

See our Claude Guide for complete coverage
Introduction
Most model launches sound like a gym ad. “Stronger.” “Faster.” “More capable.” Cool. Show me the part where it stops breaking my repo.
Claude Sonnet 4.6 is interesting for a more boring reason, it raises the floor. For a lot of builders, the default model quietly determines your velocity, your token bill, and how often you mutter, “Why did you do that.” With Claude Sonnet 4.6, that muttering drops, not because it’s magic, but because it behaves more like a careful coworker.
I like to judge models with a single question: after ten minutes of back-and-forth, am I debugging my code, or am I debugging the model. The best upgrades move you back to the first category.
This is a hands-on read for people who ship. We’ll cover what changed, the benchmark rows that map to work, what the pricing implies in production, and when you should pay for something bigger.
Table of Contents
1. Claude Sonnet 4.6 Review: The Verdict In 60 Seconds (For Builders)
Here’s the short version.
Claude Sonnet 4.6 feels like “near-Opus” in the places you notice day to day: it reads more context before editing, follows instructions with less improvisation, and it’s less addicted to overengineering. The biggest win is not a single headline score, it’s fewer dead ends in long sessions.
Who should start here:
- Most builders who want a fast default that still ships quality
- Agent builders who care about tool use, retries, and computer workflows
- Teams doing lots of medium tasks, tickets, docs, light refactors, analysis
Who should escalate sooner:
- Deep refactor work, multi-module rewrites, and anything where “almost right” is expensive
- High-stakes automation, where one wrong click is a real incident
Below is the eight-row scoreboard I’d use to sanity-check a switch.
Values reproduced exactly as provided, including “self-reported” notes and tool/no-tool splits.
| Benchmark Category | Sonnet 4.6 | Sonnet 4.5 | Opus 4.6 | Opus 4.5 | Gemini 3 Pro | GPT-5.2 |
|---|---|---|---|---|---|---|
| Agentic terminal coding Terminal-Bench 2.0 | 59.1% | 51.0% | 65.4% | 59.8% | 56.2% (54.2% self-reported) | 64.7% (64.0% self-reported) (Codex CLI) |
| Agentic coding SWE-bench Verified | 79.6% | 77.2% | 80.8% | 80.9% | 78.0% (Flash) | 80.0% |
| Agentic computer use OSWorld-Verified | 72.5% | 61.4% | 72.7% | 66.3% | — | 38.2% |
| Agentic tool use τ2-bench | Retail: 91.7% Telecom: 97.9% | Retail: 86.2% Telecom: 98.0% | Retail: 91.9% Telecom: 99.3% | Retail: 88.9% Telecom: 98.2% | Retail: 85.3% Telecom: 98.0% | Retail: 82.0% Telecom: 98.7% |
| Scaled tool use MCP-Atlas | 61.3% | 43.8% | 59.5% | 62.3% | 54.1% | 60.6% |
| Agentic search BrowseComp | 74.7% | 43.9% | 84.0% | 67.8% | 59.2% (Deep Research) | 77.9% (Pro) |
| Multidisciplinary reasoning Humanity’s Last Exam (HLE) | No tools: 33.2% With tools: 49.0% | No tools: 17.7% With tools: 33.6% | No tools: 40.0% With tools: 53.0% | No tools: 30.8% With tools: 43.4% | No tools: 37.5% With tools: 45.8% | No tools: 36.6% (Pro) With tools: 50.0% (Pro) |
| Agentic financial analysis Finance Agent v1.1 | 63.3% | 54.5% | 60.1% | 58.8% | 55.2% | 59.0% |
| Office tasks GDPval-AA Elo | 1633 | 1276 | 1606 | 1416 | 1201 | 1462 |
| Novel problem-solving ARC-AGI-2 | 58.3% | 13.6% | 68.8% | 37.6% | 31.1% | 54.2% (Pro) |
| Graduate-level reasoning GPQA Diamond | 89.9% | 83.4% | 91.3% | 87.0% | 91.9% | 93.2% (Pro) |
| Visual reasoning MMMU-Pro | No tools: 74.5% With tools: 75.6% | No tools: 63.4% With tools: 68.9% | No tools: 73.9% With tools: 77.3% | No tools: 70.6% With tools: 73.9% | No tools: 81.0% With tools: — | No tools: 79.5% With tools: 80.4% |
| Multilingual Q&A MMMLU | 89.3% | 89.5% | 91.1% | 90.8% | 91.8% | 89.6% |
2. What Actually Changed In Sonnet 4.6 (Not Marketing)

Raw intelligence is nice. Workflow reliability pays rent.
The biggest practical change is that the model wastes fewer moves. It’s more likely to read, then edit, then verify, instead of editing first and negotiating with reality later. That shows up as fewer “done” messages followed by broken tests, and fewer confident claims of success when nothing actually ran.
Anthropic’s own product testing framed it in human terms: users preferred the new model in Claude Code sessions by a wide margin, and even picked it over an older Opus generation more often than you’d expect. That preference story matters because it’s about feel, not just score, the thing you notice at 2 a.m. when the build is red.
This is where Claude Sonnet 4.6 earns the “default” label. Default doesn’t mean best at everything. It means best at getting out of your way and staying out of your way.
3. Sonnet 4.6 Benchmarks: The Eight Rows That Matter Most
Benchmarks are imperfect, but they’re still useful if you read them like signals. If you only have time to run one internal eval, run it on Claude Sonnet 4.6 plus your current default, then compare transcripts, not just scores.
- SWE-bench Verified predicts “can it patch a real repo without collateral damage.”
- Terminal-Bench 2.0 predicts terminal competence and debugging stamina.
- OSWorld-Verified predicts whether computer use is usable, not just demo-able.
- τ2-bench predicts policy-following under structured tool flows.
- MCP-Atlas predicts multi-step tool use plus recovery when tools fail.
- BrowseComp predicts agentic search, staying on task, filtering noise.
- ARC-AGI-2 predicts novelty handling when there’s no obvious pattern to copy.
- GDPval-AA Elo aims at real office work value, not trivia.
If your product lives in one of these buckets, you should run your own eval that mirrors it. The scoreboard is the start, not the decision.
4. Coding Performance: SWE-bench Verified, Terminal-Bench 2.0, And The Real Dev Gap
The “benchmaxxing vs real PRs” argument never ends because both camps are reacting to real pain. Leaderboards can be gamed. Real-world codebases are messy, and your repo is not a benchmark harness. Still, SWE-bench Verified is the closest public proxy we have for “will it make a correct change inside a real project.”
At 79.6% on SWE-bench Verified, Sonnet is in the same neighborhood as the top models. The differentiator becomes everything that isn’t captured by a single number: does it change fewer files, does it keep style consistent, does it stop when it’s uncertain, does it check the tests it claims to check.
Terminal-Bench 2.0 is the other half of “real dev.” A model that can use git, run tests, and interpret error output is more valuable than one that writes pretty code in a vacuum. Sonnet’s 59.1% suggests strong ability with predictable gaps when the environment is weird or the task is under-specified.
The part that surprised me most is how often Claude Sonnet 4.6 chooses the boring solution. In software, boring is a compliment. It means fewer new abstractions, fewer magical helpers, and more respect for whatever battle scars your codebase already has. If you’re comparing options, our best LLM for coding 2025 guide covers the broader landscape.
5. Computer Use Jump: OSWorld-Verified And Why This Is The Real Story
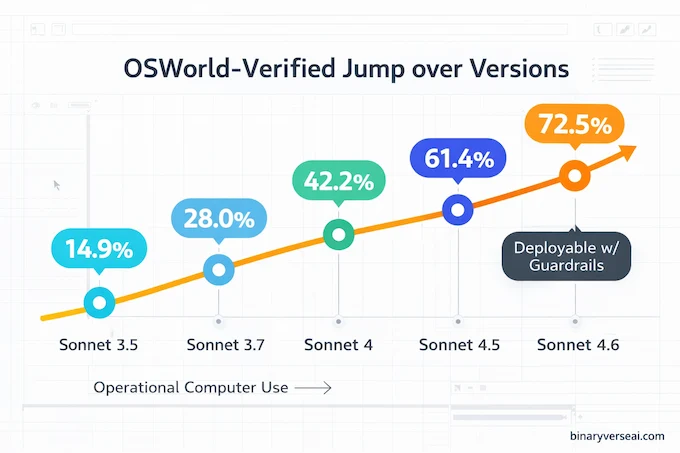
Computer use is the quiet revolution. APIs are clean. GUIs are where the real legacy work lives.* OSWorld-Verified forces models to click and type through real apps in a simulated desktop. It’s a harsh test because it punishes hallucinated UI actions and sloppy navigation. Anthropic also distinguishes older OSWorld scores from OSWorld-Verified, which upgrades task quality and evaluation.
A 72.5% score is the kind of number that changes what’s practical. Claude Sonnet 4.6 is the first Sonnet tier where computer use starts to feel operational, not experimental. You can start building agentic workflows that handle “there is no API” workflows, spreadsheets, internal portals, and multi-tab web forms, without bespoke connectors for everything. It won’t be perfect, but it crosses the line from “demo” to “deploy with guardrails.”
The trend line is the real headline:
| Model Version | Release Date | OSWorld Score (%) |
|---|---|---|
| Sonnet 3.5 (new) | Oct 2024 | 14.9 |
| Sonnet 3.7 | Feb 2025 | 28.0 |
| Sonnet 4 | Jun 2025 | 42.2 |
| Sonnet 4.5 | Oct 2025 | 61.4 |
| Sonnet 4.6 | Feb 2026 | 72.5 |
One warning: computer use expands your attack surface. Treat browsing as hostile. Sandboxing, confirmations, and tool whitelists are not optional if you care about safety or cost.
6. Tool Use And Agent Loops: MCP-Atlas, τ2-bench, BrowseComp
Tool use is where models either become useful systems or expensive chaos. I look for three behaviors:
- It chooses the right tool without theatrics.
- It executes tool calls correctly, with minimal inventing.
- It recovers when tools fail, because tools always fail.
τ2-bench is high for many models, which mostly says “they can follow structured flows.” MCP-Atlas is more telling, it stresses scaled tool use with retries and synthesis. Sonnet’s jump to 61.3% reads like a usability upgrade, not a small bump.
This is also where jagged intelligence shows up. The model can be brilliant, then trip over an obvious step like forgetting to pass an argument or reusing stale state. The fix is not wishful thinking. The fix is workflow design: explicit tool schemas, tight budgets, and a harness that can retry cleanly without spiraling.
Put differently, Claude Sonnet 4.6 is strong at tool use, but your system still decides whether that strength turns into throughput or into expensive loops. When you wire tools with strict schemas and tight budgets, Claude Sonnet 4.6 pays you back. For a deeper look at how to structure these, see our AgentKit guide.
7. The 1M Context Window Beta: When It’s A Superpower Vs A Trap
The “claude sonnet 1m context window” story sounds like a flex because it is one. The trick is using it without turning your budget into confetti.
With Claude Sonnet 4.6, a 1M token context window (beta) can hold huge inputs: large repos, long contracts, or many papers in one shot. The win is not “everything fits,” the win is “it stops guessing because the evidence is right there.”
Long context works best when you treat it like a memory hierarchy. Keep the current task spec and constraints crisp. Keep the relevant files close. Summarize older discussion with structure, especially decisions, interfaces, invariants. If you let summaries drift, the model will faithfully follow the drift.
Two practical answers:
- How much is 1M context window? Most platforms price normally up to a standard tier, then apply higher long-context pricing beyond it. Plan for it. Cache stable context. Chunk generated files. Treat long context as a scalpel, not a dumping ground.
- How many lines of code is 1M context? Roughly 50,000 to 150,000 lines of typical source, depending on line length and language. Generated code, logs, and minified files shrink that fast.
If you’re using long context for agentic coding, add one more rule: ask for a repo map first. Make the model show its mental index before it edits. Our guide on Claude agent SDK and context engineering covers this in detail.
8. Claude Sonnet 4.6 Pricing: The Part That Decides Whether You Scale
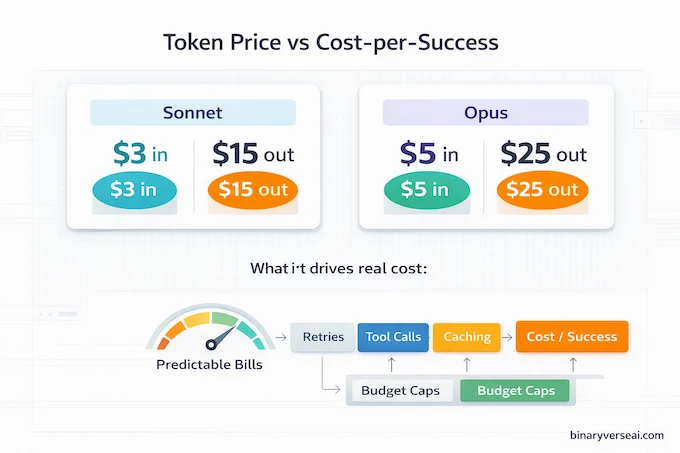
Benchmarks sell the dream. Pricing decides whether you can afford the loop. Headline numbers are straightforward: Sonnet stays at $3 per million input tokens and $15 per million output tokens, while Opus is $5 input and $25 output per million. For a full side-by-side, the LLM pricing comparison page has the latest numbers.
That means Claude Sonnet 4.6 pricing is basically a statement of intent: keep the default powerful, keep it affordable enough that people run more iterations, and let the flagship tier stay reserved for the hardest work.
The deeper truth is that production cost is dominated by retries and tool runs. A model that “almost works” but needs three attempts is not cheaper. It’s slower and more expensive. So the question is not “what’s the price per token,” it’s “what’s the cost per completed task.”
8.1 Claude Sonnet 4.6 API Pricing
If you’re looking for Claude Sonnet 4.6 API pricing, treat cost controls like engineering controls:
- Cache anything static
- Cap tool calls and retries
- Measure cost-per-success, not cost-per-token
- Use extended thinking only where it pays off
Do that and your bill becomes predictable. Skip it and your bill becomes an autobiography.
8.2 Sonnet 4.6 Vs Opus 4.6 Price
A clean rule:
- Pay for Opus when correctness is paramount or the change is wide and deep.
- Stay on Sonnet when you’re iterating, exploring, or running selection across multiple cheap attempts.
9. Claude Sonnet 4.6 Vs Opus 4.6: The Comparison People Actually Mean
Most “vs” debates are really about risk. Opus 4.6 buys deeper reasoning and more reliable long-horizon execution on the hard stuff: big refactors, multi-agent coordination, and problems where the right answer is fragile.
Sonnet buys speed and a cost point that makes experimentation normal. In other words, you can run more loops. More loops often wins, especially if you measure and select rather than trusting the first answer.
If you want a practical setup, make Sonnet your default and add an escalation policy. When tests fail twice, or when the plan starts drifting, bump to Opus. That turns model choice into system behavior, not a vibe.
9.1 Sonnet 4.6 Vs GPT-5.2
GPT-5.2 looks great on some classic “hard question” rows like GPQA Diamond, and it’s competitive on coding. Where Sonnet separates is agentic computer use, OSWorld-Verified is not close in the published comparisons, and that matters if your agent touches real software.
If you’re choosing between them, don’t argue online, run one harness: repo fix, terminal task, UI workflow, and a tool chain with an injected failure. The model that recovers cleanly is the one you want.
9.2 Sonnet 4.6 Vs Gemini 3 Pro
Gemini 3 Pro can be excellent for multimodal and search-heavy workflows depending on your stack. Direct comparison is messy because different reports use different variants. So treat it like an engineering decision, test your exact workflow, then decide what you’re buying: speed, search, coding, computer use, or a specific deployment constraint.
Also, the phrase “best ai coding model 2026” is mostly marketing. The real answer is “best model for your harness, latency, and budget.”
10. How To Use Sonnet 4.6: Claude App, Claude Code, API
A simple checklist:
- Define success in tests and acceptance criteria.
- Give only the tools needed for the job.
- Ask it to list what it inspected before it edits.
- Cap retries, log everything, measure cost-per-success.
- Keep a short migration note when moving from 4.5 to 4.6.
If you’re deploying across clouds, Sonnet is available in the usual places, including Bedrock and Vertex-style setups. That makes your infra choices less dramatic, which is exactly what you want from infrastructure. Our Claude Skills guide walks through practical API setups in more detail.
11. Limitations, Failure Modes, And Safety (Prompt Injection Included)
The classic failure modes are still here: overconfidence, long-horizon drift, and the occasional “I fixed it” with zero evidence.
Safety work matters most when you enable browsing and computer use. Prompt injection is real. Treat the web as untrusted input, because it is. The AI cybersecurity risks around agentic systems are worth reading before you deploy anything browser-facing.
Practical mitigations are boring and effective: sandbox tools, whitelist domains, require confirmations before destructive actions, and keep an audit trail. Anthropic’s system card also reports extensive safety evaluation and strong safety behavior for Sonnet-class releases.
12. Final Recommendation: Who Should Switch Today (And Who Shouldn’t)
Switch now if you’re building fast and you want a default model that behaves like a careful teammate: reads first, edits second, verifies more often. Escalate earlier if you’re doing deep refactors or high-stakes automation where one wrong move costs days.
My verdict is simple: run your own eight-row harness, measure pass rate plus cost-per-success, and pick the model that makes your workflow boring in the best way. If you found this useful, share it with a teammate, steal the harness idea, and then try Claude Sonnet 4.6 on one task you actually care about, not a demo prompt. For more AI model coverage, BinaryVerseAI keeps a running index of the latest reviews and benchmarks.
1) Is Claude Sonnet 4.6 free?
Yes. Claude Sonnet 4.6 is the default on Claude’s free tier, but “free” comes with usage limits. In practice that means caps on how much you can run per day, and some features vary by plan and availability.
2) What’s the latest version of Claude Sonnet?
Right now, the latest Sonnet is Claude Sonnet 4.6. To verify what you’re actually using, check the model picker in the Claude app, or confirm the exact model name in your API request settings.
3) Is Sonnet 4.6 available in Claude Code?
Yes. Sonnet 4.6 is available in Claude Code and is positioned as the default upgrade path from Sonnet 4.5. If results feel “off,” double-check the selected model, your thinking mode, and whether tools are enabled.
4) What is the size of the context window?
Sonnet 4.6 supports a large standard context window, and it also offers a 1M token context window in beta. The important caveats are access flags or headers, higher cost beyond certain thresholds, and the fact that structure matters as much as raw tokens.
5) How many lines of code is 1M context?
There’s no exact conversion because tokens are not characters, and characters are not lines. A practical rule of thumb is: 1M tokens can cover multiple mid-size repos or a very large monorepo slice, but you still want summarization or compaction to keep the model focused.