

Introduction
A lot of model releases are loud in all the predictable ways. Bigger number, bigger chart, bigger promise. Then once in a while a small model lands that forces a more interesting question: what if we are finally learning to spend training signal wisely, instead of just spending more training?
That is the vibe around LFM2-2.6B-Exp. It is not a brand-new architecture flex. It is not a new “magic context length” story. It is a relatively compact checkpoint that claims meaningful gains from reinforcement learning, and then backs it with benchmark deltas that are hard to ignore.
Table of Contents
1. LFM2-2.6B-Exp In One Paragraph, And Who This Review Is For
If you want the short version, LFM2-2.6B-Exp is an experimental checkpoint built on LFM2-2.6B, trained with what Liquid AI calls “pure reinforcement learning,” and tuned to get sharper at instruction following, knowledge, and math. It is positioned as a strong small model for agentic workflows, extraction, RAG, and multi-turn chats, while explicitly not being the best pick for programming or deeply knowledge-intensive work. If your mental model of “small model” is still “cute but unreliable,” this is the sort of release that tries to update it.
This review is for you if:
- You deploy edge ai workloads and care about capability per watt, not bragging rights per parameter.
- You are building agents, pipelines, or tools where instruction discipline matters more than vibes.
- You keep hearing “pure RL” and want the non-marketing explanation.
This review is not for you if:
- You want a universal model that codes, reasons, and encyclopedias flawlessly.
- You want one benchmark number to end all debates.
LFM2-2.6B-Exp Quick Answer Table
Clean, mobile-friendly summary of what matters, in two columns.
| Quick Answer | What To Know |
|---|---|
| What is it? | LFM2-2.6B-Exp is an experimental post-trained checkpoint on top of LFM2-2.6B, aimed at instruction following, knowledge, and math. |
| Why the buzz? | Large gains on instruction-following benchmarks and a surprisingly strong math bump for this size class. |
| Best fit | Agentic tasks, data extraction, RAG, creative writing, multi-turn chat, especially when you want lighter infra. |
| Weak spots | Knowledge-heavy tasks and programming, according to Liquid AI’s own guidance. |
| Deployment vibe | A realistic candidate for an on device llm workflow, depending on your quant, memory budget, and latency target. |
| Training headline | Reinforcement learning with verifiable rewards, which matters more than the phrase “pure.” |
2. What LFM2-2.6B-Exp Actually Is
Let’s ground this before the discourse runs away with it.
LFM2-2.6B-Exp is not “a new model family.” It is a checkpoint built on the existing LFM2-2.6B base. In practical terms, that means:
- Same general backbone, same context length target, same overall footprint expectations.
- Different behavior in the places post-training tends to reshape, like instruction following precision, formatting, refusal style, and step-by-step discipline.
Liquid AI describes it as specifically trained for instruction following, knowledge, and math. That triad is telling. It is basically the modern stack of “things users actually notice” when they ask, “is this model smart,” and then punish it with messy prompts.
Also, the architecture detail matters, even if you never want to read another block diagram. LFM2 is a hybrid design that mixes short convolutions with attention. That is an efficiency bet that fits Liquid AI’s broader story: models that are less allergic to real devices and real budgets.
3. “Pure Reinforcement Learning” Explained Without Marketing
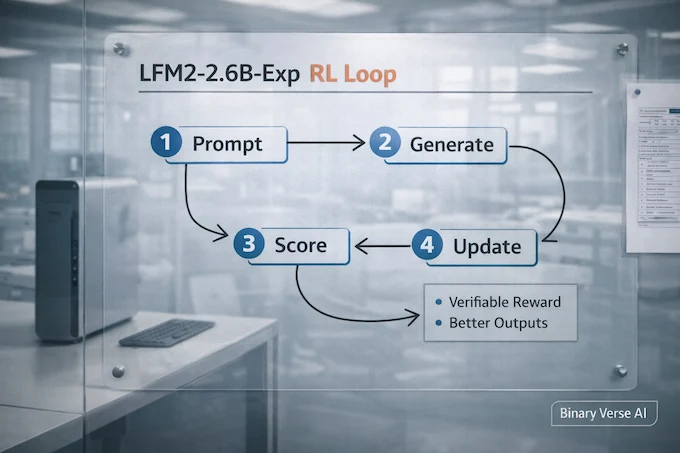
This is where Reddit skepticism is healthy. The phrase “pure reinforcement learning” sounds like the model crawled out of a lab where it learned everything through reward signals, like a robot discovering physics by bonking into walls.
In reality, modern post-training pipelines are usually a layered cake:
- Pretraining
- Supervised fine-tuning
- Preference tuning (DPO and friends)
- Reinforcement learning steps (RLHF, RLVR, or variants)
So what does “pure” mean here?
My interpretation, reading between the lines, is not “no supervised learning ever existed.” It is more like “this checkpoint’s improvement phase leaned heavily on reinforcement learning, rather than being mostly another round of supervised instruction tuning.” That still counts as reinforcement learning in ai, it just is not mystical.
3.1 What Is Reinforcement Learning, In Plain Language
If you have ever asked what is reinforcement learning, here is the shortest useful version.
A model generates an answer. Some scoring mechanism rewards or penalizes it. Training pushes the model toward answers that score better. The whole trick is choosing rewards that correlate with what you actually want in the wild.
3.2 Why “Verifiable Rewards” Changes The Feel
“Verifiable rewards” is the important phrase. It suggests the reward is not just a fuzzy preference model saying “I like this tone.” It implies tasks where correctness can be checked, even approximately, using rules, tools, or structured evaluation. That aligns with why deep reinforcement learning can produce crisp gains in things like format adherence, multi-step math patterns, and instruction compliance.
In other words, when people say LFM2-2.6B-Exp feels more disciplined, this training story is a plausible reason.
4. Benchmarks Table, What Each One Means, And What Not To Overread
Benchmarks are useful, and also a great way to trick yourself. They do not measure “intelligence.” They measure “how well a model does on this particular set of questions under this particular setup.”
Still, the deltas here are large enough to matter.
4.1 LFM2-2.6B-Exp Benchmark Comparison
LFM2-2.6B-Exp Benchmark Table
Side-by-side scores across small-model peers. Scroll horizontally on mobile.
| Benchmark | LFM2-2.6B-Exp | LFM2-2.6B | Llama-3.2-3B-Instruct | Granite-4.0-micro | SmolLM3-3B | Gemma-3n-E2B-it |
|---|---|---|---|---|---|---|
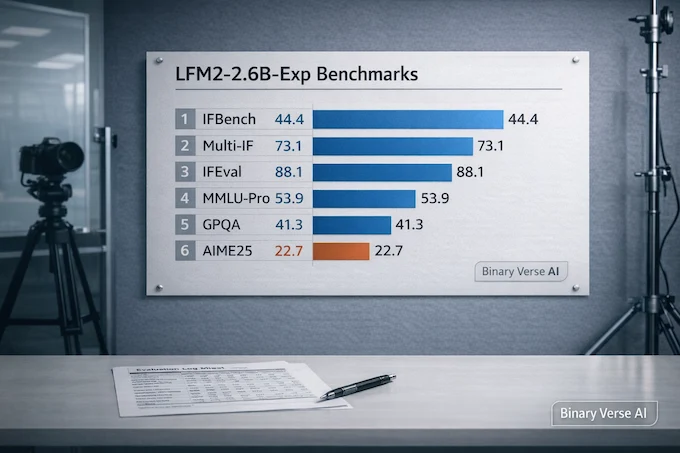
| IFBench | 44.40 | 24.73 | 23.67 | 24.00 | 19.93 | 23.73 |
| Multi-IF | 73.05 | 60.46 | 50.93 | 57.96 | 58.86 | 60.29 |
| IFEval | 88.13 | 81.25 | 73.49 | 82.36 | 74.55 | 74.57 |
| MMLU-Pro | 53.87 | 47.59 | 35.98 | 41.65 | 53.62 | 39.76 |
| GPQA | 41.31 | 33.84 | 21.72 | 28.28 | 28.99 | 31.11 |
| AIME25 | 22.67 | 9.83 | 0.67 | 1.00 | 10.00 | 8.67 |
4.2 How To Read These Without Getting Played
- IFBench, Multi-IF, IFEval: Instruction following tests. Think formatting, constraints, “do exactly this and nothing else.” These are the benchmarks that correlate with whether your agent workflow breaks at 2 a.m.
- MMLU-Pro: Broad knowledge and reasoning under pressure. Not perfect, but a decent “does it know things” proxy.
- GPQA: Harder science-style questions. It tends to punish shallow pattern matching more than many popular sets.
- AIME25: Math, and a particularly unforgiving kind. It is not “math in the real world,” but it does catch whether a model can hold a multi-step chain together.
The key observation is not “it wins.” The key observation is the shape of improvement. LFM2-2.6B-Exp jumps hardest where reinforcement learning with checkable rewards tends to shine: instruction discipline and certain math behaviors.
5. The Real Story Behind The Big Claim, Punching Above Weight
There is a marketing line floating around that its IFBench score surpasses a model hundreds of times larger. Even if that is true on that benchmark, you should not translate it into “it is better than giant models.”
Here is the responsible version of “punches above its weight”:
- On instruction-following slices, the model behaves like it has learned to take constraints seriously.
- That can make it feel “smarter” in product workflows than a larger model that is more powerful but less obedient.
- It does not mean it has absorbed a larger world model. It means it is better trained to hit the target you are pointing at.
If you build agents, this distinction is not academic. A smaller, more reliable model can beat a larger, more chaotic one because reliability compounds across steps.
6. What Changed From LFM2-2.6B Base
The table is basically the story.
- Instruction following: big jump across IFBench and Multi-IF, plus a solid bump on IFEval.
- Knowledge and science: GPQA rises meaningfully.
- Math: AIME25 more than doubles compared to the base.
This is the signature of a post-training shift, not a new pretraining mountain.
If you have watched reinforcement learning in ai evolve over the last few years, this makes intuitive sense. RL tends to improve:
- Formatting and constraint adherence
- Step discipline on problems with verifiable structure
- Refusal and safety style consistency
- “Do what I asked” behavior in multi-turn contexts
That is exactly the vibe these numbers suggest.
7. Where It Fits In Practice, Agents, Extraction, RAG, Multi-Turn
Liquid AI’s own recommendations are unusually clear: agentic tasks, data extraction, RAG, creative writing, multi-turn conversations.
That list is basically a map of “workflows where you need a model to follow instructions and keep its story straight.”
7.1 RAG And DMS Search, The Question People Keep Asking
Is LFM2-2.6B-Exp “smart enough” for RAG and document management search?
My expert take, as someone who has built these systems, is that RAG quality is rarely limited by raw model IQ first. It is limited by:
- Retrieval quality (indexing, chunking, metadata, reranking)
- Prompt structure (how you constrain citations and scope)
- Latency budget (how many retrieval hops you can afford)
- Guardrails (how you prevent confident nonsense)
A more disciplined model helps because it follows “use the retrieved text, cite it, do not invent” instructions better. That is where instruction-following gains matter.
So yes, it can be a good fit, especially if you want smaller infra. But do not expect it to rescue a weak retrieval pipeline.
7.2 Extraction Work Loves Disciplined Models
If your workflow is “take messy input, output strict JSON,” then LFM2-2.6B-Exp is the kind of checkpoint worth trying. In extraction, a model that obeys schemas is often more valuable than a model that can write poetry about the schema.
8. The Limits, Knowledge-Intensive Work And Programming
Here is the part many reviews skip because it is less exciting: Liquid AI explicitly says they do not recommend these models for knowledge-intensive tasks or programming.
That can coexist with strong scores. Benchmarks are slices. Programming requires long-horizon correctness, toolchains, and the ability to hold invariants across many steps. Knowledge-intensive work punishes hallucinations, especially in obscure corners.
A small model can score well on structured tests and still struggle when you ask it to write a correct, non-trivial program that compiles, passes tests, and stays sane across refactors.
So if your main goal is code, treat LFM2-2.6B-Exp as a specialist, not a replacement for your coding workhorse.
9. How To Run LFM2-2.6B-Exp Without Losing An Afternoon
If you want the fastest path, use Transformers or vLLM first. Save GGUF for when you want local CPU deployment or an embedded flow.
9.1 Transformers Path, The Sensible Default
- Install a recent transformers version.
- Use the model’s chat template rather than hand-rolling prompts.
- Start with conservative sampling: low temperature, light repetition penalty.
A common failure mode is forgetting the template, then concluding the model is “weird.” It is not weird, you just spoke the wrong dialect.
9.2 vLLM Path, When You Want Throughput
vLLM is the “I have many prompts and I do not want pain” option. If you are building a local service, it is often the cleanest path to a real deployment.
9.3 llama.cpp And GGUF, When You Want Device Reality
GGUF is where the offline ai models story becomes real, and also where most support headaches live:
- Wrong quant for your device
- Template mismatch
- Confusing performance expectations
Treat GGUF as a deployment format, not a magic trick. You still need to budget memory, cache, and latency.
10. On-Device LLM Reality Check, Android, iPhone, Offline

People love the phrase “on-device” because it sounds like freedom. No cloud. No latency roulette. No surprise bill.
But “on device llm” does not mean “runs great on any phone.” It means you are doing a three-way trade:
- Model size and quantization
- Speed
- Quality
LFM2-2.6B-Exp sits in a sweet spot where it is plausible to run locally with the right quant and hardware, but you still need to be honest about constraints. Phones vary wildly. NPUs vary even more. And context length is not free, not on a laptop, not on a server, and definitely not in your pocket.
If you care about edge ai deployments, here is the practical advice:
- Start with a quant that fits comfortably.
- Measure tokens per second on your real workload, not a demo prompt.
- Validate tool calling and structured output early, because that is where “it worked once” becomes “it broke in production.”
11. Pricing And Licensing, What’s Free, What’s Not
Liquid AI’s pricing story is refreshingly straightforward at the high level: self-service access is positioned as free, and commercial use has thresholds and exclusions.
The detail that matters for builders is whether your use qualifies under the free commercial allowance, and what happens if you grow past it. This is not just legal hygiene. It changes whether you build on it today or treat it as a research toy.
If you are deploying in a company setting, read the license like an engineer reads a dependency license. Do not outsource it to vibes.
12. Comparisons, When To Pick This Over Llama 3.2 3B, SmolLM3-3B, Gemma Variants
Comparisons are where people actually make decisions.
Here is how I would choose, using the benchmark deltas and the deployment reality as the anchor:
12.1 Pick LFM2-2.6B-Exp When
- You need instruction adherence to be a first-class feature.
- You are building structured outputs, tool calls, extraction, or agent loops.
- You want a credible path to smaller infra, including edge ai and offline ai models setups.
- You want strong “small model math vibes” without jumping into much larger footprints.
12.2 Pick A Peer Model When
- You prioritize coding and long-horizon correctness over instruction discipline gains.
- You need stronger general knowledge across weird domains.
- Your stack already has best-in-class support for another family, and switching adds friction.
12.3 My Bottom Line
LFM2-2.6B-Exp looks like a serious attempt to squeeze more capability out of a small footprint by leaning on reinforcement learning with verifiable rewards. That is the right direction. Not because it makes for spicy charts, but because it attacks the part of model quality that hurts builders most: reliability under constraints.
If you are building agents, RAG, or extraction pipelines, download it and run three tests that match your reality:
- Strict JSON output under messy prompts.
- Multi-turn constraint tracking.
- Retrieval-grounded answers that must stay inside supplied context.
Then tell me what broke. That is where the real review begins, and where small models either become tools you trust, or demos you forget.
If you want a practical next step, try LFM2-2.6B-Exp as your “obedient worker” model inside a pipeline, and keep a larger model as the “deep reasoning escalator.” That hybrid approach is how teams actually ship.
What does Liquid AI do?
Liquid AI builds ultra-efficient foundation models designed to run not just in the cloud, but on CPUs, GPUs, and NPUs for low-latency and privacy-sensitive use cases. They also offer tooling (like LEAP) aimed at getting models deployed directly on devices.
Who is the CEO of Liquid AI?
Liquid AI’s CEO is Ramin Hasani, who is also listed as a co-founder of the company.
How to invest in Liquid AI?
Liquid AI is not publicly traded, so you cannot buy it like a normal stock on NYSE or Nasdaq. Access is typically through private fundraising rounds (if you have access) or secondary marketplaces that match eligible buyers and sellers of private shares, usually for accredited or institutional investors.
What is full reinforcement learning?
In plain terms, “full reinforcement learning” means the model is trained by trying outputs, getting a reward signal that scores those outputs, and then updating itself to produce higher-reward answers more often. In the LFM2-2.6B-Exp context, Liquid describes the checkpoint as built using “pure reinforcement learning,” meaning RL is the headline driver of the experimental post-training step.
Can I run an LLM on my phone?
Yes, but “on device LLM” has real limits. You need a small model, quantization (often), and a runtime that fits your phone’s RAM and compute. Liquid AI explicitly positions its models and tooling toward edge AI deployments, including mobile scenarios, and also provides an app experience (Apollo) for testing on phones.