

Introduction
The AI hardware war has shifted while the world wasn’t looking. While the tech media obsessed over chatbots and image generators, a silent arms race for the physical infrastructure of intelligence was escalating in the background. For the last few years, the narrative has been simple: Nvidia owns the shovel store, and everyone else is just digging. But Google has never been content to just dig.
With the quiet deployment of Google Ironwood, the company’s 7th-generation Tensor Processing Unit (TPU v7), the search giant is making a distinct statement. This isn’t just a faster chip. It is a fundamental architectural pivot from “training”, the act of building the brain, to “inference”, the act of using it. Google Ironwood represents a specialized, proprietary attempt to break the cost barriers of running massive models like Gemini at a global scale.
If you are an engineer or a CIO looking at your compute bill, you need to pay attention. The monopoly on high-performance AI compute is cracking, and it’s cracking because of silicon like this.
Table of Contents
2. The Ironwood Architecture: Purpose-Built for the “Age of Inference”
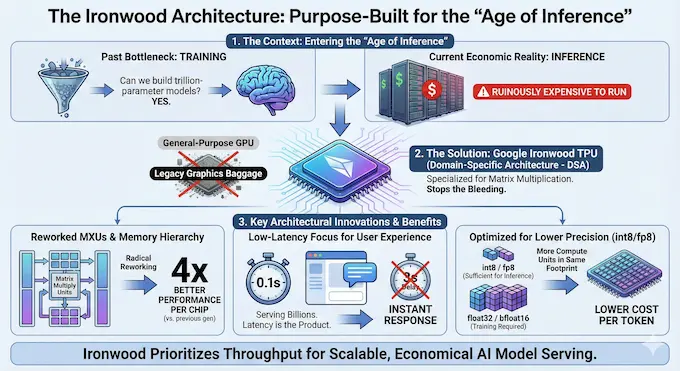
We are entering a new phase of the AI hype cycle. We call it the “Age of Inference.” For years, the bottleneck was training. Can we actually build a model with a trillion parameters? Now that the answer is “yes,” the economic reality has set in. Running these models is ruinously expensive. Google Ironwood is designed specifically to stop the bleeding.
Unlike general-purpose GPUs which carry the baggage of legacy graphics rendering pipelines, the Google TPU architecture has always been a domain-specific architecture (DSA). It does one thing: matrix multiplication. With Ironwood, Google has optimized this further for high-volume, low-latency model serving.
The blog announcement notes a massive “4x better performance per chip” compared to the previous generation. This is not just a clock speed bump. This suggests a radical reworking of the Matrix Multiply Units (MXUs) and the local memory hierarchy. When you are serving a model to billions of users, latency isn’t just a metric; it’s the product. If ChatGPT or Gemini takes three seconds to reply, you close the tab. Google Ironwood is the hardware answer to that latency problem.
The architecture prioritizes throughput for “inference workloads.” This means the chip is likely optimized for lower precision arithmetic (like int8 or fp8) which is sufficient for running models, rather than the high-precision float32/bfloat16 often required for training them. This specialization allows Google to cram more compute units into the same silicon footprint, driving down the cost per token.
3. Breaking the Speed Limit: The 9.6 Tb/s Inter-Chip Interconnect (ICI)
If you take nothing else away from this analysis, remember this acronym: ICI. In the world of AI supercomputing, the individual chip is almost irrelevant. The limiting factor is rarely how fast one chip can think, but how fast it can talk to its neighbor. When you shard a model across a thousand chips, the network becomes the computer.
Google Ironwood introduces a staggering upgrade to the Inter-Chip Interconnect (ICI), now operating at 9.6 terabits per second (Tb/s). To put that number in perspective, that is fast enough to transfer the entire contents of your hard drive in a fraction of a blink. This bandwidth allows Google to link 9,216 chips into a single “Superpod.”
In traditional data centers, servers talk to each other over Ethernet. Ethernet is robust, but it is “chatty” and relatively slow, introducing overhead that kills AI performance. The ICI in Google Ironwood is a direct, dedicated mesh network. It’s a topology that allows these 9,000+ chips to behave as a single, massive brain.
This is where the distinction between “cloud” and “supercomputer” vanishes. In a standard cloud setup, you rent a VM. With Google Ironwood, you are renting a slice of a synchronous mesh. This allows for model parallelism, splitting a single giant neural network across thousands of chips, without the communications bottleneck that usually plagues such setups.
4. Google Ironwood vs. Nvidia Blackwell: The Technical Showdown
So, how does Google Ironwood stack up against the reigning champion, the Nvidia GPU? This is the question burning up Reddit threads and engineering slacks. The comparison isn’t apples-to-apples; it’s more like comparing a Formula 1 car (TPU) to a high-performance rally car (GPU).
Here is the breakdown of Google TPU vs Nvidia GPU in this generation:
4.1 Memory and Bandwidth
The Google Ironwood Superpod boasts 1.77 Petabytes of shared High Bandwidth Memory (HBM). This is the killer stat. Large Language Models (LLMs) are memory-bound. They spend most of their time waiting for data to arrive from memory. By pooling this massive amount of HBM, Google Ironwood allows even the largest future models to reside entirely in high-speed memory, eliminating the need to swap data to slower disk storage.
4.2 Versatility vs. Specialization
Nvidia’s moat is CUDA. It is a flexible, mature software ecosystem that runs everywhere. You can buy a GeForce card for your gaming PC and run the same code that runs on an H100 in a data center.
Google Ironwood does not care about your gaming PC. It is an ASIC (Application Specific Integrated Circuit). It runs XLA (Accelerated Linear Algebra) workloads, primarily via JAX and TensorFlow. It is not designed to be flexible; it is designed to be efficient.
Google TPU v7 wins on efficiency for specific Transformer-based workloads. If you are Google, and you know exactly what models you are running (Gemini, Gemma), you build the chip to fit the model. Nvidia has to build chips that fit everyone’s models. That generalization comes with a silicon tax, transistors spent on features you might not need.
4.3 The Verdict
If you are a researcher needing to try fifty different obscure architectures, Nvidia is still your safe bet. But if you are deploying a proven Transformer model at scale and paying the electric bill, Google Ironwood is looking like the superior economic engine.
5. “Designed by AI for AI”: The Role of AlphaChip

Here is where the story gets meta. Google Ironwood was not entirely designed by human engineers. It was designed by Google’s own AI, known as AlphaChip.
According to a recent addendum in Nature, Google has been using deep reinforcement learning (RL) to generate superhuman chip layouts. Chip floorplanning, the game of Tetris where you figure out where to place memory and logic blocks on silicon, is incredibly complex.
AlphaChip treats this problem as a game. It is “pre-trained” on a variety of chip blocks, learning the relationships between placement, wire length, and congestion. It gets better and faster the more chips it designs.
This is a recursive loop. The AI (running on TPUs) designs a better TPU. That better TPU runs the AI faster, which designs an even better TPU.
“Unlike prior approaches, AlphaChip is a learning-based method… This pre-training significantly improves its speed, reliability, and placement quality.”
For Google Ironwood, this means the physical layout of the silicon itself is optimized in ways human engineers might not have intuited. The result is lower wirelength, better timing, and reduced power consumption. While competitors are using standard EDA tools, Google is using a proprietary RL agent that has “played” the game of chip design thousands of times before the project even started.
6. Pricing and Availability: Can You Actually Buy Ironwood?
Here is the catch. You cannot go to Newegg and buy a Google Ironwood card. You can’t even buy a server with one inside.
Google Ironwood is available exclusively via Google Cloud. This is a “Hardware as a Service” model.
When we look at Google TPU price structures, we see a focus on “chip-hours.” While the specific pricing for the v7 (Ironwood) generally follows the tiers set by its predecessors like Trillium and v5p, the value proposition is different.
6.1 Google TPU Pricing Tiers (Estimates based on current generation):
Google Ironwood Context: Predecessor Pricing Models
| TPU Generation | Region | Spot Price (per chip/hr) | On-Demand (per chip/hr) |
|---|---|---|---|
| Trillium (v6) | US-East | ~$1.89 | $2.70 |
| TPU v5p | US-East | ~$2.94 | $4.20 |
| TPU v5e | US-Central | ~$0.84 | $1.20 |
Note: Ironwood pricing will likely premiere at a premium before settling, but the efficiency gains (4x performance) mean your “price per token” effectively drops.
For a startup, this is compelling. Buying an Nvidia H100 cluster requires millions in upfront CAPEX and a 52-week lead time. Accessing Google Cloud Ironwood requires a credit card and an API call.
By controlling the entire stack, from the cooling fluid in the data center to the compiler (XLA) to the chip architecture, Google can offer price-performance ratios that merchant silicon vendors struggle to match. They don’t need to make a profit on the chip sale; they make a profit on the cloud service.
7. Addressing the Skepticism: Is This an “Nvidia Killer”?
If you browse the technical forums, the skepticism regarding Google Ironwood usually centers on the “Walled Garden” problem. “But can it run PyTorch?”
Yes, it can. PyTorch/XLA has matured significantly. But let’s be honest: the experience is not as seamless as CUDA. When you use Google TPU v7, you are stepping into Google’s world. You are optimizing for their topology.
Is it an Nvidia killer? No. Nvidia will continue to dominate the enterprise market, the gaming market, and the research labs that value maximum flexibility.
But for the “Hyperscalers”, and the companies building atop them, Google Ironwood proves that Nvidia is not invincible. It proves that vertical integration wins at scale. If you are training a model that costs $100 million to run, and Ironwood can do it for $70 million because of that 4x inference efficiency and 9.6 Tb/s interconnect, you stop caring about CUDA real fast.
8. Conclusion: The 900lb Gorilla Has Entered the Chat
The launch of Google Ironwood is a warning shot. It signals that the era of general-purpose GPUs dominating the highest tiers of AI compute might be drawing to a close.
We are moving toward a bifurcated world. On one side, versatile GPUs for development and smaller-scale deployment. On the other, massive, purpose-built “AI Supercomputers” like Ironwood for the heavy lifting of foundation models.
Google Ironwood is a beast. It is fast, it is surprisingly cost-efficient, and it was designed by its own grandfather (AlphaChip). For developers deep in the Google Cloud ecosystem, this is a massive unlock. For everyone else, it’s a sign that the hardware wars are just getting started.
If you are building the future of AI, you can’t afford to ignore the silicon it runs on. Ironwood is here, and it is ready to infer.
For more deep dives into AI architecture and silicon news, keep it locked here at Binary Verse AI.
What is Google’s Ironwood and how does it differ from previous TPUs?
Google Ironwood is the 7th-generation Tensor Processing Unit (TPU v7), purpose-built to prioritize “inference” (running models) over just training. Unlike previous generations like Trillium (v6e) or v5p, Ironwood delivers a massive 4x performance improvement per chip and is optimized for low-latency, high-volume model serving. It represents a strategic shift towards energy efficiency and total cost of ownership for deploying massive models like Gemini.
Are Google’s new Ironwood TPUs available for purchase or just cloud access?
Google Ironwood TPUs are not available for purchase as physical hardware. The business model is strictly “Hardware as a Service,” meaning customers can only access Ironwood via Google Cloud Platform (GCP). This differs from Nvidia, which sells GPUs directly to enterprises, and creates a “walled garden” where users must rent the chips by the hour rather than owning the infrastructure.
How does the Ironwood TPU architecture compare to Nvidia’s Blackwell GPU?
While both chips offer roughly comparable raw compute for AI (approx. 4.6 PFLOPS FP8), they differ fundamentally in philosophy: Ironwood is an ASIC specialized for Google’s specific models (JAX/TensorFlow), while Nvidia’s Blackwell is a versatile GPU supporting the broader CUDA ecosystem. Nvidia wins on flexibility and memory bandwidth (8 TB/s vs 7.4 TB/s), but Ironwood wins on scaling efficiency, connecting 9,216 chips into a single superpod compared to Nvidia’s typical 72-GPU clusters.
What is the “Inter-Chip Interconnect” (ICI) and why is 9.6 Tb/s significant?
The Inter-Chip Interconnect (ICI) is Google’s proprietary mesh networking technology that links TPUs directly, bypassing slow standard networking switches. Ironwood’s ICI operates at 9.6 Tb/s, allowing 9,216 chips to function as a single 42.5-exaflop supercomputer. This massive bandwidth eliminates the data bottlenecks that usually slow down “giant” models, enabling them to access 1.77 Petabytes of shared memory as if it were local.
Is Google Ironwood cheaper than using Nvidia GPUs for AI inference?
While specific hourly rates fluctuate, Ironwood is designed to offer a lower “cost per token” for large-scale inference. Because Ironwood delivers 4x better performance per chip and 2x better performance-per-watt than previous generations, it likely undercuts Nvidia on pure efficiency for specific hyperscale workloads. For startups and enterprises running continuous, high-volume models, this efficiency translates to significantly lower monthly cloud bills compared to renting equivalent Nvidia H100 or Blackwell capacity.