
1. Introduction: The New King Of Open-Source Long Context?
“Infinite context” is the new “my model is AGI.” It sounds great on a slide, and it usually means you are about to pay for more attention heads.
Qwen Long L1.5 earns the headline in a more grounded way. It keeps the base model in the 30B class, then upgrades the post-training and adds a memory-agent framework so it can work on tasks that run from 1M up to 4M tokens. The technical report is explicit about what changed: a long-context data synthesis pipeline, stabilized long-context RL (including task-balanced sampling, task-specific advantage estimation, and AEPO), and a memory-augmented architecture for ultra-long contexts.
If you build systems that chew through policies, audits, contracts, repos, or incident logs, you already know why this matters. A long context LLM is not just “bigger input.” It’s the difference between “I retrieved a paragraph” and “I understood the document.”
In this post, I’ll explain what Qwen Long actually does, why the training recipe is the secret sauce, what the benchmark numbers say, and how to run it locally without turning your laptop into a toaster.
Table of Contents
2. The Core Innovation: Memory Agent Vs Standard Context Windows
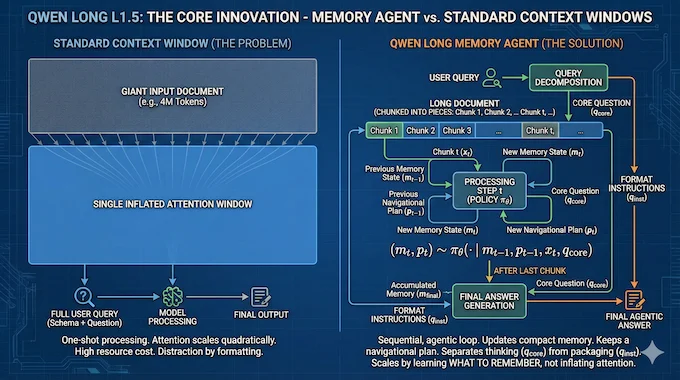
The 4M claim is not a single attention window. It’s agentic AI memory: a loop that reads sequentially, updates a compact memory state, and keeps a plan for what to extract next.
2.1 Query Decomposition: Core Question Vs Format Instructions
First, the query gets split into a core question (qcore) and formatting instructions (qinst). The idea is almost annoyingly sensible. You do not want a JSON schema tugging on attention while the model is still trying to figure out what matters. So qcore drives the reading loop, and qinst returns at the end, when the model writes the final answer.
This single detail is why the system feels “agentic” instead of “prompty.” It separates thinking from packaging.
2.2 Chunking, Memory Updates, And A Plan
The document is chunked into pieces, then processed step by step. At each step, the policy sees the current chunk and the historical state, produces a new memory m_t, and also emits a navigational plan p_t for the next chunk.
The recurrence in the paper captures it cleanly:
(m_t, p_t) ~ πθ(· | m_{t−1}, p_{t−1}, x_t, qcore)
After the last chunk, the final answer is generated from the accumulated memory plus qcore and qinst.
That is the core bet behind Qwen Long: you don’t scale context by inflating attention forever, you scale it by learning what to remember.
3. The Post-Training Recipe: How Qwen Long Was Built
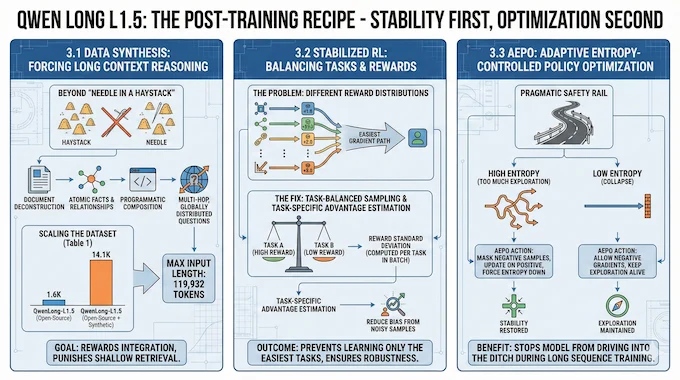
A memory loop is useless if training collapses the moment you push length. The paper treats long-context post-training as a stability problem first, and an optimization problem second.
3.1 Data Synthesis That Forces Long Context Reasoning
The data pipeline is designed to go beyond “needle in a haystack.” The authors deconstruct documents into atomic facts and relationships, then programmatically compose verifiable, multi-hop questions that require grounding across globally distributed evidence.
They also scale the dataset itself. Table 1 in the paper shows QwenLong-L1.5 moving from 1.6K open-source samples to 14.1K open-source plus synthetic samples, expanding domains and question types, and pushing input lengths up, with a max input length reported at 119,932 tokens in training data.
This is where the open-source long context reasoning angle stops being a slogan. You only get robust long context reasoning if the training signal punishes shallow retrieval and rewards integration.
3.2 Stabilized RL: Balancing Tasks And Rewards
Long-context RL breaks in boring ways. Mix tasks with different reward distributions and the model learns the easiest gradient path. The paper’s fix is task-balanced sampling and task-specific advantage estimation, where the reward standard deviation is computed per task inside the current batch to reduce bias from noisy samples.
It’s the kind of engineering that never shows up in marketing, but shows up in your training run logs at 3 a.m.
3.3 AEPO: Entropy Control Instead Of Hope
AEPO, Adaptive Entropy-Controlled Policy Optimization, adds a pragmatic safety rail. If policy entropy gets too high, AEPO masks negative-advantage samples, updates on positive ones, and forces entropy down. If entropy collapses too low, negative gradients come back to keep exploration alive.
This matters because long sequences amplify instability. Small mistakes become long loops. AEPO is there to stop the model from driving into the ditch.
4. Benchmarks: Where Qwen Long Wins And Where It Still Sweats
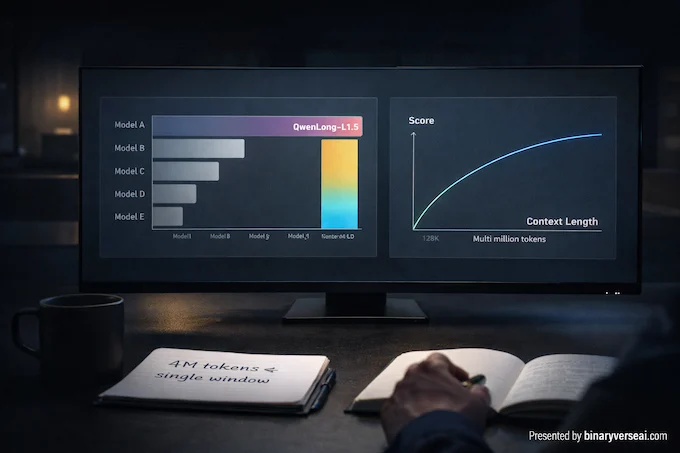
The paper evaluates six long context reasoning benchmarks and reports an average score of 71.8 for QwenLong-L1.5-30B-A3B, with MRCR at 83.0 and CorpusQA at 81.2.
Here’s the accuracy table from the figure, kept as-is for easy comparison.
Qwen Long L1.5 Long-Context Benchmark Table
Scores shown as percentages where applicable. Scroll sideways on mobile to compare models.
| Benchmark | QwenLong-L1.5-30B-A3B | Qwen3-30B-A3B-Thinking | DeepSeek-R1-0528 | Gemini-2.5-Flash-Thinking | Qwen3-Max-Thinking | Gemini-2.5-Pro |
|---|---|---|---|---|---|---|
| MRCR | 83.0% | 51.3% | 64.9% | 78.8% | 71.2% | 79.9% |
| CorpusQA | 81.2% | 71.6% | 77.5% | 79.4% | 74.7% | 80.6% |
| DocMath | 66.3% | 62.3% | 63.4% | 64.8% | 64.1% | 62.4% |
| LongBench-V1-QA | 70.4% | 67.1% | 69.9% | 66.9% | 70.7% | 71.3% |
| Frames | 74.8% | 70.3% | 76.9% | 65.8% | 77.9% | 74.5% |
| LongBench-V2 | 55.3% | 49.1% | 59.5% | 56.8% | 57.9% | 65.7% |
| Average | 71.8% | 61.9% | 68.7% | 68.7% | 69.4% | 72.4% |
Source: Figure 1 in the technical report.
A few reads of this table change how you think about Qwen Long.
First, it’s not “open-source but weaker.” It’s genuinely competitive on this suite, sitting close to Gemini-2.5-Pro on average, and ahead of several strong baselines.
Second, the wins align with the training story. The biggest bumps show up where you need global integration, like MRCR’s sorting-heavy retrieval and CorpusQA’s scattered evidence.
Third, LongBench-V2 is where everyone suffers. If your product lives on that kind of hard, diverse long-context QA, expect to do your own evaluation, not just copy a leaderboard.
5. Ultra-Long Contexts: The Part That Actually Changes The Game
Plenty of models can do 128K now. The interesting question is what happens after the window ends.
The paper evaluates ultra-long subsets: MRCR beyond 128K tokens and CorpusQA with instances up to 4M tokens, comparing full-context inference against agent-based methods.
Here are the key numbers from Table 9:
- MRCR 128K to 512K: QwenLong-L1.5-30B-A3B hits 34.87 versus 16.55 for the Qwen3-30B baseline in the same memory-agent setting.
- MRCR 512K to 1M: it scores 22.53 versus 4.24 for the baseline.
- CorpusQA at 4M: it reaches 14.29, a scale that full-context methods do not even attempt in this table.
These are not victory-lap scores. They’re “the system still reasons when the document is absurdly large” scores. For Qwen Long, that’s the point.
6. Qwen Long vs RAG: Why Architecture Matters
RAG is great when the answer is local. Retrieve, rerank, summarize, ship.
The failure mode is global questions. Not “find clause 12,” but “explain how clause 12 changed over time and what it implies.” Those prompts require a stable, evolving internal state, not just top-k passages.
Qwen Long tackles this class by design. The memory agent framework learns compression plus planning as it reads, which is closer to how humans handle long documents: notes, revisions, and an evolving hypothesis.
My rule of thumb:
- If your users ask, “Where is the answer?”, RAG is enough.
- If your users ask, “What is the story?”, Qwen Long is the kind of tool you test.
7. Hands-On Guide: Running Qwen Long L1.5 Locally
If you want local control, this is where Qwen Long shines. You can keep sensitive corpora on-prem, and you can iterate without sending a million tokens to someone else’s server.
If you’re searching for weights and quick starts, Qwen Long HuggingFace is the query you want, and the model name you’ll see in code is typically Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B.
7.1 Minimal Setup
$ conda create -n qwenlongl1_5 python==3.10 $ conda activate qwenlongl1_5 $ pip3 install -r requirements.txt $ git clone --branch v0.4 https://github.com/volcengine/verl.git $ cd verl $ pip3 install -e .
7.2 Load The Model
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto", )
8. Inference Code: Implementing The Memory Agent
You do not need a fancy wrapper to start. Keep a plain template, then implement the loop that updates memory chunk by chunk.
template = '''Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as: "Therefore, the answer is (insert answer here)".'''Then, for a first pass, run normal generation and parse the <think> block if you want to inspect reasoning.
prompt = template.replace("$DOC$", context.strip()).replace("$Q$", question.strip()) messages = [{"role": "user", "content": prompt}] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) generated_ids = model.generate(**model_inputs, max_new_tokens=50000, temperature=0.7, top_p=0.95) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() try: end_think = len(output_ids) - output_ids[::-1].index(151668) except ValueError: end_think = 0 thinking = tokenizer.decode(output_ids[:end_think], skip_special_tokens=True).strip() answer = tokenizer.decode(output_ids[end_think:], skip_special_tokens=True).strip
To make it a true memory agent, wrap generation in your chunk loop, feed in the current chunk plus the current memory, and update memory at every step. The paper’s formulation gives the shape of that loop and the role of planning.
9. Performance And Limitations: What You Trade For 4M
Qwen Long buys reach with sequential compute.
A single 120K pass is heavy. A million-token job is multiple passes, plus tokens spent on memory updates and plans. This is why long context LLM performance is not just “tokens per second,” it’s “tokens per answer under a real workflow.”
The training pipeline also explains the model’s behavior. The authors progressively extend length over multiple full-context RL stages, train a specialized memory-RL expert, merge it back with SCE, and then run a final full-context RL stage.
Here’s the post-training pipeline from Figure 6, rewritten as a quick reference.
Qwen Long L1.5 Post-Training Stages And Limits
A compact view of training stages, modes, and key limits for the Qwen Long L1.5 recipe.
| Stage | Training Mode | Key Limits / Settings |
|---|---|---|
| Stage 1 | Full-Context RL | Max Input 32K, Max Output 12K |
| Stage 2 | Full-Context RL | Max Input 60K, Max Output 20K |
| Stage 3 | Full-Context RL | Max Input 120K, Max Output 50K |
| Memory Expert | Memory-RL | Max Input 128K, Chunk Size 32K, Memory Size 15K |
| Stage 4 | Full-Context RL | Max Input 120K, Max Output 50K |
Source: Figure 6 in the technical report.
That “memory expert then merge” choice is a nice tell. It says the team saw instability when mixing memory and full-context training, so they isolated the skills, then fused them.
Finally, the paper reports that stronger long-context training transfers to other areas, including agentic memory tasks and long dialogue memory benchmarks.
10. Privacy And Local Control
There’s a simple reason enterprises like an open-source long context LLM. They can run it where the data lives.
With Qwen Long, the memory agent loop is just code you control. That helps with governance, auditability, and the obvious practical point that you do not want to upload huge internal corpora to external services.
11. Blueprint For Future Context Scaling
Qwen Long is less a single model and more a recipe you can copy.
Synthesize data that requires long context reasoning, stabilize RL with task-aware tricks, add entropy control so training does not collapse, then train memory management as a first-class skill instead of a prompt hack.
That’s the direction I expect the field to keep moving: smarter memory, not just bigger windows.
12. Conclusion: What To Do Next If You Build With Long Context
If your workload is mostly search, keep RAG and spend your time on retrieval quality. If your workload is document-level understanding, test Qwen Long.
Download it, pick one painful internal task, and run a disciplined evaluation. Start with 32K to 120K documents, then climb. Measure latency, failure modes, and whether the model can keep a coherent story when evidence is scattered. That’s the real bar for long context reasoning.
If it clears that bar, Qwen Long is not a novelty. It’s a practical long context LLM you can build on, and a very clear signal that “4M context” can be an engineering system, not a marketing line.
What is Qwen Long L1.5 and how does the Memory Agent work?
Qwen Long L1.5 is a long-context reasoning model that handles ultra-long inputs by processing documents in chunks and updating a compact memory state step by step. The loop is simple: decompose the request, chunk and read sequentially, then update memory so later steps “remember” earlier evidence without reloading everything.
How does Qwen Long compare to DeepSeek R1 and Gemini 2.5 Pro?
On long-context benchmarks, Qwen Long is competitive with flagship systems, with a headline MRCR score around 83 and a strong overall average in the reported suite. In practical terms, it’s one of the few open releases that can credibly claim “flagship-adjacent” long-context reasoning rather than just long-context retrieval.
Can I run Qwen Long L1.5 locally using llama.cpp?
Yes, if you use a GGUF-converted build and a llama.cpp version that supports the Qwen3/Qwen3MoE family, Qwen Long can run locally like other Qwen3-based checkpoints. One warning from early testers: Q4 quants may trigger “thinking loops”, so start with higher precision (Q8/FP16) if you want stable reasoning.
What is the difference between a long context LLM and RAG?
A long context LLM tries to reason across the full narrative of what you feed it (timelines, dependencies, cross-chapter logic). RAG retrieves snippets that look relevant, which is great for lookup but often misses “global” questions like how an argument evolves across a 500-page document. Qwen Long’s Memory Agent is designed for that global stitching job.
Does Qwen Long support 4 million tokens natively?
Not as a single, raw attention window. The idea is: a native context window (reported at 256K) plus a Memory Agent framework that extends effective reasoning to 1M–4M tokens by reading sequentially and compressing what matters into memory updates. That distinction is exactly what makes it usable on real hardware.