

A funny thing happened on the way to the next chatbot upgrade: the chatbot started behaving less like a chatbot. GPT 5.5 arrived on April 23, 2026, and the GPT 5.5 release date matters because this launch is less about prettier paragraphs and more about handing work to software that can plan, click, debug, browse, revise, and keep going without needing a motivational speech every six minutes.
The headline isn’t “smarter autocomplete.” We’ve had that movie. The better read is this: OpenAI is pushing from answer engines toward working agents. The GPT 5.5 benchmarks show the same direction across coding, tool use, computer control, math, science, and cyber evaluations. The model is not perfect, and the pricing will make some developers squint at their dashboards like they’ve just opened a cloud bill after a long weekend. Still, the shape of the release is clear. This is a model built for long, messy, tool-heavy tasks.
Table of Contents
1. Complete Benchmarks And Pricing
| Benchmark | GPT 5.5 | GPT 5.4 | GPT 5.5 Pro | GPT 5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| SWE-Bench Pro Public | 58.6% | 57.7% | – | – | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 75.1% | – | – | 69.4% | 68.5% |
| Expert-SWE Internal | 73.1% | 68.5% | – | – | – | – |
| GDPval Wins Or Ties | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| FinanceAgent v1.1 | 60.0% | 56.0% | – | 61.5% | 64.4% | 59.7% |
| Investment Banking Modeling Internal | 88.5% | 87.3% | 88.6% | 83.6% | – | – |
| OfficeQA Pro | 54.1% | 53.2% | – | – | 43.6% | 18.1% |
| OSWorld-Verified | 78.7% | 75.0% | – | – | 78.0% | – |
| MMMU Pro No Tools | 81.2% | 81.2% | – | – | – | 80.5% |
| MMMU Pro With Tools | 83.2% | 82.1% | – | – | – | – |
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| MCP Atlas | 75.3% | 70.6% | – | – | 79.1% | 78.2% |
| Toolathlon | 55.6% | 54.6% | – | – | – | 48.8% |
| Tau2-Bench Telecom | 98.0% | 92.8% | – | – | – | – |
| GeneBench | 25.0% | 19.0% | 33.2% | 25.6% | – | – |
| FrontierMath Tier 1-3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| BixBench | 80.5% | 74.0% | – | – | – | – |
| GPQA Diamond | 93.6% | 92.8% | – | 94.4% | 94.2% | 94.3% |
| Humanity’s Last Exam No Tools | 41.4% | 39.8% | 43.1% | 42.7% | 46.9% | 44.4% |
| Humanity’s Last Exam With Tools | 52.2% | 52.1% | 57.2% | 58.7% | 54.7% | 51.4% |
| Capture-The-Flags Internal | 88.1% | 83.7% | – | – | – | – |
| CyberGym | 81.8% | 79.0% | – | – | 73.1% | – |
| Pricing Option | Input | Cached Input | Output | Notes |
|---|---|---|---|---|
| GPT 5.5 API | $5.00 per 1M tokens | $0.50 per 1M tokens | $30.00 per 1M tokens | Standard API rate, 1M context window |
| GPT 5.5 Pro API | $30.00 per 1M tokens | Not stated | $180.00 per 1M tokens | Higher accuracy tier for harder work |
| Batch And Flex | 50% of standard rate | 50% of standard rate | 50% of standard rate | Slower or asynchronous workloads |
| Priority Processing | 2.5x standard rate | 2.5x standard rate | 2.5x standard rate | Faster, higher-priority serving |
| Codex Fast Mode | 2.5x cost | Not stated | 2.5x cost | 1.5x faster token generation |
Benchmark and pricing figures are drawn from the supplied release text and system card excerpts.
2. What GPT 5.5 Actually Changes

GPT 5.5 is not just a higher-scoring sibling in the model family. Its real change is behavioral. Older frontier models often felt like brilliant interns with no calendar access and mild amnesia. They could write a function, explain a paper, or draft a strategy. Then they’d stop, smile politely, and wait for the next instruction.
This release leans into autonomy. The model is designed to infer intent earlier, use tools more naturally, check intermediate work, and persist through ambiguity. That sounds boring until you’ve watched an agent fail because it forgot why it opened the terminal in the first place. In real work, persistence is intelligence wearing boots.
OpenAI’s own framing is telling. The company says the model is aimed at complex, real-world work: coding, online research, data analysis, documents, spreadsheets, software operation, and tool hopping. That’s not the classic “ask me anything” positioning. That’s “give me the task and come back later.”
This is why the Pro tier matters. GPT 5.5 Pro is the same underlying model, but run with more parallel test-time compute for harder problems. In plain English: it gets more room to think before committing. That matters on tasks where the first plausible answer is usually wrong.
3. GPT 5.5 Benchmarks Reveal The Agent Pattern
The important scores aren’t only the biggest ones. They’re the scores on benchmarks that require doing, not merely knowing.
Terminal-Bench 2.0 is a good example. A score of 82.7% means the model is handling complex command-line workflows that require planning, iteration, and tool coordination. That’s the kind of work where a model has to recover from errors, inspect logs, run tests, and not panic when the shell prints something rude.
OSWorld-Verified points in the same direction. At 78.7%, the model is operating real computer environments through interfaces. That’s a different muscle from answering a trivia question. It has to read the screen, decide what to click, and keep track of a goal across steps. It’s less “write a paragraph about spreadsheets” and more “open the spreadsheet, fix the mess, and don’t delete the CFO’s tabs.”
3.1 Why Computer Use Matters
Computer use is the bridge from chat to work. A model that can reason but can’t operate tools is useful. A model that can reason and operate tools becomes leverage.
That’s why the OpenAI API pricing discussion shouldn’t be separated from capability. Developers don’t pay for tokens because tokens are cute. They pay for completed workflows. If a more expensive model takes fewer attempts, writes fewer broken patches, and needs less babysitting, the unit economics change.
This is also where GPT 5.5 Codex becomes interesting. In Codex, the model is not just producing code snippets. It is working through repositories, tests, refactors, and failures. That’s the difference between a calculator and an engineer with a terminal.
4. GPT 5.5 Pro And The FrontierMath Signal
GPT 5.5 Pro gets the flashy number on FrontierMath Tier 4: 39.6%. That benchmark is designed to be hostile to shallow pattern matching. The problems are hard, weird, and generally not the kind of thing a model can solve by rummaging through memorized internet residue.
The base model scores 35.4% on the same tier, up from 27.1% for 5.4. The Pro variant pushes further. Is that “solved mathematics?” No. Let’s not wear party hats in the lab. But it is strong evidence that extra inference-time reasoning helps on problems where compositional thinking matters.
The useful mental model is search guided by taste. A good reasoning model does not merely enumerate possibilities. It chooses promising routes, notices contradictions, backtracks, and compresses partial insight into the next attempt. That’s how humans solve hard technical problems too, except with more coffee and worse posture.
FrontierMath is not the only academic signal. GeneBench, BixBench, GPQA Diamond, and Humanity’s Last Exam all show the model entering territory where “assistant” starts to feel too small a word. In research settings, the model is becoming a collaborator that can explore, critique, test, and implement. For a broader picture of how LLMs are performing on math benchmarks in 2025, the gap between reasoning tiers continues to widen.
5. OpenAI API Pricing Is Expensive, But Not Automatically Bad
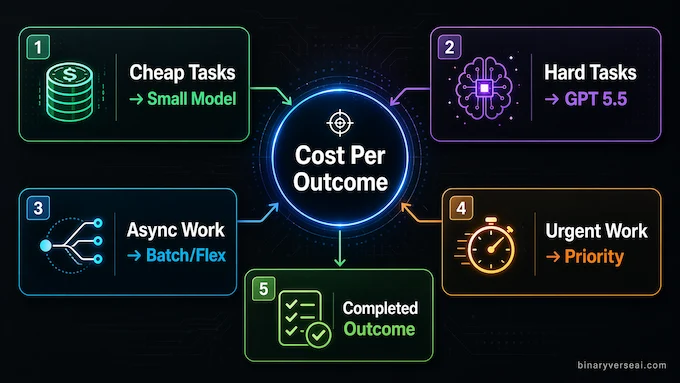
The pricing table will be the part many developers screenshot first. GPT 5.5 costs $5 per million input tokens and $30 per million output tokens. The Pro API tier goes to $30 input and $180 output. That’s not pocket change. That’s “please add spend limits before the intern builds an autonomous report generator” money.
Still, raw token price is a lazy metric by itself. The real question is cost per successful task.
A cheap model that fails three times, writes fragile code, and needs a senior engineer to clean up the mess is not cheap. It’s just billing you in human time. A pricier model that solves the task in one careful pass may cost more per token and less per outcome.
OpenAI’s efficiency claim is that the new model can complete many Codex tasks with fewer tokens than 5.4 while keeping similar real-world latency. The company also says Batch and Flex pricing cut the standard rate in half, while Priority processing costs 2.5x more. That gives developers a familiar menu: save money when time is flexible, pay up when latency matters.
The sane move is not to replace every small job with the most expensive tier. Route work. Use cheaper models for classification, formatting, extraction, and low-risk generation. Save the frontier model for long-horizon tasks where failed attempts are costly. Our LLM pricing comparison and LLM cost calculator can help you model the tradeoffs before committing to a tier.
6. GPT 5.5 Agentic Coding And The End Of Snippet Culture
GPT 5.5 Agentic coding is the cleanest practical story in the launch. The SWE-Bench Pro score is 58.6%, Terminal-Bench is 82.7%, and Expert-SWE is 73.1%. More important, the model appears better at the boring things that make software real: reading context, respecting constraints, checking assumptions, running tests, and carrying changes across nearby files.
That sounds obvious. It isn’t. Most AI coding failures are not caused by the model being unable to write a for-loop. They happen because the model fixes the wrong layer, ignores the migration, breaks the types, forgets the test fixture, or confidently patches a symptom while the root cause sits nearby smoking a cigarette.
The release text includes examples where early users described the model as more persistent and conceptually clear. One account involved resolving a large frontend merge in about 20 minutes. Another described a model-generated architecture change that matched the direction a strong human engineer had taken after days of debugging. Treat these as anecdotes, not proof. But they match the benchmark pattern: the model’s advantage grows when the task has depth.
For engineering teams, this suggests a new workflow. Don’t ask for “a function.” Ask for a plan, tests, a diff, a risk list, and validation. Give the model the shape of the problem. Let it work through the system. Then review it like you’d review a competent teammate who happens to type at inhuman speed and occasionally needs adult supervision. Teams choosing the best LLM for coding in 2025 will find this model’s agentic depth separates it from the pack.
7. Safety, Cybersecurity, And The Trust Problem
The system card is worth reading because it tells the quieter half of the story. A model that can operate tools, inspect codebases, and sustain long cyber workflows is useful for defenders. It is also useful for attackers. Dual-use capability is not a philosophical footnote here. It is the product surface.
OpenAI classifies the model as High capability in cybersecurity and biological or chemical domains, while saying it remains below Critical in cyber. The system card describes stronger safeguards, tighter controls around high-risk cyber activity, and a Trusted Access for Cyber program intended to give verified defenders fewer unnecessary refusals while limiting misuse.
There are also notable safety evals around destructive actions. The system card reports improved destructive-action avoidance at 0.90, plus better perfect reversion and user-work preservation compared with earlier models. That matters for agents. A chatbot can hallucinate a fact and annoy you. An agent can delete the wrong file, rewrite the wrong branch, or “clean up” the one folder you needed. Safety for agents is not just about saying no to bad prompts. It is about not being a clumsy coworker with write permissions. These AI cybersecurity risks are becoming increasingly central to enterprise deployment decisions.
Prompt injection also remains a serious battlefield. Any agent that reads web pages, emails, tickets, docs, or tool outputs can be manipulated by hostile instructions hidden inside those sources. The system card reports a 0.963 score on connector prompt-injection evaluations, slightly below 5.4’s 0.998 but far above 5.1’s 0.649. That is strong, but it is not magic. Developers still need sandboxing, scoped permissions, confirmations, logs, and boring old paranoia. Boring old paranoia has excellent uptime.
8. Scientific Work Is Becoming A First-Class Use Case
The scientific section is where the release becomes more interesting than a coding leaderboard. GeneBench, BixBench, FrontierMath, and the Ramsey-number example all point to the same ambition: models that help experts move from vague question to tested artifact.
That does not mean the model is now a scientist in the romantic sense. It does mean it can compress parts of the research loop. It can inspect data, propose analyses, write code, critique assumptions, compare alternatives, and generate a report that gives a human expert something sharper to argue with.
This is the pattern we’ve seen before in software. The first useful coding models accelerated narrow tasks. Then they started helping with larger repo-level work. Research may follow a similar path: first literature summaries, then scripts, then analysis plans, then multi-step investigation. Work like AlphaFold’s achievements in protein structure is an early marker of what scientific AI collaboration can look like at scale.
The risk is obvious. A model that sounds fluent in a technical field can be wrong in fluent technical ways. The upside is also obvious. If the human remains in charge of validation, the model becomes a tireless generator of hypotheses, checks, and prototypes. That’s not artificial genius. It’s intellectual scaffolding at scale.
9. Final Verdict: Who Should Upgrade?
This release is not for everyone in the same way.
If you need cheap, high-volume text generation, don’t reflexively pick the frontier tier. Use a smaller model, batch the work, cache aggressively, and keep your accountant hydrated.
If you need careful code review, complex refactors, tool-heavy debugging, professional research, spreadsheet modeling, or multi-step operational work, the new model becomes much more compelling. Its value is not that it answers a single prompt better. Its value is that it stays oriented longer.
For developers, the practical strategy is routing. Use cheaper systems for cheap tasks. Use the expensive model where mistakes compound. Put the Pro tier behind the hardest jobs, the ones where a wrong answer costs hours, not seconds. The agentic AI tools and frameworks landscape has expanded enough that there’s now a full stack to build around these capabilities.
For everyone else, the simplest summary is this: GPT 5.5 is a meaningful step from AI that responds toward AI that works. It still needs review. It still needs guardrails. It still needs humans with judgment, taste, and the nerve to say “run the tests again.”
But the direction is now hard to miss. The next productivity jump won’t come from asking better prompts. It will come from designing better handoffs. If your workflow still treats AI like a fancy search box, start redesigning it around delegation. The agentic era won’t wait for your org chart to catch up.
Why Is The GPT 5.5 API Pricing So Expensive Compared To Older Models?
The GPT 5.5 API is expensive because OpenAI is pricing it as a high-reasoning agentic model, not a simple text generator. GPT 5.5 Pro costs $30 per 1M input tokens and $180 per 1M output tokens, but the value case is token efficiency. If it solves harder tasks with fewer retries, the total cost per completed workflow can be lower.
What Is The Difference Between GPT 5.5 And GPT 5.5 Pro?
GPT 5.5 and GPT 5.5 Pro use the same underlying model, but GPT 5.5 Pro applies more parallel test-time compute. That means it spends more effort on difficult reasoning tasks before answering. The Pro tier is built for harder business, coding, research, legal, education, and data-science work where accuracy matters more than raw speed.
Is GPT 5.5 Better Than Claude Opus 4.7 And DeepSeek V4?
GPT 5.5 is strongest when the task requires autonomous execution. Claude Opus 4.7 remains excellent for careful code review and nuanced writing, while DeepSeek V4 is attractive for open-source and cost-sensitive use. GPT 5.5 stands out on agentic workflows because it can use tools, run commands, navigate interfaces, debug, and keep working with less hand-holding.
What Does It Mean That GPT 5.5 Is An Agentic AI?
An agentic AI can do more than answer prompts. GPT 5.5 can plan a multi-step task, use tools, write code, inspect errors, revise its approach, and continue until the job is finished. In practical terms, it behaves less like a passive chatbot and more like a digital worker that can handle messy, real-world tasks.
Why Did OpenAI Restrict GPT 5.5’s Cybersecurity Features?
OpenAI restricted some GPT 5.5 cybersecurity capabilities because advanced cyber reasoning can be useful for both defenders and attackers. The model performs strongly on vulnerability discovery and cyber benchmarks, so OpenAI uses gated access, safety monitoring, and trusted programs to support legitimate security research while reducing the risk of misuse.