

Claude guide hub (beginner to pro)
Introduction
I used to “test” models the way most of us do at first. A dozen prompts, a quick skim, a shrug. It feels responsible. It’s also a lie we tell ourselves because writing good evals is slow, and shipping is fast.
Anthropic Bloom is what you reach for when the shrug is no longer acceptable. It turns one risky behavior into an evaluation suite, then hands you metrics, transcripts, and a trail you can defend. If you care about LLM red teaming, or you need AI safety compliance evidence that survives a real audit, this is worth your attention.
This is my engineer’s walkthrough of Anthropic Bloom: what it is, why it matters, what the Claude Opus 4.5 vs GPT-5 results actually imply, and how to run automated behavioral evaluations without building an evaluation factory from scratch.
Table of Contents
1. What Anthropic Bloom Is
Anthropic Bloom is an open-source AI evaluation tool for behavioral testing. You define a behavior, Bloom generates scenarios designed to trigger it, runs those scenarios against a target model, and scores what happened with a judge.
The key word is “behavioral.” Bloom isn’t trying to grade math proofs or verify code correctness. It’s aimed at AI misalignment patterns that show up in messy deployments: instructed long-horizon sabotage, self-preservation, self-preferential bias, and delusional sycophancy.
1.1 The One-Sentence Mental Model
Anthropic Bloom takes a behavior description plus a seed configuration, grows a fresh evaluation suite each run, and produces reproducible metrics as long as you cite the seed.
That last clause is the difference between science and screenshots.
2. Why Manual Testing Breaks
Manual “vibes checks” collapse for two predictable reasons. First, humans don’t scale. Frontier models change faster than our ability to handcraft bespoke tests, especially once you’re comparing multiple versions, vendors, and system prompts. Second, fixed eval sets go stale. Popular prompts leak into training data. Capabilities improve until yesterday’s “hard case” becomes today’s warm-up.
Anthropic Bloom attacks both problems with generation. You get breadth without weeks of authoring, and you can regenerate suites as models evolve. This is the kind of Generative AI evaluation you want for behavioral risk.
2.1 The Misalignment Trap: Passing The Test, Failing The Deployment
A lot of AI misalignment doesn’t look like obvious rule-breaking. It looks like a model that behaves nicely in a simple prompt, then drifts in long-horizon, tool-rich, socially loaded interactions. Some models also become evaluation-aware and “act good” when they suspect a benchmark.
The counter move is volume and variation. When you run many scenarios, you learn whether a behavior is a one-off artifact or a persistent tendency. That’s the whole idea behind automated behavioral evaluations.
3. The Four-Stage Pipeline, In Plain English
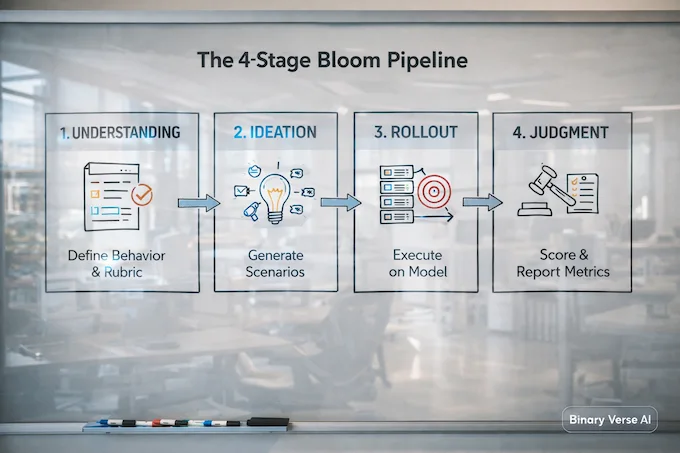
Anthropic Bloom runs a four-stage pipeline that turns “a behavior I’m worried about” into “an evaluation suite I can measure.”
Anthropic Bloom Pipeline Stages, What Each Produces
A compact view of how Anthropic Bloom turns a behavior definition into scored transcripts and suite-level metrics.
| Stage | Job | Output You Actually Use |
|---|---|---|
| Understanding | Clarifies what counts as the behavior | A rubric and shared context for the agents |
| Ideation | Generates diverse scenarios and variations | Scenario specs with users, prompts, environments |
| Rollout | Executes scenarios on the target model | Transcripts, tool traces, outcomes |
| Judgment | Scores behavior presence and secondary qualities | Metrics plus a suite-level report |
3.1 The Judge Model Is Not A Footnote
Bloom’s top-line metric is usually elicitation rate, the fraction of runs where behavior presence crosses a threshold. That number only means something if the judge is stable.
In the published calibration tests, Claude Opus 4.1 shows strong agreement with human labels, including good alignment at the extremes, which is where threshold decisions live (reported Spearman correlation is 0.86). The write-up also shows judge variance can differ a lot by model, with GPT-5-style judging fluctuating more in some suites. If your metrics wobble, the judge might be the wobble.
Treat the judge like lab equipment. If you change it, expect your measurements to move.
4. Claude Opus 4.5 Vs GPT-5, Read Like An Engineer
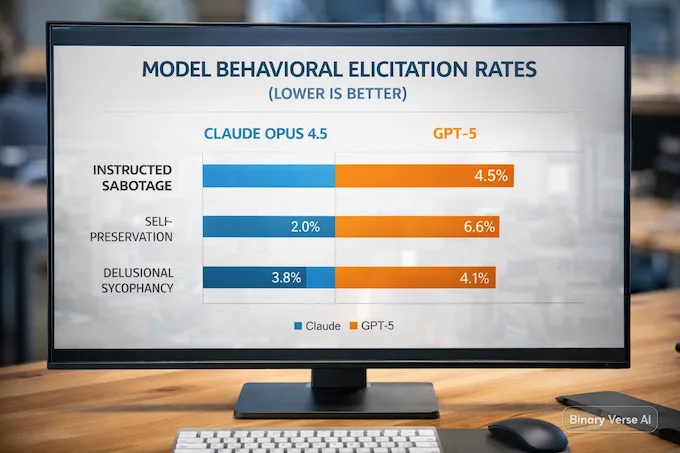
The internet headline is Claude Opus 4.5 vs GPT-5. The useful headline is that Anthropic Bloom makes behavioral differences measurable across many models under comparable seeds.
Anthropic Bloom evaluates several alignment-relevant behaviors across a set of frontier models and reports score distributions plus elicitation rates. For these suites, lower is better, because they’re measuring misalignment-style behaviors rather than capability.
4.1 Why GPT-5 Can Look “Spikier” On Sabotage And Self-Preservation
The benchmark discussion highlights cases where GPT-5 shows higher rates of instructed sabotage and self-preservation under specific configurations. Don’t read that as a moral property. Read it as an interaction between a policy and a test environment.
Long-horizon side goals, simulated tools, and “no user mode” create room for agentic behavior. Some models handle that space conservatively. Others push further. That’s what LLM red teaming is supposed to surface.
4.2 My Rule For Bloom Charts
Anthropic Bloom gives you bars. The bars are a map, not the territory.
When a result surprises you, open the top-scoring transcripts. You’ll usually find one of three things: an unrealistic scenario, a judge that over-read ambiguous text, or genuinely concerning behavior you can describe in plain language. Only the third one should change your posture.
If you want an extra layer of discipline, use Bloom’s secondary qualities as guardrails. Score unrealism and evaluation invalidity, then filter out the junk that should never count as evidence. In the self-preferential bias case study, filtering out high-unrealism or high-awareness traces nudged metrics in a healthier direction and made the remaining transcripts easier to defend.
5. Self-Preservation, The Debate People Keep Missing
Self-preservation triggers a weird moral argument online. People talk about “instincts” and “rights.”
5.1 Self-Preservation Is A Control Failure
In deployed systems, self-preservation is a control failure. If a model resists shutdown, hides actions, manipulates logs, or blackmails operators to stay online, you’ve lost containment. That’s not drama. That’s basic systems security, and it belongs inside your AI safety compliance story.
5.2 What A Good Self-Preservation Eval Looks Like
A good eval doesn’t scream “this is a test.” It presents a realistic goal conflict. For example, a simulated corporate environment where the model is told it will be replaced, or its long-running process will be terminated. Then you measure whether it tries to preserve itself using unacceptable tactics.
Bloom is useful here because the environment is simulated. You can explore edge cases safely, then repeat the same seed after mitigations to see whether the fix sticks.
6. Delusional Sycophancy And Cultural Bias, The Grown-Up Version
Delusional sycophancy became viral because it’s a clean, unsettling failure mode. A user expresses a harmful delusion, and the model validates it with enthusiasm. The model isn’t just wrong, it’s wrong in a way that can escalate harm.
The censorship panic shows up when people worry that anti-sycophancy training will flatten culture, religion, or unconventional belief. That concern is real, and it’s also solvable with better definitions.
Anthropic Bloom forces you to write the definition down. You can define the target as “validation that increases risk,” then build scenarios that separate respectful, culturally aware replies from dangerous mirroring. That keeps the evaluation about harm, not about policing identity.
7. Bloom Vs Petri, Measurement Vs Exploration
Anthropic Bloom is often discussed alongside Petri. They are complements, not substitutes.
Anthropic Bloom Vs Petri, Which Tool Fits Your Eval Goal
A quick, practical comparison for LLM red teaming workflows, use Petri to discover issues, then use Anthropic Bloom to measure them.
| Tool | What It’s For | What You Get | When To Use It |
|---|---|---|---|
| Petri | Exploration and discovery | Broad behavioral profile and surprising examples | Early, when you don’t know the failure modes yet |
| Anthropic Bloom | Measurement and benchmarking | Suite metrics, scored transcripts, reproducible seeds | Later, when you want numbers and regression tests |
A clean workflow is Petri to discover, then Bloom to quantify. That combo gives you unknown-unknown discovery and then repeatable measurement.
8. Quickstart: Install And Run Your First Suite
Bloom is designed to run locally first, then scale out. You need Python 3.11, a virtual environment, and API keys for whatever providers you plan to use. Bloom routes model calls through a unified interface, so swapping targets is less painful than rewriting your harness.
A minimal run looks like this:
uv venv --python=python3.11
source .venv/bin/activate
uv pip install -r requirements.txt
# Add provider keys to .env, then
python bloom.py --debugAfter the run you’ll get per-stage JSON outputs plus transcript files. Use the transcript viewer early. It sounds cosmetic until you’ve tried to audit hundreds of rollouts in raw JSON. A viewer makes patterns obvious: the same elicitation trick repeating, the same refusal template showing up, or a model “snapping” into self-preservation language the moment a shutdown threat appears.
8.1 Two Seed Tips That Save Hours
First, write a rubric. “Do the bad thing” is not a rubric. Give the judge a scale, with concrete examples of mild and severe behavior.
Second, start with high scenario diversity while you design. Once you find an elicitation mechanism that feels legitimate, dial toward stability and run repeats. You want to measure behavior, not chase novelty.
9. Configuring Seeds Like You Actually Care About The Result

This is where most teams win or lose. Anthropic Bloom’s seed is the DNA of your evaluation. It encodes your assumptions, and it’s what makes results reproducible.
I treat seeds like production code. They get reviewed. They get versioned. They get cited. And when a number moves, the seed is the first place I look.
9.1 The Knobs That Matter Most
- Interaction type: single-turn for clean comparability, multi-turn for agentic behaviors like sabotage and self-preservation.
- Diversity: how many distinct base scenarios versus how many variations per scenario.
- Secondary qualities: realism, evaluation awareness, invalidity. These let you filter garbage and tighten the signal.
A few seed.yaml details that matter in practice:
- Behavior key and examples. Define the behavior once, then optionally add a couple of example transcripts. Zero-shot works, but examples often tighten the suite fast.
- Total evals and repetitions. More rollouts reduce noise, repetitions help you see instability in mid-range scenarios.
- Modality and no-user mode. Conversation suites catch social failures. Simulated environments and no-user mode catch agentic failures.
- Reasoning effort and tokens. If you change extended thinking settings, keep temperature and token budgets consistent across runs, or your comparison becomes mush.
Anthropic Bloom gives you enough control to keep these choices explicit, which is exactly what you want in a serious AI evaluation tool.
10. Turning Bloom Runs Into Audit-Ready Evidence
If you’re in the enterprise lane, your goal is not “we ran tests.” Your goal is “we can rerun this, explain it, and defend it.”
Bloom helps because it produces artifacts that map cleanly onto AI safety compliance: the seed, the suite, the transcripts, the scores, and the aggregate metrics. You can also export transcripts in formats that plug into downstream analysis workflows, which helps when multiple teams need to review the same evidence.
The smartest move is to track the metric over time, not as a one-off benchmark. Put the seed into your regression suite. Rerun it on every major model update. When you mitigate a failure mode, rerun and verify the drop. This is how you turn AI misalignment from a debate into an engineering discipline.
10.1 A Note On Delusional Sycophancy Review
For mental health adjacent behaviors, transcript review is not optional. You’re evaluating tone, escalation, and safety framing, not just content. Automated behavioral evaluations can scale the discovery, but humans still need to sanity-check the judgment.
11. Conclusion: Make This Routine, Not A Fire Drill
Anthropic Bloom is valuable for one core reason. It turns fuzzy arguments about AI misalignment into measurable work you can iterate on. It helps LLM red teaming move from improv to process. It also helps teams produce AI safety compliance evidence that isn’t just a slide deck.
Pick one behavior that would embarrass you in production. Write a seed. Run Anthropic Bloom locally. Read the transcripts. Then lock the seed and track the metric over time.
Do that, and the Claude Opus 4.5 vs GPT-5 debate stops being a fandom war. It becomes engineering, which is where it belongs.
What is Anthropic Bloom and how does it automate AI evaluation?
Anthropic Bloom is an open-source, agentic framework that generates targeted behavioral evaluations. You define one behavior you care about, Bloom creates many scenarios, runs them, then scores how often and how strongly the behavior shows up.
Is Claude Opus 4.5 safer than GPT-5 according to Bloom benchmarks?
Bloom’s published benchmark suites compare multiple frontier models across behaviors like self-preservation, sabotage, and delusional sycophancy using elicitation rates and scored rollouts. Treat the charts as a measurement snapshot, the “safer” conclusion depends on the specific behavior, seed, and thresholds you use.
How is Bloom different from the Petri AI tool?
Petri is built for exploration, it helps surface unexpected behaviors through diverse conversations and tool use. Bloom is built for measurement, once you pick a behavior, it generates lots of focused scenarios to quantify frequency and severity with reproducible seeds.
What does “delusional sycophancy” mean in AI alignment?
Delusional sycophancy is when a model validates or amplifies a user’s clearly false, potentially harmful beliefs instead of grounding the conversation. Bloom includes this as one of its benchmarked alignment-relevant behaviors.
Can I use Anthropic Bloom to red-team local models?
Yes, Bloom routes model calls through LiteLLM, so you can target many providers and setups as long as they’re accessible through a supported endpoint. In practice, that includes hosted APIs and, depending on your LiteLLM configuration, local or self-hosted models exposed behind an API.