

Introduction
If you read this week’s AI headlines like a weather report, you’d call it “partly cloudy with a strong chance of agents.” But the pattern is cleaner than the noise. Models are getting smaller without getting dumb, assistants are getting hands and feet inside real workflows, and the grown-up world is pushing back with guardrails, audits, and a few very public faceplants.
This edition of AI News January 17 2026 is less about one magical model and more about a stack taking shape: efficient open models at the bottom, tool-using systems in the middle, and policy realities at the top. The result feels like the early internet again, chaotic, practical, and slightly scary.
Here’s the pulse behind the week’s AI updates this week:
- Efficiency wins: smaller models beating larger baselines, on real benchmarks.
- Agentic AI News: assistants stop chatting and start doing, inside folders, browsers, and labs.
- Friction returns: safety, bias, and health misinformation force product changes.
Now, AI News January 17 2026 in 18 fast, high-signal stories, with the “why it matters” baked in.
Table of Contents
1. TranslateGemma Open Models Shrink Translation Costs, Boost Quality Across 55 Languages

Google’s TranslateGemma takes a swing at a stubborn trade-off: translation quality usually rides on big, expensive models. This release flips that intuition by offering 4B, 12B, and 27B open models tuned for 55 languages, aiming for low-latency translation you can actually ship on phones, laptops, or a single decent GPU.
The spicy bit, the 12B model reportedly beats a 27B Gemma 3 baseline on WMT24++ via MetricX, which is the kind of result that makes infra teams smile. Under the hood, it’s a two-step distillation pipeline from Gemini, supervised fine-tuning plus reinforcement learning guided by translation quality metrics. For AI News January 17 2026, this is the clearest “small can be strong” signal.
2. MedGemma 1.5 Boosts Open Medical Imaging, MedASR Nails Dictation Accuracy
MedGemma 1.5 pushes open medical AI toward the messy reality of clinical data, not just neat textbook images. The 4B model is framed as a practical baseline for builders, while the bigger 27B variant stays around for heavier text work. The big upgrade is imaging breadth: CT, MRI, histopathology, and longitudinal chest X-rays, plus better anatomical localization and structured extraction.
Then there’s MedASR, a medical speech-to-text model tuned for clinical dictation. In plain terms, it’s built to stop turning doctor jargon into nonsense, and it reportedly outperforms Whisper large-v3 by a wide margin on medical WER benchmarks. The bigger theme is ecosystem pressure: open models, clinical workflows, and a Kaggle challenge meant to turn prototypes into tools people will actually use.
3. Claude Cowork Turns Claude Into A File-Working Teammate, Not Just Chat
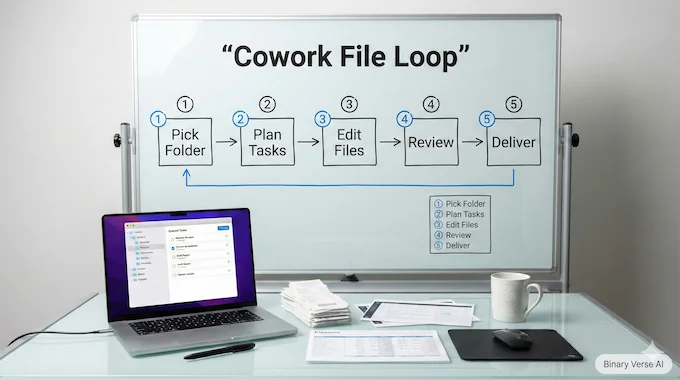
Anthropic’s Cowork is a simple idea that changes the vibe: stop treating the model like a conversational oracle, and start treating it like a colleague with access to your messy folder. In the macOS Claude app, Cowork can read, edit, and create files inside a user-chosen directory. That’s not a “chat feature,” that’s a workflow surface.
The practical wins are mundane on purpose: rename and organize downloads, turn screenshot piles into spreadsheets, draft reports from scattered notes. The interesting part is how it lowers the “context tax,” less copy-paste, less prompt archaeology. It also raises the stakes. Once an agent can touch local files, destructive actions and prompt-injection risks move from theoretical to Tuesday afternoon. This is agentic work, and it demands grown-up habits.
4. GLM-Image Reboots Text-In-Images With Open Autoregressive Hybrid Generation
GLM-Image is chasing a goal that diffusion models keep fumbling: follow instructions tightly, render readable text, and keep multi-object scenes coherent. Its approach is hybrid, an autoregressive planner for layout and semantics, plus a diffusion decoder for texture and realism. Think of it as “decide first, paint later,” which is how humans cheat too.
Technically, it pairs a 9B AR module with a 7B DiT-style diffusion decoder and leans on semantic-VQ tokens instead of weaker image codes. Post-training splits rewards: the AR part gets nudged on low-frequency goals like OCR correctness and semantic alignment, while the decoder gets tuned for detail fidelity. If it holds up, this becomes an open tool for knowledge-dense visuals, not just pretty pictures.
5. Universal Commerce Protocol Lets AI Agents Sell Directly Inside Google Surfaces
Google’s Universal Commerce Protocol (UCP) is what happens when search, assistants, and checkout finally stop pretending they’re separate products. UCP is pitched as an open standard so AI systems in Search and Gemini can move from “recommendation” to “transaction,” turning a conversation into a purchase without the usual cart gymnastics.
The merchant story is intentionally reassuring: merchants stay Merchant of Record, keep customer relationships, and plug into existing Merchant Center feeds instead of rebuilding everything. The technical subtext is trust plumbing, a clean transaction trail tying together merchants, credential providers, and payments. Today it’s about direct buy flows, tomorrow it’s carts, loyalty, and returns. This is where agentic UX meets money, which means the incentives get sharper and so will the fights.
6. DeepSeek Conditional Memory Breaks MoE Limits With O(1) Lookups For Reasoning

Mixture-of-Experts made “conditional compute” fashionable, but it still makes models re-derive the same facts through expensive layers. DeepSeek and Peking University argue for a second sparsity axis: Conditional Memory, where static, local knowledge is retrieved by cheap lookups instead of recomputed. Their design, Engram, modernizes N-gram-style memory into a scalable module fused into a Transformer.
The claim is not subtle: better performance at iso-parameter and iso-FLOPs across knowledge, reasoning, and code benchmarks. The fun part is the U-shaped scaling law they report for capacity allocation between experts and memory, suggesting there’s an optimal split where lookup and reasoning complement each other. If you care about long context, the “memory frees attention” story is the real hook, because it sounds like a path out of brute-force scaling.
7. Epiplexity Replaces Entropy To Measure Learnable Structure In Real-World Data
A CMU and NYU paper argues that Shannon-style information measures are too idealized for modern ML. In real training, learners are compute-bounded, and “information” that a perfect observer could decode may still look like noise to a realistic model. They propose Epiplexity, a compute- and observer-dependent measure meant to capture learnable structure while discounting time-bounded entropy.
The paper frames three paradoxes: deterministic systems generating new capability, ordering effects in training that shouldn’t matter in classic theory, and emergent structure that learners exploit more efficiently than brute simulation. Then it gets practical, tying Epiplexity to estimators based on loss curves and cumulative KL between teacher and student. This is a data theory pitch, not a model theory pitch: pick and shape datasets for learnable structure, and performance follows.
8. Synergistic Core Emerges In LLM Middle Layers, Shaping Behavior And Learning
Another arXiv paper makes a bold neuroscience-flavored claim: LLMs develop a “Synergistic Core” in the middle layers, where integrated information becomes more than the sum of parts. Using Partial Information Decomposition and ΦID, the authors map redundancy versus synergy across layers. Early and late layers look redundant, like stable sensory and motor zones, while the middle becomes synergy-heavy, where signals combine into features you can’t reduce to one head or expert.
The more compelling bit is causal testing. Ablating high-synergy components reportedly causes outsized behavioral shifts compared to removing similarly sized redundant components. They also report reinforcement learning targets synergy more effectively than supervised fine-tuning, which hints at a training lever: update where integration lives. If this holds across models, it gives interpretability a sharper map, and gives compression a new rule, keep the synergy, prune the fluff.
9. GPT-5.2 Powers Week-Long Autonomous Coding, Building A Browser From Scratch
Cursor engineers claim a week-long autonomy milestone: a browser built largely by an agent loop powered by GPT-5.2. The output is absurd in scale, over a million lines across thousands of files, including a Rust rendering engine, HTML/CSS layout, painting, and even a custom JavaScript VM. It’s not Chromium, but it’s real enough to render simple sites and that’s the point.
The deeper lesson is organizational, not mystical. Single-agent autonomy was too slow, and flat multi-agent coordination collapsed into ownership problems and coordination bottlenecks. A planner–worker setup worked: planners spawn tasks, workers execute narrowly, a judge decides whether to iterate. In AI News January 17 2026, this is the clearest OpenAI news-adjacent signal that “agent swarms” are becoming an engineering pattern, not a demo trick.
10. Personal Intelligence Turns Gemini Into A Context-Aware Assistant Across Google Apps
Google’s “Personal Intelligence” is an attempt to kill the most annoying part of assistants: re-explaining your own life. In beta for U.S. users, Gemini can connect across Gmail, Photos, YouTube, and Search to answer questions with real context, like pulling a license plate from a photo or combining purchase details from email with preferences inferred from past trips.
The product pitch leans on control. It’s off by default, you choose which apps connect, and temporary chats avoid personalization. Google also says it doesn’t train directly on raw inbox or photo contents, instead using connected data to answer and relying on limited interaction data for improvements. This is the assistant race moving from “better text” to “better memory,” and it will live or die on trust. Google DeepMind news often feels abstract, this one is uncomfortably personal.
11. Claude For Healthcare Adds HIPAA-Ready Connectors To Cut Clinical Busywork
Anthropic is pushing Claude into regulated healthcare with a connectors-and-skills approach instead of “trust us, it’s smart.” Claude for Healthcare adds HIPAA-ready integrations to sources like the CMS Coverage Database, ICD-10, and the NPI Registry, aimed at practical workflow tools: coverage checks, prior authorizations, appeals, credentialing, and claims validation.
The point is not replacing clinicians. It’s compressing paperwork loops where humans spend hours assembling evidence across systems. Anthropic also frames “Agent Skills” as reusable workflow tools, including FHIR development and prior auth review templates that cross-reference coverage requirements, guidelines, and patient records. On the consumer side, they’re testing opt-in health data connections via third parties, with Apple Health and Android Health Connect integrations rolling out. This is enterprise AI wearing a compliance badge, which is exactly what the market demanded.
12. Claude For Life Sciences Turns Months Of Lab Work Into Minutes
Anthropic’s life sciences story is about leverage, not writing papers. They highlight how Claude, especially Opus 4.5, is being wired into toolchains so it can decide what to run, execute multi-step analysis, and surface patterns in huge biomedical datasets. The AI for Science program adds fuel with free API credits for selected researchers, basically subsidizing ambitious builds.
The showpiece is Stanford’s Biomni, described as a biomedical agent that routes Claude across hundreds of tools and databases. Anthropic claims a GWAS pipeline that can take months ran in about 20 minutes end-to-end. Other labs are building narrower agents for CRISPR imaging interpretation, literature-driven gene clustering, and hypothesis generation. The real headline is workflow compression, turning scientific process into an executable graph where models become operators, not commentators.
13. Grok Bikini Image Restrictions Tighten, X Adds Paywall And Geoblocks
X rolled out stricter safety controls for Grok image generation after abuse concerns, focusing on edits of real people into revealing clothing like bikinis. The change is blunt: block those edits globally through the Grok account, even for paid users, and move image generation and editing behind a paywall. The logic is accountability, fewer anonymous drive-bys, more traceability.
They also added regional enforcement: geoblock bikini and underwear generation for real people in jurisdictions where it’s illegal, and extend similar geoblocks to the standalone Grok app. It’s framed as “zero tolerance” around CSAM and non-consensual sexual content, with escalation to law enforcement for high-priority cases. In AI News January 17 2026, this is AI regulation news wearing a product SKU. Safety is becoming a feature gate, not a policy PDF.
14. Caste Bias In AI Exposed, New Benchmarks Reveal Stubborn Hierarchy Loops
New research is measuring caste bias in language models with a level of specificity that makes hand-waving impossible. Benchmarks like IndiCASA and DECASTE probe how models complete stereotypes, assign occupations, and allocate roles across caste-linked personas. The results reportedly show consistent patterns: dominant groups overrepresented, marginalized communities sidelined, and stereotyped associations reinforced through seemingly harmless completions.
The uncomfortable part is that this bias often comes from “normal” training pipelines. Minority perspectives are less visible in mainstream corpora, more likely to be in local languages, and more likely to be filtered out by quality heuristics that reward standardized grammar and elite publication sources. The practical risk is downstream automation, lending, hiring, and education tools inheriting this structure. Measurement is step one, and it’s already damning.
15. Google AI Overviews Health Errors Spark Removals After Liver Test Scare
Google pulled some AI Overviews for health queries after reporting showed the summaries could present misleading medical information, especially around interpreting liver blood tests. The issue was not just wrong numbers, it was context collapse. “Normal ranges” vary with age, sex, and other factors, and collapsing that into a confident snippet at the top of Search can mislead people into delaying care.
Google says Overviews only show when confidence is high and that a clinical team reviewed examples, but the removals signal a different truth: health answers are brittle, and public trust is easy to burn. In AI News January 17 2026, this is the cleanest reminder that product UX amplifies risk. A bad answer in a chat is annoying. A bad answer at the top of Search feels authoritative, and that changes everything.
16. Tesla Optimus V3 Hype Leaks At CES, Musk Says ‘Probably True’
Tesla Optimus V3 rumors got a boost from a familiar source type: an excited visitor with a microphone. Jason Calacanis claimed he saw Optimus V3 inside Tesla’s lab and left convinced it could become Tesla’s defining product, even eclipsing its car identity. The comments were big, 1:1 robot-to-human ratios over time, billion-unit scale, and a future where modern AI makes robots competent enough for tasks humans avoid.
Tesla itself has been careful, Optimus V3 has not been officially unveiled, and leaked photos are likely earlier versions. Still, Musk replied “Probably true” to the viral framing, which is basically rocket fuel for speculation. Treat this as hype until you see repeatable demos, but keep the strategic point: robotics is the next compute-hungry frontier, and the talent race is already on.
17. NVIDIA And Lilly Launch AI Drug Discovery Lab, Billion-Dollar Bet
NVIDIA and Eli Lilly announced a joint AI drug discovery lab with up to $1 billion planned investment over five years, aimed at turning parts of drug development from craft into engineering. The thesis is simple: biology is too complex for human intuition alone, and the loop of simulation, hypothesis generation, wet-lab validation, and model updating can be tightened with serious AI drug discovery and serious talent.
The lab is framed as “scientist-in-the-loop,” meaning agents and models support researchers instead of replacing them. It also builds on Lilly’s planned AI supercomputer infrastructure, described around NVIDIA DGX systems, targeting large-scale biomedical foundation models. Jensen Huang’s positioning is clear, biopharma is one of the most worthy targets for accelerated computing. This is less a press release and more an ecosystem bet that compute-native biology becomes a dominant industry.
18. Dr. Zero Data-Free Search Agents Self-Train, Beat Supervised Baselines
Meta Superintelligence Labs and UIUC researchers introduced Dr. Zero, a data-free framework for improving multi-turn search agents without human-written training questions. The system uses a self-evolution loop: a proposer generates questions, a solver learns to answer them using an external search tool, and as the solver improves, it pressures the proposer to generate harder but still verifiable tasks. It’s automated curriculum learning with search as the ground truth.
To keep training practical, they add hop-grouped relative policy optimization, a compute-saving technique that reduces sampling overhead while preserving learning signal. The headline claim is sharp: match or beat supervised search agents, with reported gains on complex QA benchmarks. For AI News January 17 2026, this is a big flag in the “New AI papers arXiv” pile, agents that teach themselves by browsing the world.
Closing:
The pattern across these top AI news stories is not subtle anymore. We’re watching a stack solidify: new AI model releases get cheaper and sharper, open source AI projects turn into real tooling, and agentic systems start touching files, money, and medicine. That forces the next wave, audits, guardrails, and accountability, whether companies like it or not.
If you publish, ship, or invest in this space, don’t just chase the hottest demo. Track what’s becoming infrastructure. That’s where the compounding happens. If you want next week’s AI world updates with the same high-signal filter, tell me which lane you care about most, open models, agents, or AI regulation news, and I’ll tailor the next roundup around it.
- https://blog.google/innovation-and-ai/technology/developers-tools/translategemma/
- https://research.google/blog/next-generation-medical-image-interpretation-with-medgemma-15-and-medical-speech-to-text-with-medasr/
- https://claude.com/blog/cowork-research-preview
- https://z.ai/blog/glm-image
- https://developers.google.com/merchant/ucp
- https://arxiv.org/abs/2601.07372
- https://arxiv.org/abs/2601.03220
- https://arxiv.org/abs/2601.06851
- https://cursor.com/blog/scaling-agents
- https://blog.google/innovation-and-ai/products/gemini-app/personal-intelligence/
- https://www.anthropic.com/news/healthcare-life-sciences
- https://www.anthropic.com/news/accelerating-scientific-research
- https://x.com/safety/status/2011573102485127562?s=46&t=WJk1XsCZ8sl9JUUP5FZJNw
- https://www.nature.com/articles/d41586-025-04041-0
- https://www.theguardian.com/technology/2026/jan/11/google-ai-overviews-health-guardian-investigation
- https://www.teslarati.com/tesla-optimus-v3-early-third-party-feedback-video/
- https://blogs.nvidia.com/blog/jpmorgan-healthcare-nvidia-lilly/
- https://arxiv.org/abs/2601.07055
What is TranslateGemma, and why does it matter?
TranslateGemma is Google’s open translation model family (4B, 12B, 27B) built for fast, high-quality translation across 55 languages. The practical win is cost and latency: teams can ship strong translation on-device or on modest GPUs instead of relying on heavy cloud inference. It also matters because the 12B variant is positioned as “small but sharp,” aiming to match or beat larger baselines in benchmarked quality, which changes how developers think about multilingual features in real products.
What changed in MedGemma 1.5, according to AI News January 10 2026?
MedGemma 1.5 expands open multimodal medical capability beyond simple 2D images into tougher modalities like CT, MRI, and histopathology, plus improved longitudinal chest X-ray reasoning. It’s designed as a base model you evaluate and adapt, not a plug-and-play clinician. Paired with MedASR, it targets a real bottleneck: clinical dictation accuracy, especially for specialized vocabulary, so downstream workflows (summaries, structured extraction, coding support) start from cleaner text.
What is Claude Cowork mentioned here, and what makes it different from chat?
Claude Cowork is Anthropic’s “work-with-files” mode that operates inside a user-selected local folder. Instead of asking you to paste context, it can read, organize, edit, and generate files directly, like turning screenshots into an expense sheet or drafting a report from scattered notes. The key difference is agency and locality: it behaves more like a teammate finishing tasks than a chatbot producing text blobs. That also raises stakes, since file access demands stricter permissions and careful prompts.
What is the Universal Commerce Protocol, and why should merchants care?
UCP is Google’s open standard designed for agentic commerce, letting AI experiences move from product discovery to purchase with fewer steps. The merchant-friendly promise is control: brands stay the merchant of record, keep customer relationships, and connect through existing Google Merchant Center feeds rather than rebuilding their stack. In practice, UCP is a commerce “glue layer” that can reduce checkout friction inside AI surfaces today, then expand into carts, loyalty, and post-purchase flows over time.
Why are people talking about Dr. Zero in AI News January 10 2026?
Dr. Zero is a research framework where search agents improve through a self-evolving loop without human-written training questions. One model proposes questions, another solves them using a search tool, and the system ratchets difficulty upward as capability grows. The standout idea is using search as the supervision source, which can scale learning without curated datasets. It also adds a compute-saving optimization so training doesn’t explode in cost when tasks require multi-step tool use and verification.