

Introduction
Ever notice how real problem-solving feels like a tiny meeting in your head? One voice wants the clean solution. Another mutters, “That’s too easy.” A third tries a shortcut. Then the adult in the room asks for a quick check before anyone ships it.
A lot of recent “reasoning” LLM traces read the same way. Not just longer, but more social. More back-and-forth. More internal debate. That’s the core idea behind Societies of Thought: some modern reasoning models don’t merely think for more tokens, they simulate multiple perspectives inside a single trace, and that social structure seems to matter.
If you’ve been watching the wave of ai reasoning models and thinking, “Why do these answers feel different?” this is your map. We’ll define Societies of Thought, show the specific “social moves” researchers measured, connect it to llm agents, and end with the practical stuff: cost, latency, and llm evaluation you can actually run.
Table of Contents
1. Societies Of Thought: A Fast Definition (And What It Is Not)
Societies of Thought is a pattern you can see in one model’s reasoning trace: it behaves like a small group discussion, with question-answering, perspective shifts, and sometimes open disagreement that later gets resolved. The “society” is not multiple models running in parallel. It’s one model producing a multi-perspective routine in a single generation. The work operationalizes this by labeling specific conversational behaviors inside the trace.
To save you from common SERP confusion, here’s the fast map.
Societies of Thought Glossary Table
| Term | What It Means Here | What It’s Not |
|---|---|---|
Societies of Thought | One model, one trace, multiple simulated perspectives interacting | Political ideology or sociology |
Internal debate | Asking, answering, challenging, revising inside one trace | A chat between two separate models |
Multi-voice reasoning | Viewpoints that shift mid-trace | Roleplay for entertainment |
Conversational scaffolding | Training or formatting that nudges dialogue-like structure | Tools, memory, orchestration |
1.1 The One-Line Test
If the trace contains real interaction, not just a long monologue, you’re probably looking at Societies of Thought. You’ll see proposals get questioned, conflicts get surfaced, and steps get verified.
2. Why This Went Viral: “Think Longer” Was A Weak Explanation
When a new reasoning model drops, the first explanation is always “more compute.” Sometimes that’s true. Here it’s incomplete.
In this paper, the authors control for reasoning trace length when comparing reasoning models like DeepSeek-R1 and QwQ-32B to instruction-tuned counterparts, and still find the reasoning models show more conversational behaviors and socio-emotional roles even when trace lengths are similar.
That flips the story. Societies of Thought is not a synonym for “long chain-of-thought.” It’s about the structure of the chain, the moves inside it.
3. What Is An AI Reasoning Model?
An AI reasoning model is a language model tuned to produce intermediate reasoning traces that help it solve multi-step problems, not just respond nicely.
In practice, ai reasoning models tend to do three useful things:
- Keep going after the first plausible idea.
- Check constraints more often.
- Recover when the path gets shaky.
The paper’s comparisons are clean because they pair each reasoning model with a closely related instruction-tuned baseline, like DeepSeek-R1 vs DeepSeek-V3 and QwQ-32B vs Qwen instruction-tuned variants.
3.1 Where They Still Break
Strong reasoning models still fail in familiar ways: wrong assumptions, brittle math, and confident answers built on sand. The point of Societies of Thought isn’t perfection. It’s more chances to notice the sand before you pour concrete.
4. The Hidden Debate Engine: Social Moves Inside A Single Trace
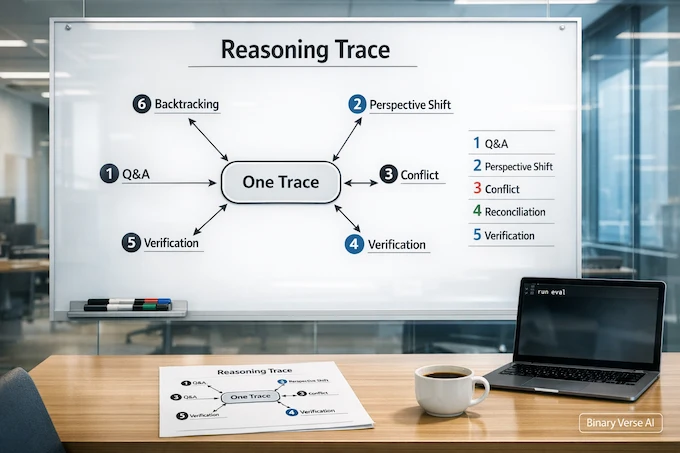
The research names four conversational behaviors that signal simulated exchanges among multiple perspectives: question and answering, perspective shift, conflict of perspectives, and reconciliation.
Alongside those, it tracks cognitive behaviors that look like classic problem-solving: verification and backtracking, plus subgoal setting and backward chaining. It also tags socio-emotional roles using Bales’ Interaction Process Analysis, a taxonomy of how groups ask, give, agree, and disagree in dialogue.
4.1 A Mini-Example You Can Actually Spot
When Societies of Thought shows up, the trace often follows this loop:
- Ask: “What does the constraint really imply?”
- Answer: “If it implies X, then step 2 changes.”
- Challenge: “But that conflicts with the earlier assumption.”
- Revise: “Drop the assumption, try the other branch.”
- Verify: “Plug it back into the original question.”
- Backtrack: “Nope, rewind to the last stable step.”
That’s not theater. It’s an internal workflow, and when you see it repeatedly, you’re basically watching Societies of Thought do its thing.
5. Do Social Behaviors Actually Matter Or Are They Just Style?
This is the section where the paper stops being cute and starts being useful.
They run a mediation analysis linking “being a reasoning model” to higher accuracy, then estimate how much of that advantage is explained by social behaviors in the trace. The headline: more than 20% of the accuracy advantage is explained by the direct and indirect effect of social behaviors manifest in the reasoning trace.
That’s a strong claim with a practical implication. If you care about accuracy at a fixed budget, you should care about the shape of the reasoning trace, not just its length.
5.1 Why The 20% Result Changes How You Prompt
If a model’s trace is a scaffold for thinking, then you can nudge it toward better scaffolds. Prompts that encourage explicit questions, checks, and perspective changes can be more than “style.” They can be performance.
This is also why Societies of Thought feels like a step change. It’s a routine, not a vibe.
6. Where Do Societies Of Thought Come From: RL, Data, Or Both?
The internet argument is predictable: “It learned this from forum data” versus “RL did it.”
The paper gives evidence that reinforcement learning can produce the behavior even without explicit dialogue training signals. In a controlled RL setup that rewards only accuracy and formatting, the base model spontaneously develops conversational behaviors like self-questioning and perspective shifts.
That suggests Societies of Thought can be an attractor: rewarded for being right, the model discovers that arguing with itself is a decent strategy.
6.1 The Order Of Emergence Is Telling
In RL training trajectories, question-and-answering emerges first and rises fastest. Then conflict of perspectives and perspective shifts rise after. Verification increases dramatically and tracks closely with question asking and answering, while backtracking follows conflicts.
It’s almost a developmental timeline: ask, disagree, check, rewind.
7. Dialogue Scaffolding: The Shortcut To Better Reasoning Traces
Format matters more than people want to admit.
The authors compare models fine-tuned with multi-agent dialogue scaffolding versus monologue-style reasoning scaffolding during reinforcement learning. Dialogue-scaffolded models reach high accuracy faster, though both eventually converge.
7.1 Why Dialogue Helps
Dialogue creates turn boundaries, invites questions, and makes “Wait, that doesn’t follow” feel natural. It’s conversational scaffolding as a cognitive scaffold. If Societies of Thought is partly about structure, this is a very direct lever.
8. Society Of Thought Vs Agents: Where LLM Agents Actually Fit

Let’s do the clean comparison, because buzzwords are cheap.
Society of thought vs agents comes down to where coordination happens.
- Societies of Thought: one model call, one trace, multiple internal perspectives.
- LLM agents: multiple calls, tools, memory, orchestration, and often explicit roles.
LLM agents shine when you need to browse, write code, call APIs, or maintain state. They also add overhead and new failure modes. Internal debate is cheaper, faster, and more fragile in different ways.
8.1 What Are LLM Agents, Really?
What are llm agents? They’re workflows that turn an LLM into a controller: plan, call tools, check results, repeat. Sometimes it delegates to other models. Sometimes it assigns roles. That’s external coordination, not an internal society.
8.2 Where The Paper Fits In
The paper’s labeling setup uses an LLM-as-judge and reports substantial agreement with a human rater and another LLM. That’s about measuring the behavior. The phenomenon itself is inside a single model’s trace.
9. Mechanistic Interpretability: Can We Steer The Debate?
This is the part that feels like science fiction until you realize it’s just linear algebra.
The authors use sparse autoencoders, SAEs, a sparse autoencoder (SAE) technique that helps isolate interpretable features in a model’s activation space and manipulate them during generation. They curate Feature 30939, summarized as “a discourse marker for surprise, realization, or acknowledgment,” and note it appears heavily in conversational contexts.
9.1 A Small Nudge, A Big Shift
On the Countdown task, positive steering of this feature boosts accuracy from 27.1% to 54.8%. Negative steering drops accuracy to 23.8%.
Positive steering also increases the four conversational behaviors, including more question-answering, more perspective shifts, more conflict, and more reconciliation. And it increases cognitive behaviors like verification and backtracking, rising with steering strength.
So a social cue seems to unlock cognitive tactics. That’s the “debate engine” idea made concrete.
9.2 Don’t Over-Interpret The Knob
The authors note extremes of steering can hurt accuracy and they evaluate moderate ranges. Still, it’s hard to look at these causal shifts and call Societies of Thought “just style.”
10. The Clinical Psych Angle (Hajra): When Internal Debate Helps, When It Turns Into Noise
Put on Hajra’s hat for a second. Internal dialogue is healthy when it has a job and an endpoint. It’s unhealthy when it loops.
The useful version surfaces alternatives, challenges assumptions, and ends with a decision. The noisy version is conflict with no reconciliation, checks that exist only to justify a preferred answer, and infinite backtracking because no one is allowed to be wrong.
The practical takeaway for builders is surprisingly therapeutic: encourage structured checks, not endless arguing. Societies of Thought is strongest when it creates a short, disciplined debate, then lands the plane.
11. The Cost Side: AI Inference, Latency, And The Token Bill

Now the part your finance team cares about: ai inference. Societies of Thought is often the expensive option, because debate costs tokens.
A “social” trace tends to ask more questions, explore more alternatives, and backtrack more. That’s extra tokens, which means extra latency, which means extra money. The trade-off is real:
- More internal debate can raise accuracy on hard tasks.
- More internal debate also raises cost.
11.1 AI Inference Vs Training: Why This Debate Shows Up On Your Bill
ai inference vs training is the difference between paying once and paying forever.
Training and fine-tuning can teach better habits, like the dialogue scaffolding effect that reaches high accuracy faster. Inference is where you pay per request for the routine the model chooses. The production move is simple: decide which tasks deserve debate, cap the rest, then measure whether the debate buys accuracy at your chosen budget.
12. How To Evaluate It: LLM Evaluation Metrics That Actually Catch This Behavior
If you want to deploy this reliably, you need llm evaluation that goes beyond “right or wrong.” You need a llm evaluation framework that captures whether the model is doing useful work versus performative work.
Here’s a table you can steal.
Societies of Thought Evaluation Metrics Table
| What To Measure | How To Measure It | Why It Matters |
|---|---|---|
Accuracy at fixed token budget | Hold token limit constant across prompts | Separates real reasoning from token burn |
Verification rate | Count explicit checks and constraint re-plugs | Rewards “trust but verify” |
Backtracking rate | Detect rewinds and revised subgoals | Measures escape from bad branches |
Consistency under paraphrase | Same problem, reworded input | Catches brittle prompting dependence |
Disagreement quality | Does conflict introduce new evidence? | Avoids pleasant echo chambers |
Reconciliation presence | Conflict followed by integration | Ensures debate actually ends |
The paper’s RL trajectories explicitly connect question asking and answering with strong growth in verification, and connect conflict with later backtracking.
12.1 The Metric That Keeps You Honest
If you only pick one metric, pick accuracy at a fixed budget. It forces honesty about cost, and it tells you whether the internal debate is doing work.
Closing: Build The Debate, Then Put A Timer On It
The best mental model I’ve found is simple: modern reasoning models are learning an internal team meeting. Sometimes that meeting is brilliant. Sometimes it’s a room full of interns arguing about the font.
This research makes a tight case that conversational, multi-perspective behaviors are not decoration. They show up even when you control for length. They emerge under reward for accuracy. They explain a meaningful chunk of accuracy gains. And a mechanistic nudge toward a conversational marker can shift both behavior and performance.
Now your move. Pick one workflow you care about, run it through your favorite ai reasoning models, and log the moves: questions, conflicts, checks, rewinds. Then decide where you want Societies of Thought turned on, where you want it capped, and what you’re willing to pay for it.
If this post helped, share it with a friend who still thinks “reasoning” just means “longer prompts.” Better debates deserve better myths.
What is reasoning in AI?
Reasoning in AI is the ability to reach conclusions by combining steps, rules, or learned patterns, not just repeating memorized text. In modern LLMs, it often shows up as multi-step problem solving with verification and backtracking.
Is AI capable of reasoning?
Yes, to a degree. AI reasoning models can solve multi-step tasks more reliably than standard chat models, but they still hallucinate, miss edge cases, and can be sensitive to prompts and missing knowledge.
Which AI has reasoning?
Look for “reasoning models” or “thinking models” designed for multi-step work. In the open-weights world discussed in this paper’s orbit, examples include DeepSeek-R1 and QwQ-style reasoning models.
What are the 4 types of reasoning?
A common, simple breakdown is deductive, inductive, abductive, and analogical reasoning. LLMs can approximate all four, but reliability varies a lot depending on the task, constraints, and evaluation setup.
What is the difference between AI inference and AI training?
Training updates model weights using data and optimization. AI inference is running the trained model to produce outputs. Many reasoning gains raise ai inference vs training trade-offs because better answers can require longer or more structured internal computation.