

Introduction
I like cloud models. I like my GPU bill even more. For years, “run a big model locally” came with a cruel joke. You either got speed that felt a little shallow, or you got brains that moved like molasses. Nemotron 3 Nano is one of the first open releases in a while that makes that trade feel optional.
The Technical Report lays out the core trick: a Mixture-of-Experts hybrid Mamba-Transformer that totals 31.6B parameters, but activates about 3.2B per forward pass, 3.6B including embeddings. Sparse activation is why Nemotron 3 Nano can feel “large” without running “large” on every token.
If your goal is a Local LLM Agent that does real work on your own hardware, this is the model worth your weekend.
Table of Contents
1. The “Local God Mode” Unlock: Why Nemotron 3 Nano Changes The Game
Some launches are about a new leaderboard. This one is about changing what a single GPU can carry.
NVIDIA’s own throughput measurement, on a single H200 with an 8K input and 16K output setup, shows Nemotron 3 Nano delivering 3.3× higher throughput than Qwen3-30B-A3B-Thinking-2507 and 2.2× higher than GPT-OSS-20B. That’s the kind of gain that matters when you’re running many agents in parallel, or one agent that produces a lot of text.
1.1. What “Nano” Really Means
“Nano” does not mean small. It means sparse.
Nemotron 3 Nano totals 31.6B parameters, but uses a learnt MLP router that activates 6 of 128 experts per token. That’s the MoE bargain. You pay for a handful of experts each step, not the whole brain.
This is also why Nemotron vs Qwen 30B is a fair fight. Both play the sparse A3B game. Only one of them is built to sprint.
1.2. The Long-Context Claim That Survives Contact With Reality
Marketing loves long context. Engineering hates long context. NVIDIA Nemotron 3 Nano supports context lengths up to 1M tokens, and the report shows it outperforming Qwen in RULER at long lengths. In Figure 1, the RULER @ 1M accuracy listed for Nemotron 3 Nano is 86.3.
If you’ve tried to build agents, you know why this matters. Long context is not for bragging rights. It’s for not losing the plot halfway through a multi-step job.
2. Decoding The Architecture: Mamba LLM Meets Mixture Of Experts
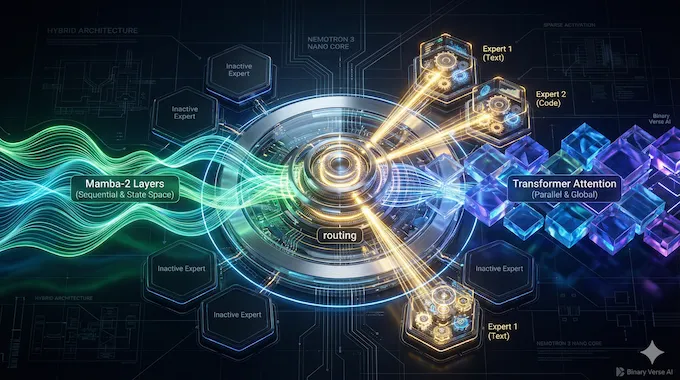
Most performance stories are a pile of tricks. This one starts with the backbone.
Nemotron 3 Nano mixes Mamba-2 layers with Transformer attention, specifically Grouped-Query Attention (GQA), then swaps the usual dense feed-forward blocks for MoE layers. If you’ve been seeing “Mamba LLM” everywhere, this is a concrete, shipping example of why the idea is attractive for agent workloads.
2.1. Why Mamba Helps When Agents Get Verbose
Transformers tend to get bandwidth-bound under long generations. Mamba-2 is a different set of tradeoffs that can keep token flow steadier when the output is big. Mix the two, and you get a model that can reason with attention while still moving fast when the agent starts writing.
2.2. The MoE Bits That Actually Matter
The report’s numbers are the mental model.
Spec Table
Nemotron 3 Nano Specs That Matter
A quick, readable view of the core design choices behind Nemotron 3 Nano, optimized for mobile scanning.
| Spec | Value | Why You Should Care |
|---|---|---|
| Total parameters |
31.6B | Capacity without going “giant”. |
| Active parameters (per forward pass) |
3.2B (3.6B incl. embeddings) | Sparse compute, cheaper tokens. |
| Backbone |
Hybrid Mamba-2 + Transformer (GQA) | Better throughput under long outputs. |
| Routable experts |
128 | Room for specialization. |
| Experts activated |
6 (plus 2 shared) | MoE efficiency per token. |
| Layers |
52 | Depth for reasoning and tool use. |
| Max context length |
Up to 1M tokens | Big memory for agent workflows. |
That table is the “Nano paradox.” Nano is big where it counts, light where it hurts.
3. Nemotron 3 Nano Benchmarks: Speed Vs Accuracy
Benchmarks don’t ship products, but they do reveal the shape of a model.
Figure 1 in the report compares Nemotron 3 Nano, Qwen3-30B-A3B-Thinking-2507, and GPT-OSS-20B across chat, math, instruction following, tool use, coding, long context, plus a throughput test. It’s not a “one weird trick” win. The pattern is consistent: competitive accuracy, much higher throughput.
Benchmark Table
Nemotron 3 Nano Benchmarks vs Qwen 30B and GPT-OSS
Accuracy, tool use, long-context performance, and throughput in one scan-friendly table. Percent values include subtle progress bars.
| Metric | Category | Nemotron-3-Nano-30B-A3B | Qwen3-30B-A3B-Thinking-2507 | GPT-OSS-20B-A4B |
|---|---|---|---|---|
| Arena-Hard-v2-Avg | Chat (Accuracy %) |
67.7% |
57.8% |
48.5% |
| AIME25 | Math (Accuracy %) |
99.2% (+tools) / 89.1% |
85.0% |
98.7% (+tools) / 91.7% |
| IFBench | Inst. Following (Accuracy %) |
71.5% |
51.0% |
65.0% |
| τ²-Bench | Tool Use (Accuracy %) |
49.0% |
47.7% |
47.5% |
| SWE-Bench | Coding (Accuracy %) |
38.8% |
22.0% |
34.0% |
| LCB v6 | Coding (Accuracy %) |
68.2% |
66.0% |
61.0% |
| RULER @ 1M | Long Ctx (Accuracy %) |
86.3% |
77.5% |
N/A |
| ISL/OSL 8k/16k | Relative Throughput (Output tokens/s/GPU) |
3.3 |
1.0 |
1.5 |
One more detail matters if you care about real deployments. NVIDIA measured throughput on a single H200 with vLLM and TRT-LLM, taking the best result per model, and used FP8 for weights and activations for Nano and Qwen. That’s a grown-up measurement.
4. Hardware Requirements: Can Your GPU Run It?

Let’s talk about the thing you actually want to know: can you run 30B model locally without turning your setup into a science project?
If you have 24GB VRAM, you’re in the comfort zone. With a solid 4-bit GGUF, Nemotron 3 Nano becomes a practical daily driver on RTX 3090 or 4090 class cards.
4.1. The 24GB VRAM “Just Works” Setup
Start in the Q4 neighborhood, often Q4_K_M or IQ4_XS depending on what’s available. That usually fits, leaves some room for cache, and keeps speed high enough for agent loops.
Plan storage too. Even a 4-bit build can land around the low 20GB range once you include embeddings and practical packaging.
4.2. 12GB And 16GB: Offload, Then Be Disciplined
On 12GB or 16GB, you can still run 30B model locally, but you’ll offload to system RAM. Keep your context sensible, keep your tool schemas tight, and don’t expect miracles. For a Local LLM Agent that mostly writes and plans, it can still feel surprisingly usable.
4.3. What The Report Teaches You About Quantization Pain
In the report’s FP8 PTQ section, NVIDIA notes a selective approach that keeps the most sensitive attention layers, and the Mamba layers feeding into them, in BF16.
Translate that into local life: if you quantize aggressively and code starts dropping brackets or math gets sloppy, you’re stepping on sensitive parts. Move up a quant, or reduce context, before you blame the model.
4.4. A Simple Local Sanity Checklist
Before you judge any local run, make sure the basics are boring and correct:
- Keep context under control at first. Start small, then scale up. A giant context can mask a bad quant, or a bad prompt.
- Watch KV cache pressure. If performance suddenly falls off a cliff, you’re usually paging memory, not “hitting a model limit.”
- Measure on your workload. One coding repo, one set of tools, one agent loop. If it feels good there, you can generalize later.
This sounds obvious. It’s also the difference between “this model is amazing” and “why is my GPU crying.”
5. Installation Guide: Using Unsloth GGUF And Ollama
This section is intentionally boring. Boring is what you want from deployment.
5.1. Grab The Unsloth GGUF Build
- Find the Unsloth GGUF collection on Hugging Face.
- Pick your quant. For 24GB, start with Q4. For more accuracy, move to Q5 or Q6 if your VRAM allows it.
- Download, then hash-check if you care about reproducibility.
5.2. Run Nemotron 3 Nano With Ollama
Once it’s in Ollama, the workflow is simple.
ollama run nemotron-nano
Use a conservative temperature at first. Agents love to improvise. Your logs will not.
5.3. LM Studio: One Checkbox That Matters
In LM Studio, enable the option that offloads as much as possible to the GPU, often labeled like “offload all layers.” If you’re doing partial offload, tune it until you stop thrashing PCIe.
6. The Agentic Capabilities: 1M Context And Reasoning
Agents fail in predictable ways. They forget. They ramble. They call tools like a nervous tic.
Nemotron 3 Nano was trained to push against those failure modes, not just to chat well.
6.1. Treat 1M Context Like Memory, Not A Dumpster
Yes, the model supports 1M tokens, and the report backs that up with long-context evaluation. The win is not stuffing “everything” into the prompt. The win is keeping a persistent working set: the repo you’re editing, the incident timeline, the spec you’re arguing with, the test logs you keep revisiting.
That’s the difference between a fast chatbot and a stable Local LLM Agent.
6.2. Reasoning On, Reasoning Off, And A Budget Dial
During post-training, NVIDIA says they trained on chat, agentic, and reasoning traces to build reasoning on and off control plus reasoning budget control, and they used SFT, RLVR, and RLHF as the three post-training stages.
This is the feature I want in every model going forward. You don’t want maximum thinking all the time. You want controllable thinking.
6.3. Tool Use And Tool Hallucination
The report defines tool hallucination as the model attempting to invoke a tool when no tools were declared in the system message.
If you remember one rule from this post, make it this: your system message is a contract. Declare tools only when you mean it. Don’t give the model ambiguous permission and then get surprised when it takes it.
7. Beyond Chat: NVIDIA NeMo Gym And RLVR
Nemotron 3 Nano is not just weights. It’s also a stance on how to make agents reliable. NVIDIA describes Nemo-Gym as the environment framework used for RLVR, and Nemo-RL as the RL training framework, and they state they open source both to enable large-scale RL training and community environment building.
That’s a big deal. RL infrastructure has been a private club for years. NVIDIA NeMo Gym is an attempt to make the club less exclusive.
7.1. Why RLVR Fits Agent Work
RLVR is reinforcement learning where rewards are verifiable. That maps cleanly to agent tasks: code that compiles, JSON that validates, schedules that don’t conflict, tool outputs that match schemas.
The report also notes that training across all environments simultaneously aims for smoother, more uniform improvements. If you’ve ever watched a model get better at one benchmark while getting worse at your workload, you already know why that matters.
8. Potential Drawbacks And Gotchas
Nemotron 3 Nano is impressive. It’s not frictionless.
8.1. Tool Hallucinations Are A Real Failure Mode
NVIDIA calls it out and defines it precisely. Your fix is procedural: test “no tools” prompts, enforce strict tool schemas, and log every tool attempt.
8.2. Quantization Can Turn Confidence Into Fiction
The report’s selective quantization note is the hint. If you want speed, don’t blindly chase the smallest file. Pick a quant that preserves code and math stability for your use case.
8.3. Corporate Defaults Exist For A Reason
Expect safety rails and conservative behavior. If you need agentic AI more permissive, do it deliberately, and put guardrails in your app, not in your hopes.
9. Conclusion: The New Daily Driver For Local AI
If you have 24GB VRAM, you can stop treating local agents like a novelty. Nemotron 3 Nano is fast in the scenario that matters, generation-heavy workloads, and it stays competitive on tool use, coding, and long-context evaluation. That combination is rare.
So here’s the CTA: download a good Unsloth GGUF, run Nemotron 3 Nano on a real task from your week, and measure what matters. Tokens per second. Tool-call reliability. How often it forgets the plan. How often it invents a tool.
Then share the results. Post your settings. Post your failures. The fastest way to make Nemotron 3 Nano better is to treat it like software, and test it like software.
Why Is It Called “Nano” If It Has 30B Parameters?
Nemotron 3 Nano is “Nano” because it runs like a smaller model at inference time. It has 31.6B total parameters, but only 3.2B active per forward pass (about 3.6B including embeddings) thanks to its Mixture-of-Experts routing.
Can I Run Nemotron 3 Nano On A Single RTX 3090 Or 4090 (24GB VRAM)?
Yes. With 4-bit quantization (GGUF builds such as Unsloth GGUF), Nemotron 3 Nano is designed to be runnable on 24GB RAM/VRAM-class setups, which includes RTX 3090 and 4090. Your usable context size depends on quant, KV cache, and settings.
How Does Nemotron 3 Nano Compare To Qwen 30B And GPT-OSS?
On NVIDIA’s reported tests, Nemotron 3 Nano delivers 3.3× throughput vs Qwen3-30B-A3B (and 2.2× vs GPT-OSS-20B) in the cited configuration. In the same comparison table, it posts AIME25 99.2% (+tools) vs GPT-OSS 98.7% (+tools) and LCB v6 68.2% vs Qwen 66.0% and GPT-OSS 61.0%.
Does Nemotron 3 Nano Support Long Context (1M Tokens)?
Yes. Nemotron 3 Nano supports up to 1M tokens. In the technical report’s comparison, it also scores 86.3% on RULER @ 1M, which helps validate that it can retrieve and use information at long context lengths, not just accept the tokens.
What Is The Difference Between “Reasoning ON” And “Reasoning OFF” Modes?
Reasoning ON is meant for multi-step thinking on harder tasks (math, code, tool planning) and can be paired with a thinking budget to control cost and verbosity. Reasoning OFF is optimized for faster, more concise chat-style responses where you do not want long internal deliberation.