

1. Introduction
There is a number floating around the industry that feels almost magical. You have likely seen it cited in slide decks or enthusiastic Twitter threads. The claim is that between 2012 and 2023, AI efficiency improved by a factor of 22,000.
Let that sink in for a second. If internal combustion engines improved at that rate, you could drive your Honda Civic to the moon on a teaspoon of gas. The narrative suggests that we, the clever engineers and researchers, have written code so brilliant that we have unlocked orders of magnitude in performance purely through software innovation. It paints a picture of a meritocratic explosion of intellect.
But if you have been in the trenches training models, that number might feel wrong. It feels like we are mostly just burning more coal.
A fascinating new paper out of MIT, On the Origin of Algorithmic Progress in AI, decides to pop the bubble. The researchers took a look under the hood of this “22,000x” figure and found something stark. When you strip away the massive increase in compute budgets and look strictly at the code, the actual algorithmic progress, the gains are not 22,000x. For most innovations, they are barely 10x.
We need to talk about where AI efficiency actually comes from. It turns out we aren’t getting smarter at coding as fast as we think. We are just getting much better at spending energy.
Table of Contents
2. The “22,000x” Claim vs. Reality: Deconstructing Algorithmic Progress

The prevailing wisdom, championed by previous studies like Ho et al. (2024), is that we are witnessing a software revolution. The logic goes that because we can train a model to a certain loss threshold today with fewer FLOPs than we could in 2012, the difference must be algorithmic brilliance.
The MIT team decided to test this by doing something painfully tedious but scientifically necessary. They ran ablation studies. They took a modern Transformer and started stripping away the “innovations” one by one to see how much AI efficiency each specific tweak actually contributed.
They looked at the darlings of the research papers: SwiGLU activation functions, Rotary Embeddings (RoPE), RMSNorm, and AdamW optimizers. If the 22,000x number were true, you would expect these components to be doing heavy lifting. Here is what they found.
The individual contributions of these famous tweaks are shockingly small. SwiGLU offers about a 1.2x gain over GeLU. Rotary embeddings give you maybe 1.4x over sinusoidal ones. Learning rate schedules? The difference between cosine decay and the old-school inverse square root is negligible—less than 5%.
When you stack all these “scale-invariant” improvements together, they don’t compound into a revolution. They add up to a modest efficiency bump. The researchers estimate that the sum total of these tweak-based AI efficiency gains is less than 10x.
Below is a look at the actual multipliers the researchers found when isolating these variables on a 3.6M parameter model.
Breakdown of AI Efficiency Gains
| Improvement Type | Comparison | Estimated Multiplier (Efficiency Gain) |
|---|---|---|
| Optimizer | AdamW vs. Adam | |
| Schedule | Cosine vs. Inverse Sqrt | |
| Schedule | Cosine vs. Linear Decay | |
| Norm Layer | RMSNorm vs. LayerNorm | |
| Activation | SwiGLU vs. GeLU | |
| Positional Enc | Rotary vs. Learned | |
| Positional Enc | Rotary vs. Sinusoidal | |
| Optimizer | Adam vs. SGD (Batch size 64) | |
| Architecture | Modern Transformer vs. LSTM |
Note: The hatched bar in the original paper for the Transformer vs. LSTM comparison indicates this specific gain is scale-dependent, which we will discuss shortly.
The data is humbling. We spent years writing papers about activation functions, and while they help, they aren’t the reason GPT-4 exists. The math says we aren’t coding 22,000x better. We are mostly just stacking marginal gains.
3. The Secret Ingredient: Scale-Dependent Efficiency

If individual algorithms are only giving us small boosts, where is the rest of the AI efficiency coming from? This is where the paper introduces a concept that should change how we think about ML engineering: Scale-Dependent Efficiency.
Usually, we assume an algorithm is just “better.” If Quicksort is faster than Bubble Sort, it is faster whether you are sorting 10 numbers or 10 billion. But in deep learning, that intuition fails.
The MIT researchers found that some algorithms are “scale-invariant.” Their benefit is constant regardless of how much compute you throw at them. Switching to RMSNorm is a nice little boost, but it is the same boost for a tiny startup as it is for Google.
But other innovations, specifically the shift to Transformer architectures, behave differently. Their AI efficiency curve is not flat. It tilts. The more compute you use, the more efficient they become relative to the baseline.
This explains the discrepancy. If you measure AI efficiency at a small scale (like the 10^15 FLOPs used for early experiments), the difference between a Transformer and an old-school LSTM is only about 6x to 8x. It is noticeable but not earth-shattering.
But if you extrapolate that out to the “compute frontier”, the massive scale where models like Gemini or Claude live (10^23 FLOPs), that gap widens. The Transformer allows you to effectively use compute that the LSTM would choke on. The efficiency gain isn’t static. It grows as your budget grows.
This reveals a somewhat uncomfortable truth. We haven’t necessarily cracked the code of intelligence. We have found a specific architecture that stops being the bottleneck for AI hardware.
4. Transformers vs. LSTMs: Why the “Best” Tech Requires Brute Force
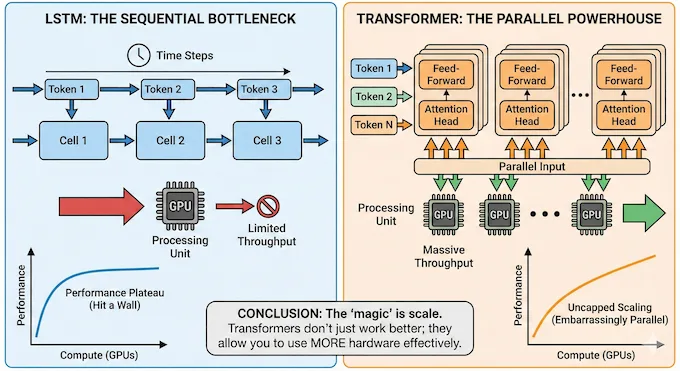
Let’s dig into the graveyard of architectures. Do you remember LSTMs? Long Short-Term Memory networks were the kings of NLP before 2017. They were clever. They were recurrent. And they are now extinct at the frontier.
The standard narrative is that Transformers are just smarter. They have attention mechanisms. They “understand” context better.
The paper argues something more pragmatic. The AI efficiency of a Transformer relative to an LSTM is tied entirely to scale.
The researchers ran a massive scaling experiment. They trained both LSTMs and Transformers across orders of magnitude of compute. At the low end, the loss curves were close. You could actually build a decent chatbot with an LSTM if you kept it small.
But as they cranked up the compute dial, the LSTM hit a wall. Recurrent networks process tokens sequentially. They are hard to parallelize. You can buy all the GPUs in the world, but you cannot force an LSTM to ingest data faster than its recurrent step allows.
Transformers are different. They are embarrassingly parallel. They let you throw AI hardware at the problem until the problem submits.
The findings suggest that the Transformer architecture accounts for the vast majority of historical gains, but only because we increased the compute supply. If we had stayed at 2012 hardware levels, the Transformer would essentially be a slightly quirky, slightly better alternative to the LSTM, offering maybe a 6x improvement.
It is the scale that creates the magic. The algorithm didn’t get 22,000x better on its own. It just unlocked the door for us to use 22,000x more compute effectively.
5. AI Scaling Laws: The Shift from Kaplan to Chinchilla
There is one other major source of AI efficiency identified in the paper, and it has nothing to do with architecture and everything to do with resource management.
For a long time, the industry followed the “Kaplan” scaling laws. The original OpenAI paper on AI scaling laws suggested that as you get more compute, you should mostly just make the model bigger. Parameter count was king. Data was secondary.
Then came the “Chinchilla” paper from DeepMind in 2022. They realized we were doing it wrong. It turned out we were starving giant models of data. The Chinchilla scaling laws proved that for optimal AI efficiency, you need to scale parameters and training tokens equally.
The MIT paper identifies this “Chinchilla Rebalancing” as the second massive contributor to progress. By simply correcting the ratio of model size to data size, we unlocked a massive one-time gain in efficiency.
This wasn’t a new neural network design. It was a logistical correction. We stopped building Ferrari engines and putting them in go-karts. We matched the engine to the fuel tank.
Between the scale-dependent gains of the Transformer and the Chinchilla rebalancing, the paper accounts for about 91% of the total AI efficiency gains at the frontier. Everything else, all the fancy optimizers, the activation functions, the normalization layers, is just noise in the margins.
6. The “Punctuated Equilibrium”: Why Progress Isn’t Smooth
We tend to visualize progress as a smooth, exponential curve up and to the right. We think of Moore’s Law, where things just get twice as good every two years like clockwork.
This paper suggests algorithmic progress in AI is actually a “punctuated equilibrium.” This is a term from evolutionary biology. It means long periods of boredom interrupted by sudden, violent change.
For years, AI efficiency gains are incremental. We find a better optimizer. We tweak a learning rate. We get 1.1x here, 1.05x there. Then, boom. We invent the Transformer. Suddenly, the curve snaps upward, but only if you have the compute to ride it. Then we spend years optimizing that paradigm until the next explosion.
This has a sobering implication for the current moment. Are we currently in the “boring” phase? We have optimized the Transformer to death. We have fixed our scaling ratios. Unless there is another Transformer-level architectural shift hiding in a purely academic paper somewhere, we might be approaching a plateau where AI efficiency gains slow down significantly.
We cannot optimize our way out of a plateau. We have to invent our way out.
7. Hardware vs. Software: Is Moore’s Law Doing the Heavy Lifting?
This brings us to the hardware in the room. If algorithms are only contributing a small slice of the pie for everyone except the giants, what is driving the feeling of progress for the average developer? It is Moore’s Law in AI. Or rather, Jensen’s Law.
For small-scale model builders, the researchers, the startups, the hobbyists, algorithmic progress has been far slower than previously assumed. If you are training small models, the switch from LSTM to Transformer didn’t give you a 22,000x boost. It gave you a 6x boost.
The reason your models feel 100x faster today than in 2016 is mostly because AI hardware got better. The GPUs have more VRAM. The tensor cores are faster. The memory bandwidth is higher.
The paper makes a critical distinction: AI efficiency gains from algorithms are “reference-dependent.” If you reference a massive frontier model, software looks like the hero. If you reference a small model running on a single server, hardware is doing the heavy lifting.
We like to pat ourselves on the back for our clever code. But we should probably send a thank you card to the semiconductor engineers. They are the ones actually keeping the lights on for the little guy.
8. The Inequality of AI Efficiency: Big Tech vs. The Rest

Here is the most sociologically important finding of the paper. Because the primary driver of AI efficiency (the Transformer) is scale-dependent, progress is not distributed equally.
If I am a solo developer and I adopt the Transformer architecture, I get a small efficiency bump. If Google adopts the Transformer architecture and throws a billion dollars of compute at it, they get a massive efficiency bump.
The architecture inherently favors those with deep pockets. AI efficiency is acting like compound interest, where the wealthy get a higher interest rate than the poor.
This challenges the idea of “democratizing AI.” Open-source models are great, but if the fundamental algorithms work significantly better at scales that only three companies can afford, the gap between the frontier and the rest of us will not shrink. It will widen. The physics of the current paradigm ensures that the big players get more value per dollar of compute than the small players do.
9. Conclusion: What Happens When We Hit the “Scaling Wall”?
The MIT paper forces us to confront a reality we have been ignoring. We haven’t been witnessing a miracle of software engineering. We have been witnessing a miracle of scaling. We found an architecture that didn’t break when we poured oceans of energy into it, and we corrected our math on how much data to feed it.
That accounts for the “22,000x” AI efficiency claim. It wasn’t 22,000 clever tricks. It was two big tricks and a lot of brute force.
So what happens next? AI scaling laws eventually hit physical limits. We run out of high-quality text data. We run out of power grids capable of supporting gigawatt-scale clusters. We run out of money.
If AI efficiency is tied to scale, and scale hits a wall, progress stops.
The path forward isn’t to build a bigger Transformer. The path forward is to find the next discontinuity. We need algorithmic progress that is scale-invariant, innovations that make models smarter without requiring them to be larger. We need to look back at the 10x gains we ignored because they didn’t scale well, and see if there is brilliance hiding in the discarded ideas.
We need to stop relying on the engine to get bigger and start figuring out how to make the car drive better.
Would you like me to analyze the specific “Retro vs. Modern” Transformer hyperparameters from the paper to see which specific tweaks might be worth keeping for your own smaller-scale experiments?
Does AI actually increase efficiency, or is it just using more power?
Recent research from MIT indicates that while algorithms have improved, roughly 90% of the “efficiency” gains at the frontier come from scaling up hardware (brute force) rather than clever coding tricks. At small scales, the algorithmic efficiency gain is closer to 6x, not the reported 22,000x.
What are AI scaling laws and why do they matter?
Scaling laws dictate the optimal ratio of compute, data, and model size. The paper highlights the shift from “Kaplan scaling” (which emphasized model size) to “Chinchilla scaling” (which balanced training data with size) as one of the few genuine efficiency jumps in the last decade.
Is AI progress slowing down according to new research?
The paper suggests progress follows a “punctuated equilibrium” rather than a smooth exponential curve. We experience long plateaus of minor tweaks (like activation functions) interrupted by rare, explosive architectural shifts (like the Transformer).
What is the difference between Scale-Dependent and Scale-Invariant algorithms?
Scale-Invariant algorithms (like RMSNorm) provide the same small benefit regardless of model size. Scale-Dependent algorithms (like Transformers) only significantly outperform older methods (like LSTMs) when you train them with massive amounts of compute.
Is Moore’s Law still relevant to AI efficiency?
Yes, especially for smaller developers. For non-frontier models, hardware improvements (Moore’s Law) have actually contributed more to perceived speed and efficiency than algorithmic breakthroughs over the last decade.