hardware and a serving stack built for sparse models. • You might run quantized variants, distilled variants, or smaller siblings locally for prototyping. • If your goal is privacy and control, self-hosting can still win, but plan it like infrastructure, not like a hobby.
If you want to go deep on quantization, vLLM tuning, and throughput expectations, that deserves its own post. This one stays focused on what the model does, not how many GPUs you can rent.
12. Final Take, When Qwen3.5 Is The Best Move, And When It Isn’t
Let’s land this.
Choose Qwen3.5 if:
• Your product is document-heavy, OCR-heavy, or multilingual • You want strong browsing and research loops with fewer hallucinated leaps • You value control, customization, and iteration economics as first-class features
Choose a closed model if:
• You need the most reliable coding agent behavior across chaotic repos • You want the simplest “it just works” hosted path with fewer knobs • Your latency budget is strict and you cannot afford slow reasoning bursts
Here’s the move that actually works: run the five-test harness, score cost per success, then decide with data. If you’re building anything serious, you don’t pick a model the way you pick a mascot. You pick it the way you pick a database: by failure modes, by costs, and by how it behaves under load.
If you want, grab this post’s harness outline, run it on your real inputs, and publish your results. And if you’re building agents, benchmarks are the warm-up. The real competition is your users’ patience.
1) Is Qwen3.5 actually open-source (or just open-weights)?
Qwen3.5 is best described as open-weights. The model weights are published under a permissive license, but “open-source” usually implies the full training recipe, data, and pipeline are also available—which is rarely fully true for frontier-scale models.
2) What does “397B-A17B” mean, and is Qwen3.5 a MoE model?
“397B-A17B” means ~397B total parameters with ~17B activated per token. Yes, this points to a sparse Mixture-of-Experts (MoE) design, where only a subset of experts “fire” per token, improving inference efficiency versus a fully-dense 397B.
3) How do Qwen3.5 benchmarks compare vs GPT / Claude / Gemini—and which benchmarks matter most?
Benchmarks only matter if they match the task you care about. Use MMLU-Pro / GPQA for knowledge & hard reasoning, IFEval for instruction-following, LongBench v2 for long-context, and agent/tool benchmarks (like browsing/search tasks) for real workflows. Avoid over-weighting a single leaderboard row.
4) Can I run Qwen3.5 locally—what hardware/VRAM do I realistically need?
Running the full 397B model locally is multi-GPU territory. Even though only ~17B is “active” per token, you still must store the full weights:
4-bit: roughly ~200GB+ just for weights (plus overhead) → typically 3–4× 80GB GPUs
8-bit: roughly ~400GB+ → typically 6× 80GB GPUs
Add more headroom for KV cache at long context (this can dominate at 256K).
Practical path: use server inference, or run a smaller Qwen3.5 variant/quant for local experiments.
5) How do Qwen3.5 API pricing and Qwen3.5-Plus pricing work (especially for long context and “thinking” mode)?
Pricing is usually per-token (input + output), and long context increases cost via longer prompts + larger KV cache. “Thinking” mode often adds internal reasoning tokens/steps that may be billed (or indirectly increase billed output). For predictable spend: cap context, cap max output tokens, and use thinking only when the task truly needs it.
Fact anchors used above (name/architecture/positioning): the “397B total / 17B activated” and MoE framing is explicitly reflected in major model-card style sources and runtime listings.