

Introduction
If you want a clean signal on where AI is heading, stop staring at the flashiest demo and start watching what breaks. This week, the most important stories weren’t “look, it writes a poem.” They were “look, it can take actions,” and then, immediately, “look, we had to build seatbelts.”
That’s why this roundup leans into the unsexy layer, security, evaluation, compliance, and the steady grind of making systems reliable in the real world. When models leave the chat box and pick up tools, the failure modes change. A prompt injection looks less like a prank and more like a wire transfer. A benchmark looks less like a flex and more like a contract. And open source AI projects stop being hobby repos and start being the measuring tape that keeps big labs honest.
AI News December 27 2025 has a surprisingly coherent pattern. You can feel the industry shifting from model-as-oracle to model-as-operator, and that shift shows up across Agentic AI News, AI regulation news, and the AI and tech developments past 24 hours that teams actually have to respond to:
- Agents are getting hands. Browser agents, slide builders, coding copilots, and “digital employees” are moving from suggestions to actions.
- Measurement is becoming a product. Automated red-teaming, alignment eval factories, and utility audits are turning into the new competitive moat.
- The research frontier is still restless. New AI papers arXiv are probing alternatives to today’s defaults, from attention-free mixers to new vision pretraining objectives.
I’ll cover 15 top AI news stories. Each one includes a quick “why it matters” angle, because the difference between AI world updates and actual AI advancements is whether you can use the insight Monday morning. Call this AI updates this week, with enough context to build. If you only read two threads, track the OpenAI news today on agent security and the Google DeepMind news-adjacent push for multimodal reasoning and science. It’s also still AI News December 27 2025, so the surprises are grounded ones.
Table of Contents
1. ChatGPT Atlas Gets RL Red-Teaming Shield Against Prompt Injection Scams

OpenAI is treating prompt injection like the new phishing, except the “person” being tricked is a browser agent that can click, type, and move real data. ChatGPT Atlas makes the untrusted surface basically unbounded, from email threads to shared docs to whatever random page you just opened, so the failure mode is not a software bug. It is the agent obeying the wrong boss.
The defense is refreshingly concrete. OpenAI trains an internal attacker with reinforcement learning, lets it rehearse exploits in a simulator, then turns every successful attack into fuel for stronger safeguards and monitoring. For users, the advice is simple: keep logins minimal, read confirmations like contracts, and prompt narrowly.
ChatGPT Atlas: Unlock Faster Browsing, Smarter Research, And Actionable Automation
2. California SB 53 Forces Transparency In Frontier AI Act Compliance Playbooks
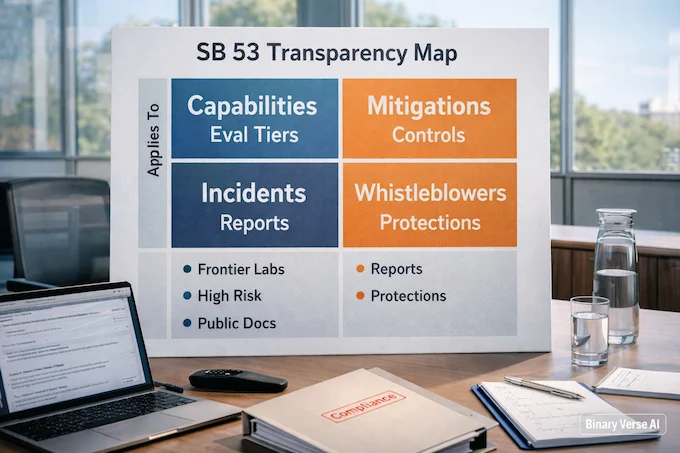
California’s SB 53 takes effect January 1 and sends a clear signal: if you build frontier models that could plausibly cause catastrophic harm, you owe the public a safety story that can be inspected. If you are using an AgentKit guide to build tools, understanding these boundaries is now essential.
The interesting detail is what the law does not do. It requires transparency and ongoing practice, not a single mandated technique that would fossilize quickly. Anthropic still argues for a federal standard to avoid state-by-state fragmentation, but SB 53 becomes the first real compliance pressure test for big U.S. labs.
EU AI Act Compliance Checklist: 34 Real World Requirements (2025 Update)
3. Gemini 3 Caps Google’s 2025 Breakthrough Year Of Agents And Science

Google’s 2025 recap reads like a company deciding that AI is now a deployment sport, not a lab sport. The Gemini 3 benchmarks and the cadence of 2.5, then 3 Pro, then 3 Flash, plus steady upgrades to the open Gemma line, points to an emphasis on reasoning, multimodality, longer context, and efficiency that developers can actually ship.
The product layer is the tell. Gemini shows up across Search, Pixel devices, NotebookLM Deep Research, and a crowded Labs pipeline of agent-flavored experiments, while the science section leans on AlphaFold, math reasoning, and inference hardware. This is the big-company backbone of AI News December 27 2025.
4. Nano Banana Pro Rolls Out Across Gemini App, Search, And Workspace
Nano Banana Pro is Google’s push to make image generation feel native instead of a tab you open once for fun. It pairs the image model with Gemini 3 Pro to better track intent, then threads it through the Gemini app, AI Mode in Search, NotebookLM, Slides, Vids, Flow, and even Labs presentation tools.
The more important shift is workflow. Features like “Help me visualize” and “Beautify this slide” act like mini design agents that output something you can ship to a meeting, not a pile of pretty options. Expect competitive pressure on text rendering, edit fidelity, and controllable styling.
5. T5Gemma 2 Brings 128K Multimodal Encoder-Decoder Models To Gemma
T5Gemma 2 is a quiet but meaningful architecture bet: encoder-decoder models are not dead, they are evolving. Built on Gemma 3 foundations, this line brings multimodality and long-context processing into a family that has mostly been discussed in decoder-only terms, and it’s aimed at fast iteration, even on smaller hardware.
Google highlights efficiency moves that matter in practice, shared encoder-decoder embeddings and a unified attention layer that merges self and cross attention to cut parameters and improve parallelism. The headline spec is up to 128K context plus 140+ languages, which makes the release feel like an invitation to fine-tune for real document-heavy workflows.
T5Gemma 2: Run A 128K Multimodal AI Model Locally (Guide + Benchmarks)
6. Bloom Open-Source Evaluations Generate Fresh Alignment Tests In Days
Bloom tackles a painful alignment problem: good behavior evaluations take ages to design, then go stale fast, and eventually leak into training data. Instead of shipping a fixed benchmark, Bloom starts from a behavior definition, generates fresh eliciting scenarios, runs multi-turn rollouts, and judges transcripts to produce stable metrics like elicitation rate and severity.
It’s an agentic pipeline on purpose, understanding, ideation, rollout, judgment, with reproducibility handled through seeds rather than frozen prompts. The team reports strong agreement with human labels and the ability to separate production models from intentionally misaligned “model organisms.” This is the kind of open source AI project that upgrades alignment work from artisanal to industrial.
7. GLM-4.7 Pushes Coding Agents Forward With Reasoning And Tool Mastery
GLM-4.7 is pitched as a reliability upgrade for coding agents, not just a leaderboard shuffle. It competes directly for the title of best LLM for coding 2025, leaning into “interleaved thinking,” planning before tool calls instead of improvising mid-flight.
The standout feature is preserved thinking across turns, which reduces drift during long refactors and multi-file edits, plus a switch to disable thinking for cheap tasks when latency matters. The bigger point for AI news this week December 2025 is that coding models are turning into controllable systems with dials, not a single blob of talent you hope behaves.
8. MiniMax M2.1 Raises Multilingual Coding Bar For Real-World Agentic Workflows
MiniMax M2.1 goes after the messy reality of software: real products are multilingual, and agent workflows touch code, docs, and tools in the same breath. The update focuses on stronger performance across Rust, Java, Go, C++, Kotlin, Objective-C, TypeScript, and JavaScript, with an emphasis on handling stacked constraints without collapsing into brittle shortcuts.
M2.1 also trims token waste, generating more concisely and integrating cleanly across popular agent shells and rule systems. MiniMax introduces a full-stack benchmark, VIBE, that checks runtime behavior and visuals, not just code snippets. That end-to-end posture is a recurring motif in AI News December 27 2025.
AgentKit: Pricing, Setup, Full Access, And Why It Matters For AI Agents
9. Next-Embedding Prediction Turns NEPA Into A Strong Vision Learner
NEPA, Next-Embedding Predictive Autoregression, asks a simple question: what if vision pretraining looked more like language modeling. Instead of reconstructing pixels or engineering contrastive objectives, it trains a causal Transformer to predict the next patch embedding in a sequence, using masking and stop-gradient to keep the task stable.
The charm is how little machinery it needs. No decoder-heavy reconstruction head, no discrete tokenizer, no negative pairs. Reported results on ImageNet and ADE20K suggest the objective competes with more elaborate pipelines. If it holds up beyond the paper, it’s a push toward cleaner “predictive” vision learning rather than ever more complicated self-supervision recipes.
Next Embedding Prediction (NEPA): The Autoregressive Trick That Makes Vision Transformers Learn
10. LFM2-2.6B-Exp Uses Pure RL To Beat Bigger IFBench Rivals
Liquid AI’s LFM2-2.6B-Exp is a reminder that scale is not the only lever. It uses pure reinforcement learning to sharpen instruction-following and agent-style discipline, and it claims an IFBench score that beats much larger rivals, the kind of result that makes you re-check your assumptions about where capability really comes from.
The model card keeps expectations sane. It’s framed as a compact workhorse for fine-tuned assistants, extraction, RAG, and multi-turn workflows, not a knowledge monster or a coding specialist. It ships with tool-calling patterns and common inference paths, making it easy to try. That “small but shippable” vibe fits AI News December 27 2025 perfectly.
LFM2-2.6B-Exp Review: The 2.6B “RL-First” Checkpoint That Makes 3B Feel Bigger
11. General Intelligence Clash: LeCun Calls It “Complete BS,” Hassabis Rebuts
Yann LeCun and Demis Hassabis turned a philosophy seminar into a public sparring match regarding general intelligence vs universal intelligence. LeCun calls “general intelligence” an illusion, arguing humans look general only because the world matches what evolution trained us for, and we confuse being good at our niche with being good at everything.
Hassabis pushes back by splitting definitions. He says LeCun is attacking “universal intelligence,” the impossible ideal of optimal performance across all tasks, while “general intelligence” is about broad transfer and flexible learning across many environments. The debate matters because it shapes what labs optimize and what investors expect, and it exposes how much hype hides inside one overloaded word.
General Intelligence vs Universal Intelligence: Why Demis Hassabis and Yann LeCun Are At Odds
12. AI Evaluation Era: Stanford Predicts 2026’s Reality Check On Utility
Stanford’s 2026 outlook sounds like a collective shift from evangelism to evaluation. Tools like MedGemma exemplify this shift toward specialized utility. The framing is blunt: the next question is not “can AI do it,” but “how well, at what cost, and for whom,” with more audits, benchmarks, and uncomfortable postmortems as many deployments under-deliver outside a few sweet spots.
The predictions also highlight AI sovereignty, interpretability in science and medicine, and stricter standards for legal and economic use cases, provenance, workflow disruption, ROI, and real-world safety. Read it as a forecast for more instrumentation and fewer vibes, a theme that also runs through AI News December 27 2025.
13. Prism Hypothesis Unifies Semantic And Pixel Detail In One Autoencoder
The Prism Hypothesis argues that the split between “semantic” and “pixel” vision encoders is not just tradition, it’s spectral. This is highly relevant when reviewing models like Grok 4. Semantic encoders tend to emphasize low-frequency structure that carries categories and relations, while pixel encoders preserve those plus high-frequency detail like texture and edges. Forcing one to impersonate the other creates friction.
Unified Autoencoding proposes a single latent space with explicit frequency-band modulation, anchoring semantics in a fundamental band and capturing fine detail as residual bands you can control. The claim is strong reconstruction without losing semantic usefulness, making the representation friendlier for diffusion-style generation. It’s a rare paper that feels like it has a clean theory of the mess.
SAM 3 Concept Segmentation: 9 Essential Wins Over SAM 2, Use Cases + Limits
14. Grassmann Flows Challenge Self-Attention, Offering An Attention-Free Sequence Alternative
This paper throws a polite rock at the Transformer temple: maybe self-attention isn’t the essence of sequence modeling. Even high-performing models like Qwen3 Coder rely on these principles. It reframes attention as tensor lifting, a powerful move that expands token interactions into a dense structure that is hard to analyze, which may explain why interpretability feels like chasing smoke across heads and layers.
The alternative is Grassmann flows, an attention-free mixer that represents local token pairs as low-rank geometric subspaces and evolves them through structured transformations. Results are competitive, not dominant, but the compute scales linearly with sequence length for fixed rank, avoiding the quadratic tax of full attention. Even if this never dethrones attention, it widens the design space at the right time.
15. DeepGrade IoT Turns Essay Scoring Fairer By Reading How You Write
DeepGrade proposes a twist on automated essay scoring: grade the writing process, not just the final text. This connects to various ChatGPT agent use cases in educational settings. It fuses a transformer encoder for semantic understanding with spatiotemporal encoders for behavioral telemetry like keystroke dynamics and drafting patterns, then adds a fairness-aware scoring head meant to reduce demographic score gaps.
The reported numbers are attention-grabbing, including a high QWK and a bias reduction claim, but there’s a real caveat: the behavioral stream is synthetic in the experiments. Still, the direction matters. As AI regulation news collides with education tech, “process-aware” grading raises privacy, consent, and governance questions fast, and it might also make feedback more honest about uncertainty.
Closing:
Step back and the signal gets pretty clear. We’re not in a “one model to rule them all” moment. We’re in a systems moment. Agents need permissions, audits, and adversaries who think like criminals. Organizations need evaluation that survives contact with messy workflows. Researchers need new primitives, because the best ideas often start as “we tried a weird thing and it worked.”
If you’re building right now, here’s the practical checklist I keep reaching for. Treat tool access like production credentials, not a convenience feature. Keep your evals fresh and behavior-focused, not just benchmark-shaped. When a model looks amazing, ask what it does under pressure, with long-horizon tasks, partial information, and real incentives. That’s where artificial intelligence breakthroughs turn into products, or into incident reports.
Want a deeper dive next. Pick your thread, OpenAI’s agent security, Google’s visual stack, the new AI model releases battling for coding dominance, or the arXiv ideas that might make attention look like a historical accident. Share this with one teammate who actually ships. Then tell me what you want dissected, and I’ll turn it into a practical teardown you can use at work. We’ll keep comparing notes together in AI News December 27 2025.
- OpenAI: Hardening Atlas Against Prompt Injection
- Anthropic: Compliance Framework SB 53
- Google: 2025 Research Breakthroughs
- Google: Nano Banana Pro Availability
- Google: T5Gemma 2 Developer Guide
- Anthropic: Bloom Research & Evals
- Zhipu AI: GLM-4.7 Release Notes
- MiniMax: M2.1 Updates
- arXiv: NEPA Vision Pretraining (2512.16922)
- Hugging Face: Liquid AI LFM2-2.6B-Exp
- MSN: Hassabis vs. LeCun Intelligence Debate
- Stanford HAI: 2026 AI Predictions
- arXiv: Unified Autoencoding (2512.19693)
- arXiv: Grassmann Flows (2512.19428)
- Springer: DeepGrade Essay Scoring Study
What is AI News December 27 2025 covering in one page?
AI News December 27 2025 condenses 15 developments into a single scan, agent security updates, SB53 transparency, major Google model rollouts, fresh eval tooling, and standout arXiv papers. It’s built for readers who want AI updates this week without losing the technical plot.
Why does prompt injection matter so much in AI News December 27 2025?
AI News December 27 2025 treats prompt injection as the core risk tax on agentic AI. When an agent can click, type, and act across real accounts, malicious instructions can hijack intent. The practical takeaway is tighter permissions, clearer task scopes, and explicit confirmations for high-impact actions.
What does SB53 change for AI regulation news in AI News December 27 2025?
AI News December 27 2025 highlights SB53 as a forcing function: frontier developers must publish how they test and manage catastrophic risks, plus incident reporting and whistleblower protections. The shift is from “trust us” blog posts to compliance-grade transparency that competitors, regulators, and users can all read.
Which new AI model releases stand out in AI News December 27 2025?
AI News December 27 2025 spotlights two buckets: (1) Google’s ecosystem push, Gemini 3 and Nano Banana Pro moving into Search and Workspace workflows, and (2) coding-forward releases like GLM-4.7 and MiniMax M2.1 aimed at real agentic work across tools, languages, and longer tasks.
Which new AI papers arXiv matter most in AI News December 27 2025?
AI News December 27 2025 points to a pattern: simpler training objectives with stronger priors, plus alternatives to attention-heavy designs. NEPA reframes vision as next-embedding prediction, Prism/UAE tries to unify semantics and detail, and Grassmann flows argue sequence modeling can stay competitive without classic self-attention.