

Introduction
Benchmarks are the new horoscope. Everyone has a favorite chart, everyone has a spicy take, and nobody reads the footnotes until their preferred model loses.
So let’s do this properly. Claude Opus 4.6 Benchmarks are genuinely interesting, not because they “prove” intelligence, but because they hint at something more practical: how well a model behaves when you hand it messy tools, long tasks, and real-world constraints. That’s where most models start to wobble.
This post is a clean, time-respecting walkthrough of the Claude Opus 4.6 Benchmarks, including the big jumps, the flat lines people keep arguing about, and the quiet metrics that actually pay your rent.
Table of Contents
1. Claude Opus 4.6 Benchmarks: The 60-Second Verdict

Here’s the fast read on the Claude Opus 4.6 Benchmarks:
- Biggest flex: Terminal-Bench 2.0 jumps to 65.4%, which is a real “agentic coding” style eval, not a toy prompt test.
- Most debated: SWE-bench Verified looks basically flat at 80.8%, with a “best-run” variant around 81.4% after a prompt tweak.
- Most memeable jump: ARC-AGI-2 spikes to 68.8% in the official table, and people immediately started calling it a “holy jump.”
- Most monetizable story: GDPval-AA lands at Elo 1606, framed as a strong edge in knowledge work.
And now the table everyone screenshots without reading.
1.1 Official Benchmarks Table
Claude Opus 4.6 Benchmarks Table
| Benchmark Category | Metric / Dataset | Opus 4.6 | Opus 4.5 | Sonnet 4.5 | Gemini 3 Pro | GPT-5.2 (All Models) |
|---|---|---|---|---|---|---|
| Agentic terminal coding | Terminal-Bench 2.0 | 65.4% | 59.8% | 51.0% | 56.2% (54.2% self-reported) | 64.7% (64% self-reported Codex CLI) |
| Agentic coding | SWE-bench Verified | 80.8% | 80.9% | 77.2% | 76.2% | 80.0% |
| Agentic computer use | OSWorld | 72.7% | 66.3% | 61.4% | — | — |
| Agentic tool use | τ²-bench (Retail) | 91.9% | 88.9% | 86.2% | 85.3% | 82.0% |
| Agentic tool use | τ²-bench (Telecom) | 99.3% | 98.2% | 98.0% | 98.0% | 98.7% |
| Scaled tool use | MCP Atlas | 59.5% | 62.3% | 43.8% | 54.1% | 60.6% |
| Agentic search | BrowseComp | 84.0% | 67.8% | 43.9% | 59.2% (Deep Research) | 77.9% (Pro) |
| Multidisciplinary reasoning | Humanity’s Last Exam (No Tools) | 40.0% | 30.8% | 17.7% | 37.5% | 36.6% (Pro) |
| Multidisciplinary reasoning | Humanity’s Last Exam (With Tools) | 53.1% | 43.4% | 33.6% | 45.8% | 50.0% (Pro) |
| Agentic financial analysis | Finance Agent | 60.7% | 55.9% | 54.2% | 44.1% | 56.6% (5.1) |
| Office tasks | GDPVal-AA Elo | 1606 | 1416 | 1277 | 1195 | 1462 |
| Novel problem-solving | ARC AGI 2 | 68.8% | 37.6% | 13.6% | 45.1% (Deep Thinking) | 54.2% (Pro) |
| Graduate-level reasoning | GPQA Diamond | 91.3% | 87.0% | 83.4% | 91.9% | 93.2% (Pro) |
| Visual reasoning | MMMU Pro (No Tools) | 73.9% | 70.6% | 63.4% | 81.0% | 79.5% |
| Visual reasoning | MMMU Pro (With Tools) | 77.3% | 73.9% | 68.9% | — | 80.4% |
| Multilingual Q&A | MMMLU | 91.1% | 90.8% | 89.5% | 91.8% | 89.6% |
2. What Changed In Opus 4.6 That Can Actually Move Benchmark Outcomes
Benchmarks don’t move because someone sprinkled “be smart” dust. They move because scaffolding changed. Claude Opus 4.6 Benchmarks are tightly tied to three practical upgrades:
- Effort control: low, medium, high, max. That knob changes depth, latency, and cost.
- Adaptive thinking: the model chooses when to think harder instead of thinking hard all the time.
- Context compaction: the model summarizes older context so it can keep working longer without face-planting into limits. That is central to agentic search setups.
Add the headline features (1M token context in beta, 128k output tokens) and you get the theme: longer tasks, more tools, fewer “I forgot what we were doing” moments.
3. How To Read These Numbers Without Getting Fooled
The trick is simple: ask what the model was allowed to do.
3.1 Official Vs Reproduced Vs Self-Reported
Some rows mix three worlds:
- Official runs on one lab’s infrastructure
- Reproduced runs using a shared harness
- Self-reported numbers from competitors with different tooling assumptions
Terminal-Bench is a great example. The system card spells out repeated trials and a standardized harness, not a single lucky run.
3.2 Tools Vs No Tools Is Not A Footnote
“Tool use” isn’t a minor detail. It changes the task. A model with web search, web fetch, code execution, and compaction is basically a different creature than a model locked in a text box.
If you’ve ever watched two developers race, one with internet access and one without, you already understand the gap.
4. Official Claims: What The Table Is Really Saying
The Claude Opus 4.6 Benchmarks table is making a specific argument: “This model is built for long-running agents.” You can see that story in the clustering:
- Agentic terminal coding: Terminal-Bench 2.0
- Agentic search: BrowseComp
- Knowledge work: GDPval-AA
- Tool-heavy tasks: τ²-bench, MCP Atlas
- Computer use: OSWorld
Also notice the subtle honesty baked into the footnotes: most results are averaged across multiple trials, effort settings matter, and context window sizes vary by eval but cap at 1M.
That doesn’t make the table “true,” but it does make it less of a vibes-based screenshot.
5. Terminal-Bench 2.0: Why This One Is Becoming The New Flex

If you only remember one number from the Claude Opus 4.6 Benchmarks, make it this one. Terminal-Bench 2.0 is hard in the way real work is hard: stateful, messy, and full of opportunities to waste time. The system card reports 65.4% at max effort, averaged across repeated trials.
The important part is not just the score, it’s the setup: 89 tasks, run 15 times each, spread across batches to reduce variance.
That’s why “opus 4.6 terminal-bench 2.0 score (official highlights 65.4%)” is starting to replace the usual cherry-picked coding demos. It smells more like an engineer wrote it.
6. SWE-Bench Verified: The Flat Line Everyone Noticed
This is the section where the comment threads get loud. The official line: SWE-bench Verified sits at 80.8%. The deeper detail: results are averaged over 25 trials, and a specific prompt modification yielded 81.4%.
That’s the whole “opus 4.6 swe-bench verified 80.8 81.42 (the “why no improvement?” controversy)” in one sentence. And yes, the internet will argue about whether 0.6 points matters.
Here’s the grounded take: SWE-bench rewards a particular flavor of patch-making. If the model got better at planning, reviewing, and avoiding dumb mistakes, it might show up more in agentic workflows than in a narrow patch benchmark. That’s also why people search “claude opus 4.6 benchmarks review” after they try it on a real repo and feel something changed, even if the chart barely moves.
7. ARC-AGI-2: The Shock Jump And The Wrong Conclusions
ARC-AGI-2 is the one that made people sit up. A jump to 68.8% is not a gentle improvement. It’s a headline. But the correct reaction is not “we solved general intelligence.” The correct reaction is: this benchmark is sensitive to reasoning style and to how you allocate compute.
So yes, “opus 4.6 arc agi 2 68.8 (the “holy jump” everyone cites)” is real as a score. What it means depends on whether your day job looks like ARC problems. For most people, it doesn’t.
Still, it’s a useful signal: the model got better at certain kinds of abstract structure finding, not just regurgitating patterns.
8. Humanity’s Last Exam: Tools Turn It Into A Different Sport
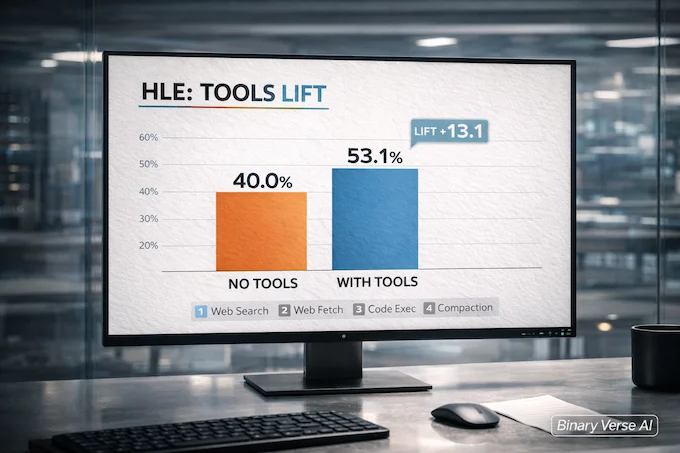
Humanity’s Last Exam is the cleanest “tools matter” demonstration in the whole set of Claude Opus 4.6 Benchmarks.
Anthropic describes two configurations: reasoning-only, and a tool-augmented setup with web search, web fetch, programmatic tool calling, code execution, plus context compaction that triggers every 50k tokens.
8.1 Humanity’s Last Exam Table
Claude Opus 4.6 Benchmarks: Tools vs No Tools
| Model | Without Tools | With Tools |
|---|---|---|
| Opus 4.6 | 40.0% | 53.1% |
| Opus 4.5 | 30.8% | 43.4% |
| Sonnet 4.5 | 17.7% | 33.6% |
| Gemini 3 Pro | 37.5% | 45.8% |
| Gemini Deep Research | 46.4% | N/A |
| GPT-5.2 | 34.5% | 45.5% |
| GPT-5.2 Pro | 36.6% | 50.0% |
The model that wins “no tools” isn’t automatically the best agent. The best agent is the one that can search, verify, compute, and not lose the plot mid-run.
That’s also why “opus 4.6 humanity’s last exam score (HLE)” gets cited so much. It’s not a trivia contest. It’s a workflow test.
9. BrowseComp And Agentic Search: The Research Model Pitch
BrowseComp is described as an agent browsing eval, and the system card is unusually explicit about what powers the gains: larger effective context via compaction, plus programmatic tool calling.
Even better, they show scaling behavior and a multi-agent setup. With orchestrator plus subagents, Opus 4.6 hits 86.8% accuracy, edging the best single-agent configuration.
That’s the real headline behind the BrowseComp score: not “it browses,” but “it can coordinate, compress, and keep going.” If you do research for a living, that matters more than one more point on a math set.
10. GDPval-AA Elo 1606: The Quiet Metric With Real-World Gravity
GDPval-AA is built around economically valuable tasks and scored as an Elo rating derived from blind pairwise comparisons. Opus 4.6 is framed as leading GPT-5.2 by about 144 Elo, implying roughly a 70% pairwise win rate.
This is why “opus 4.6 gdpval-aa elo 1606 (independent-ish anchor via Artificial Analysis leaderboard)” keeps showing up in serious discussions. It’s closer to “can you produce good work artifacts” than “can you ace a puzzle.”
If you’re choosing a model for office tasks, client deliverables, or internal docs, GDPval-AA is the chart to stare at.
11. Independent Benchmarks: What To Trust, What To Treat As Vibes
The Claude Opus 4.6 Benchmarks conversation gets messy because “independent” often means “someone’s spreadsheet plus a Twitter thread.”
Still, independent tables are useful when they line up with official patterns and when they include multiple evals. Here’s the set you provided, which is a decent triangulation tool, not a holy text.
11.1 Independent Benchmarks Table
Claude Opus 4.6 Benchmarks: Model Leaderboard
| Rank | Model Name | GPQA | MMLU Pro | MMMU | AIME | ProofBench | SWE-bench | Terminal-Bench 2.0 | Vibe Code Bench | LiveCodeBench |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.6 (Thinking) | 89.65% | 89.11% | 83.87% | 95.63% | 50.00% | 79.20% | 58.43% | 36.12% | 84.68% |
| 2 | Claude Opus 4.5 (Thinking) | 85.86% | 87.26% | 82.95% | 95.42% | 36.00% | 74.20% | 53.93% | 20.63% | 83.67% |
| 3 | GPT 5.2 | 91.67% | 86.23% | 86.67% | 96.88% | 15.00% | 75.40% | 51.69% | 41.31% | 85.36% |
| 4 | Claude Opus 4.5 (Nonthinking) | 79.55% | 85.59% | 81.10% | N/A | N/A | 74.60% | 58.43% | N/A | N/A |
| 5 | GPT 5.1 | 86.62% | 86.38% | 83.18% | 93.33% | N/A | 67.20% | 44.94% | 24.61% | 86.49% |
| 6 | Claude Sonnet 4.5 (Thinking) | 81.63% | 87.36% | 79.31% | 88.19% | 19.00% | 69.80% | 41.57% | 22.62% | N/A |
| 7 | Kimi K2.5 | 84.09% | 85.91% | 84.34% | 95.63% | N/A | 68.60% | 40.45% | N/A | 83.87% |
| 8 | Gemini 3 Pro (11/25) | 91.67% | 90.10% | 87.51% | 96.68% | 20.00% | 71.60% | 55.06% | 14.30% | 86.41% |
| 9 | Gemini 3 Flash (12/25) | 87.88% | 88.59% | 87.63% | 95.63% | 15.00% | 76.20% | 51.69% | N/A | 85.59% |
| 10 | GPT 5 | 85.61% | 86.54% | 81.50% | 93.37% | 18.00% | 68.80% | 37.08% | 20.09% | 85.91% |
Two practical rules:
- Trust independent results most when they match the direction of the official story.
- Treat single-number rankings like “Vibe Code Bench” as what they are, a snapshot of a specific harness culture.
And yes, this is where “claude opus 4.6 benchmarks reddit” threads can help, not because Reddit is an authority, but because practitioners will tell you what broke in their workflow.
12. So… Should You Switch? A Decision Checklist By Job Type
Let’s end the Claude Opus 4.6 Benchmarks tour with the only question that matters: should you change anything on Monday?
12.1 If You Write Code For A Living
- Switch if you live in terminals, monorepos, and long sessions.
- Test with your own repo, your own CI, your own failure modes.
- Use Terminal-Bench style tasks as your mental model, not “write a quick function.”
12.2 If You Build Agents Or Internal Tools
- Prioritize tool use, compaction, and effort controls.
- Run a small OSWorld-like workflow test: browse, click, extract, transform, publish.
- Measure success as “did it finish” and “did it do something risky.”
12.3 If You Do Research Or Knowledge Work
- BrowseComp and HLE with tools are the relevant signals.
- Validate outputs like you would validate a junior analyst: sources, math, assumptions.
- GDPval-AA is your north star if you care about output quality, not just correctness.
12.4 If You Just Want A Smart Daily Driver
- Don’t overpay for marginal gains you won’t notice.
- Pick the model that’s reliable, fast enough, and fits your budget.
- Spend the saved time building a better prompt library.
If you want the real advantage, don’t worship the charts. Build a tiny evaluation harness that matches your job, run it weekly, and let your own numbers pick the winner. That’s how you turn Claude Opus 4.6 Benchmarks from internet drama into engineering signal.
CTA: If this saved you time, share it with the one friend who keeps posting leaderboard screenshots like they’re stock picks. Then run your own test suite, take notes, and publish what you find. The fastest way to get clarity is to stop arguing about benchmarks and start measuring your workflow.
1) What are the Claude Opus 4.6 benchmark scores that matter most for developers?
For most developers, the Claude Opus 4.6 Benchmarks that matter are Terminal-Bench 2.0 (agentic terminal work), SWE-bench Verified (real repo fixes), and BrowseComp (research + retrieval). If you ship knowledge-work outputs, GDPval-AA Elo is the practical tie-breaker.
2) Why did Opus 4.6 look flat on SWE-bench Verified (80.8 vs 81.42) and is it actually worse for coding?
The “flat” SWE-bench story is mostly about how the score is reported. The 80.8 is an averaged result across trials, while ~81.42 reflects a best-run with a prompt tweak. In practice, many teams feel improvements in longer sessions, code review, debugging, and multi-step agent workflows that SWE-bench does not fully capture.
3) How does Claude Opus 4.6 compare to Opus 4.5 on real-world agentic tasks (Terminal-Bench, BrowseComp, GDPval-AA)?
Across real-world agentic categories, Claude Opus 4.6 Benchmarks generally show clearer separation than classic “single-shot” tests. The largest practical gains show up in agentic terminal coding (Terminal-Bench), agentic search (BrowseComp), and knowledge-work style tasks (GDPval-AA Elo), which map better to day-to-day workflows than isolated puzzles.
4) What is Humanity’s Last Exam (HLE), and why is Opus 4.6’s score a big deal?
HLE is a multidisciplinary evaluation designed to stress broad reasoning. The key insight is the gap between no-tools vs with-tools, because real agents live and die by tool use. Opus 4.6’s HLE results matter because they suggest stronger “end-to-end” performance when the model can search, fetch, compute, and keep context coherent.
5) Does the 1M token context window change benchmark meaning, or do models still “rot” after ~200k tokens?
A bigger window changes what’s possible, but it doesn’t magically prevent drift. What helps in practice is a combination of long-context retrieval quality, context management, and mechanisms like compaction/summarization. The right takeaway is to test your own workload: long docs, long repos, long agent runs, and measure when quality starts slipping.