

You can tell a lot about a platform from the first minute you talk to it. With the gpt-realtime API, that first minute feels like you are chatting with an engineer who also happens to sing in tune. It hears you, answers quickly, and does not make you wait while a daisy chain of services argues over who owns the waveform. That is the shift. Speech is no longer a bolt on. It is native.
What follows is a practical, clear path to build a voice agent that you would be happy to ship. We will keep it grounded in real constraints, performance, and the craft of product quality. We will also use the OpenAI Agents SDK, since it removes a lot of the plumbing that usually sends weekend projects into orbit.
Table of Contents
1. Why Voice, Why Now
The classic stack for voice was a relay race. One model listened, another wrote, a third one spoke. Each hop added latency and shaved nuance off the edges. The gpt-realtime API collapses that pipeline into a single, speech-native model that handles listening and speaking in one continuous loop. Fewer moving parts. More fidelity. Lower latency. Stronger instruction following.
For builders, this changes the surface area. You can build a voice agent that understands laughter, pauses, accents, code words, and alphanumerics. You can keep the audio thread flowing while tools run in the background. You can add an image mid-call and ask, “what do you see.” And you can take the whole thing to production without duct tape.
2. What The gpt-realtime API Gives You
Here is the quick map of capabilities and what they mean for a team that wants to build a voice agent without shipping a ball of yarn.
| Capability | What You Get | Where It Lives | First Move |
|---|---|---|---|
| Speech-to-speech core | Single model that hears and speaks with natural prosody | gpt-realtime API | Start with a default voice, then tune pace and clarity |
| WebRTC in the browser | Very low latency round trip, mic in and audio out | OpenAI Agents SDK | Use the SDK’s RealtimeSession to attach mic and speaker |
| WebSocket on servers | Stable, low jitter connection for middle tiers | gpt-realtime API | Use WS for server bots or transcription bridges |
| SIP calling | Route the same agent to phone numbers and PBX systems | OpenAI Realtime voice API | Prototype IVR handoffs before you scale |
| Image input | Ground the conversation in what the user sees | gpt-realtime API | Add a screenshot mid-call and ask for details |
| Function calling | Let the model call tools with strong argument accuracy | OpenAI Agents SDK | Define a few high-value tools and add rules for when to call them |
| MCP servers | Plug external capabilities in a clean, discoverable way | gpt-realtime API | Point the session at a remote MCP server to unlock actions |
| Prompt reuse | Versioned prompts you can pin per session | OpenAI Realtime API documentation | Store one prompt for consistency across teams |
| Async tool waits | Keep talking while functions run | gpt-realtime API | Do not freeze the conversation during long calls |
| Data residency and privacy controls | Enterprise-grade guarantees | OpenAI Realtime API documentation | Pick the residency you need and log responsibly |
You will notice one theme. The gpt-realtime API does not ask you to “integrate twelve things to get sound.” It gives you a tight loop, then a clean path to extend it with tools when you are ready.
3. The Minimal Architecture That Scales
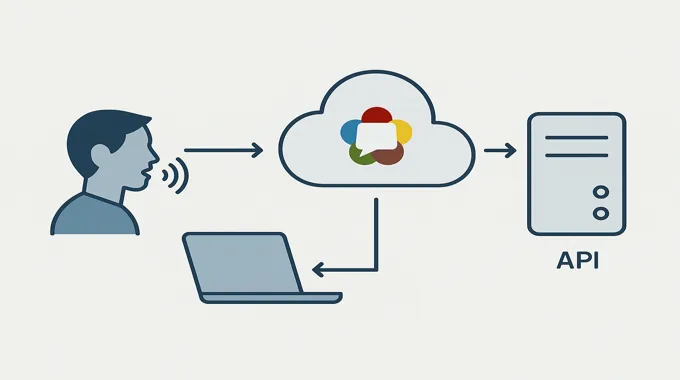
You only need two pieces.
- A tiny server that mints a short-lived client secret for the browser. Never ship a long-lived API key to the client. Your server calls the platform, receives a time-boxed secret, and hands it to the browser.
- A simple web page that uses the OpenAI Agents SDK. The SDK speaks WebRTC to the gpt-realtime API, connects your microphone, and streams audio back to the speakers.
With this split, you get strong security, the snappy feel of WebRTC, and the ability to add tooling on the server side without exposing anything you should not.
4. A Ten Minute gpt-realtime Tutorial In The Playground
If you want a no-infrastructure start, the Playground is perfect. Pick the gpt-realtime API model, enable the mic, select a voice like Marin or Cedar, then paste a tight system prompt:
Say “Hello, what can you do.” You will hear a reply and see live transcripts. Attach an image and ask a question about it. When the flow feels right, click View code. The Playground will export a snippet that matches your exact settings. That is your seed for a gpt-realtime tutorial or demo repo.
5. Ship It, A Tiny Working Example With The OpenAI Agents SDK
Here is a compact example that readers can drop into a single file to build a voice agent. The page connects your mic, streams to the gpt-realtime API over WebRTC, and plays the response. The logic is intentionally small, so you can see the shape clearly.
Swap the voice to Cedar if that better matches your brand. Add outputModalities: [“audio”] if you want a voice-only vibe. Keep this page behind an internal login while you test. Then move the short-lived token endpoint behind your production auth.
This is the smallest possible loop that still feels like magic. It is also the right baseline for a serious gpt-realtime tutorial.
6. Prompting That Works For Voice
Voice agents live or die by the first five words they say. The gpt-realtime API follows short, precise rules. Treat your system prompt like a micro-style guide.
- Keep instructions in bullets. Two to four lines is plenty.
- Lock language behavior. Match the user’s language by default, or pin English for a support line.
- Add a variety rule. It prevents robotic repetition during long sessions.
- Define a turn taking policy. Use semantic VAD in the session config and remind the agent to wait for the user to finish.
- Include a short escalation line. If the user asks for a human or seems frustrated, say your handoff phrase, then trigger the tool.
The goal is not poetry. It is consistent behavior that you can repeat across teams. If a sentence is ambiguous, rewrite it. If two rules fight, delete one. Your future self will thank you.
7. Tools, Function Calls, And MCP
A great voice agent does not just talk. It checks, fetches, and acts. The OpenAI Agents SDK lets you define functions that the model can call with arguments that usually match what you would have written yourself. Think of them as verbs you are willing to perform on the user’s behalf.
A clean pattern is a one-line preamble before each tool call. For example, “I am checking that now.” Then call the tool. This keeps the conversation transparent. With MCP servers in the loop, you can plug in capabilities without hard wiring every integration. Point the gpt-realtime API session at a remote server, approve the tools, and you are live.
Do not start with twenty tools. Start with two that unlock real value. Eligibility checks. A knowledge lookup. A safe write action behind a confirmation. Expand once the logs show real demand.
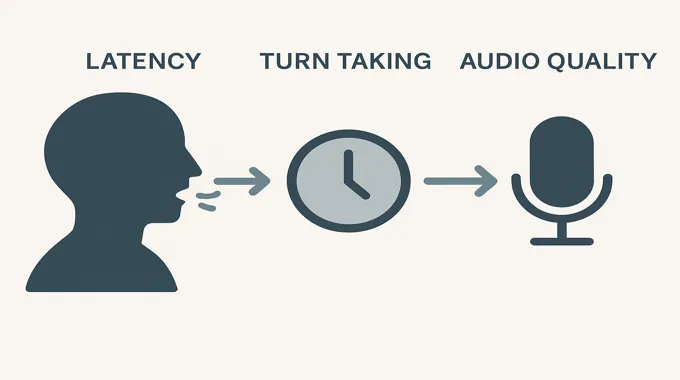
8. Latency, Turn Taking, And Audio Quality
People forgive the occasional hiccup. They do not forgive sluggishness. The gpt-realtime API gives you three high-leverage controls.
- WebRTC in the browser. This is the fastest loop for mic in and audio out. Use it when the user is present and wants to talk.
- Semantic VAD. Configure turn detection to stop interrupting people. Use a medium eagerness to start, then tune it for your audience. Sales teams often prefer slightly quicker interjections. Support lines prefer patience.
- Audio formats. G.711 for phone, PCM for web, Opus if you want better compression at high quality. Log what you ship so you can compare apples to apples.
A small change here does more for perceived intelligence than any total rewrite. You are sculpting the rhythm of the conversation. That matters.
9. Cost That You Can Explain To Finance
You can build a great experience without burning a hole in the budget. The phrase to search for is OpenAI Realtime API pricing. Set up a budget cap before you invite the whole company. Then apply a few practical habits.
- Keep sessions short. Idle minutes are invisible expenses.
- Cache reusable prompts and context. Cached input costs less than fresh tokens.
- Ship text only while you iterate. Switch to voice when the copy feels tight.
- Downshift sample rates for telephony. It reduces cost and fits the medium.
- Preflight tool calls. Avoid long back-and-forth when a single call would do.
Write your cost policy in the same repo as the code. New teammates will follow the rules you document.
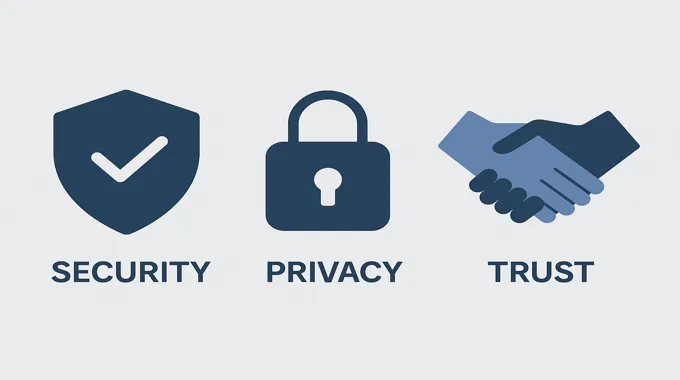
10. Security, Privacy, And The Social Contract
You are building an agent that sounds like a person. Treat that as a responsibility.
- Never expose long-lived API keys in the browser. Use short-lived client secrets only.
- Make it clear that users are talking to an AI. Do not simulate a real person by name.
- Log with purpose. Keep transcripts for debugging and training, but strip identifiers when you can.
- Set a privacy floor. If you store audio, say so. If you do not, say that too.
- Respect escalation. If a user asks for a human, connect one. Do not argue.
Check the OpenAI Realtime API documentation for the controls your industry needs, including data residency. Keep those settings explicit in code.
11. Your First Production Ready Flow
Here is a proven path to go from hello world to something your team can rely on.
- Playground to first demo. Use the gpt-realtime API model, test voices, attach an image, and export code.
- Minimal web app. Drop the OpenAI Agents SDK example into a page behind login. Mint short-lived client secrets on a tiny server endpoint.
- Prompt hardening. Add the bullets that define tone, language, variety, and escalation. Remove ambiguities.
- Two tools only. One read tool for a lookup. One write tool behind confirmation. Add a single preamble line before tool calls.
- Latency passes. Tune VAD and audio formats. Measure end-to-end time from user speech end to first audio byte out.
- Pricing pass. Review OpenAI Realtime API pricing with your finance partner. Set a budget cap. Add cached input where it helps.
- Ship, then expand. Add SIP calling if your users live on phones. Add MCP once you know the tools that matter. Keep a change log users can read.
This is a thoughtful way to build a voice agent that respects users and scales with your roadmap.
12. Closing, Build Something People Will Talk To Twice
The first time someone talks to your product, they are judging the personality, not the stack. The gpt-realtime API gives you the technical foundation to sound human, to reason, to act, and to do it fast. The OpenAI Agents SDK lets you move from a prototype to a real system without a hallway of glue code.
So pick a tiny, meaningful problem. Build a voice agent that solves it with grace. Share a quick gpt-realtime tutorial with your team. Link to the OpenAI Realtime API documentation in your repo. Add one tool that makes a real decision easier. Then invite users to try it and tell you where it falls short.
If you want help, start by opening the Playground, selecting the gpt-realtime API model, and pressing Connect. Ten minutes later you will have a conversation worth shipping. Then you can add your own twist, publish your demo, and keep going.
What is the difference between the gpt-realtime API and the standard ChatGPT API?
The gpt-realtime API is built for live, low-latency, multimodal conversations, including speech in and speech out. It runs natively on audio, supports image input, and can connect over WebRTC in the browser or WebSocket on servers. It also adds production features like SIP phone calling and MCP tool access. The standard ChatGPT style APIs are text first and do not provide the same real-time audio pipeline. If you want to build a voice agent, gpt-realtime API is the purpose-built path
Is the gpt-realtime API free to use?
No, usage is billed. Playground sessions count the same as normal API calls. Some accounts can enable complimentary daily tokens by opting in to data sharing in organization settings, eligibility varies by tier and the offer can change. Check your dashboard to confirm enrollment before testing.
How much does the gpt-realtime API cost?
Pricing is per token, with different rates for text, audio, and image tokens. For audio, gpt-realtime is listed at about 32 dollars per 1M input audio tokens, 64 dollars per 1M output audio tokens, and 0.40 dollars per 1M cached input tokens. Text and image token rates for gpt-realtime are also published on the pricing page, so review that table to estimate your specific mix.
What is the OpenAI Agents SDK and why is it recommended for voice agents?
The OpenAI Agents SDK is a lightweight toolkit that wires your agent’s instructions, tools, and state to OpenAI models with minimal glue code. For a browser voice agent, it pairs cleanly with the gpt-realtime API over WebRTC, which keeps latency low and makes microphone and audio output straightforward. You get a fast path from a Playground experiment to a working web app without building a custom signaling stack.
What do I need to get started with this tutorial?
You need an OpenAI API account with an API key, a modern browser with a microphone, and access to the Playground to try the model without code. If you export code, plan on a recent Node.js environment and HTTPS for local testing, the Agents SDK handles the WebRTC session and audio plumbing for you. Review the Realtime and Agents SDK docs for exact setup steps and any rate limits.