

Introduction
For a while, the industry playbook looked simple. If a model struggles, make it bigger. Add parameters, add GPUs, add invoices. Then we all pretend we “needed” 70B for a task that mostly wanted patience and a tighter feedback loop.
Falcon H1R 7B is a different bet. It’s built around a more honest idea: a smaller model can punch above its weight if you (1) train it on the right kind of reasoning traces and (2) make inference-time “thinking harder” cheaper, especially when you run many solution attempts in parallel.
The technical report frames this as a 7B reasoning model designed to be fast, token-efficient, and accurate under test-time scaling.
If you care about practical reasoning systems, not just leaderboard screenshots, this release is worth your attention.
Table of Contents
1. Falcon H1R 7B In 60 Seconds
Falcon H1R 7B is a decoder-only 7B model trained to do long-form reasoning well, then refined with reinforcement learning to improve correctness and control output length.
It’s also built to run parallel thinking efficiently. That matters because the real-world “reasoning stack” increasingly looks like this: sample many chains, prune the weak ones early, vote or aggregate what’s left, ship the result.
Here’s the quick take.
Falcon H1R 7B Quick Reality Check Table
Fast answers on what it is, who it’s for, and why it matters.
| What You Want To Know | The Short Answer | Why You Should Care |
|---|---|---|
| What is it? | A compact reasoning model tuned for long traces and parallel inference. | 7B models become more viable when they can “think” without burning a hole through your token budget. |
| What’s the hook? | Efficiency under test-time scaling. | If you run 16–512 parallel traces, throughput and pruning matter more than vibes. |
| What does it beat? | Strong math and competitive code and general reasoning for its size. | You can prototype a serious reasoning pipeline without defaulting to 30B+ models. |
| Who is it for? | Engineers building agentic tools, math-heavy workflows, or scalable inference systems. | If your product calls the model many times, efficiency is the feature. |
| Who should wait? | Anyone who needs SWE-bench-style proof, or relies heavily on post-quant scores. | The model can be good and still not be validated the way you want. |
Verdict: Falcon H1R 7B is compelling when you treat it like a backbone for “many tries, filtered fast,” not a single-shot oracle.
2. What’s New: H1R Vs. Falcon H1 Base
2.1 Cold-Start SFT That Actually Trains For Long Thinking
The report describes a supervised fine-tuning stage on curated datasets with long reasoning traces across math, code, and science, plus non-reasoning domains like chat and tool use.
The part I like is that they didn’t pretend “long context” is a checkbox. They trained with a default context length of 36K tokens, with some samples extended up to 48K, and they did it at scale on 256 H100s.
That’s not marketing. That’s commitment.
2.2 RL With GRPO, Tuned For Diversity And Length Control
Then comes reinforcement learning, using GRPO, with choices that clearly aim at exploration and rollout diversity. The final RL setup uses group size 16, temperature 0.85, and a 48K max response length, with KL and entropy terms set to zero in their configuration.
In plain terms, Falcon H1R 7B is trained to handle long reasoning traces without immediately collapsing into rambling, repetitive sludge. That’s harder than it sounds.
3. The Benchmarks Everyone Is Quoting, And What They Measure
Benchmarks are not truth. They’re contracts. You’re agreeing to a task format, a scoring rule, and a set of failure modes. Then you’re optimizing for that.
The report groups evaluation into three buckets:
- Math: AIME24, AIME25, HMMT25, AMO-Bench, MATH500
- Code: LiveCodeBench v6, SciCode, τ²-Telecom, Terminal Bench Hard
- General: GPQA-Diamond, MMLU-Pro, Humanity’s Last Exam, IFBench
They also spell out evaluation settings like number of responses per query and max response lengths, which is a detail many “model launch” posts mysteriously forget.
One more thing I appreciate: they did a contamination analysis and report 0% exact-match contamination for all benchmarks except MMLU-Pro, where it’s “near-zero” in their datasets.
That doesn’t make the results perfect. It does make them easier to take seriously.
4. Scoreboard: Where Falcon H1R 7B Looks Legit
Let’s keep this grounded. Here are the headline numbers the report itself highlights.
Falcon H1R 7B Benchmarks Snapshot
Reported results across math, code, and general evaluations.
| Category | Benchmark | Reported Result |
|---|---|---|
| Math | AIME24 | 88.1% |
| Math | AIME25 | 83.1% |
| Math | HMMT25 | 64.9% |
| Math | AMO-Bench | 36.3% |
| Code | LiveCodeBench v6 | 68.6% |
| General | GPQA-Diamond | 61.3% |
| General | MMLU-Pro | 72.1% |
| General | Humanity’s Last Exam | 11.1 |
| General | IFBench | 53.4% |
Source for the table values: the evaluation tables in the report.
If you only read one thing, read this implication: Falcon H1R 7B is not narrowly tuned to one toy domain. It’s strongly math-leaning, still competitive on code, and not embarrassing on general benchmarks, which is the actual bar for “can I ship with this?”
5. The Missing Pieces, And Why People Say “Benchmaxed”
If you’ve spent any time in model-launch comment sections, you’ve seen the same three questions on loop:
5.1 “Where’s SWE-bench?”
LiveCodeBench v6 is useful, but SWE-bench has become a cultural artifact. It’s the benchmark people pull out when they want proof that a model can survive real repo dynamics, messy tests, and constraints that aren’t politely formatted as a single prompt.
No SWE-bench result doesn’t mean Falcon H1R 7B is weak. It means you don’t get that particular validation for free.
5.2 “Show Me Post-Quant Benchmarks”
Most teams publish full-precision scores and then toss a GGUF on the table like a party favor. Quantization can be great, and it can also quietly shave off the exact reasoning edge you showed off in your launch chart.
If you plan to deploy quantized, you need your own small evaluation set. Not a thousand prompts. Twenty to fifty of your prompts, run the same way every time.
5.3 “Is The Training Data Clean?”
The report’s contamination check helps.
It won’t silence every skeptic, and it shouldn’t. For production, your standard is simpler: “Does it work on my workload, under my constraints, with my prompts?”
That’s the right skepticism. Not cynicism, just engineering.
6. DeepConf + Test-Time Scaling, In Plain English
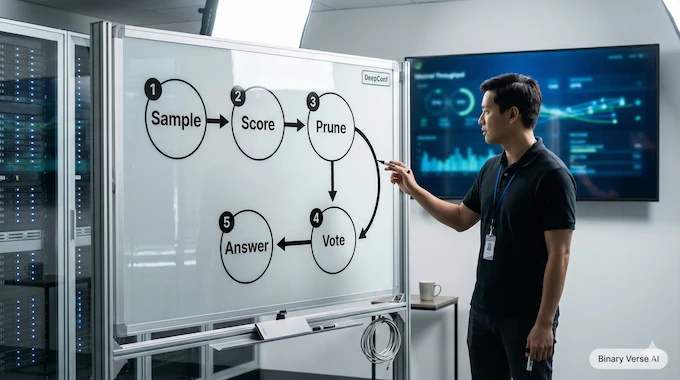
Test-time scaling is the idea that you can buy accuracy with inference compute. You generate multiple solution attempts, then pick or vote on the best one. The report frames this as a major direction of progress as training-only gains get more expensive.
The catch is cost. Parallel sampling can torch tokens fast.
DeepConf is their answer: generate many traces, but prune low-confidence chains early, using confidence scores derived from the model itself.
The setup they describe is fairly aggressive:
- A fixed trace budget K = 512
- Warm up with 16 traces, set a stopping threshold using confidence statistics
- Then generate the remaining traces with early stopping when confidence drops below the threshold
The vibe is “be ruthless, but in a calibrated way.”
7. Why Falcon H1R 7B Makes TTS Practical: Accuracy Vs. Token Cost
Here’s where Falcon H1R 7B gets interesting, not because of one benchmark, but because of the shape of the tradeoff.
Under DeepConf@512, the report shows voted accuracy and total generated tokens (in millions). Falcon-H1R-7B hits 96.7% on both AIME24 and AIME25, with token usage of 89.8M and 95.1M, respectively.
That token number is the quiet killer feature. In TTS land, throughput and pruning determine whether your clever inference scheme is a research demo or a product feature.
The paper even calls out an example: on AIME25, it reports 96.7% accuracy and lower token usage relative to a baseline model in their comparison set.
If your system runs dozens of calls per user action, this kind of efficiency is not a rounding error. It’s the difference between “cool prototype” and “we can actually afford this.”
8. Under The Hood: Hybrid Transformer–Mamba, And Why Batching Matters
The report positions the model within the Falcon-H1 family, described as hybrid Transformer–Mamba style architectures optimized for high throughput and low memory at long sequence lengths and high batch sizes.
That’s not abstract theory, it’s a direct response to what TTS needs:
- Long outputs
- Many parallel traces
- High batch sizes
- Stable throughput under load
The inference appendix includes architectural specs, including a 256K context length for the model configuration they document.
It also describes vLLM throughput comparisons against Qwen3-8B across batch sizes and long output regimes, reporting throughput improvements ranging from +20% to +100% in their tests on H100s.
So when someone asks why this model exists, the clean answer is: it’s designed for the regime where you batch a lot and generate a lot. That’s the modern reasoning stack.
9. How To Use Falcon H1R 7B Without Overthinking It
9.1 Fastest Path: Hosted Demo Or Chat
If you just want to get a feel for behavior, use the hosted demo or the official chat surface. Do a quick pass on:
- “Explain your reasoning” prompts (and check if it stays coherent)
- Multi-step math or logic tasks
- Tool-style prompts where you want structured output
Your goal here is not to fall in love. It’s to decide if it deserves local time.
9.2 Local Path: falcon h1r 7b gguf
If you’re the type who wants to run falcon h1r 7b locally, GGUF makes the first run easy. Start with your realistic prompt lengths, not the cute examples.
A practical workflow:
- Pick 20 prompts you actually care about.
- Run them at your target context and output lengths.
- Save outputs.
- Change one thing at a time (quant level, context, sampling), then rerun.
That’s how you learn the model, not by reading a chart.
9.3 Server Path: Transformers Or vLLM
For production-ish evaluation, you want a server setup where you can test batching and latency. The report’s own inference analysis uses vLLM for throughput evaluation.
That’s the right direction if you care about parallel traces.
10. Hardware Reality Check: The Context Window Is Real, Not Free

This is where the internet gets weird. People talk about context length like it’s a magical property, not a bill. The report lists Context Length 256K in the inference appendix configuration.
It also sets large generation lengths in its test-time scaling setup, up to 64K tokens per trace in their DeepConf evaluation configuration.
That combination is powerful, and expensive.
Here’s the grounded guidance:
- Weights are not your main problem. A 7.59B parameter model at bf16 is roughly ~15–16 GB for weights alone, plus overhead.
- KV cache is your problem. Long context plus long outputs multiplies memory use fast, especially when you run many traces or large batches.
- Batching changes everything. A model that’s “fine” at batch 1 can fall apart at batch 32 if your memory math is optimistic.
If you want one SEO-friendly line that’s still true: falcon h1r 7b hardware requirements depend more on your sequence lengths and concurrency than on the 7B label.
Test at the lengths you plan to ship. Your future self will thank you.
11. Quantization: Convenience, Speed, And The Part Where Accuracy Can Slip
Quantization is great when you’re bottlenecked on VRAM or you want to run more concurrent requests. It’s also a classic place where reasoning models lose their edge in subtle ways.
The problem is social, not technical: most releases don’t publish full post-quant tables, so you inherit uncertainty.
My advice for Falcon H1R 7B is boring on purpose:
- Treat GGUF as a deployment tool, not a truth machine.
- Verify on your prompts.
- Pay special attention to tasks that require long, careful chains, since that’s where small numeric changes can snowball.
If you do this right, you’ll stop arguing online and start measuring.
12. License And Adoption Risk: Read The Fine Print Like An Adult
Falcon H1R 7B is positioned within the Falcon series, and the ecosystem is framed around the Falcon LLM license in the release context, so treat licensing as part of your technical due diligence.
If you’re evaluating adoption for anything commercial, check:
- Commercial use permissions
- Redistribution rules
- Acceptable use policies
- Any downstream restrictions that could surprise you later
This is the least fun part of model selection, and the part that can hurt the most if you ignore it.
Closing: Should You Switch, Or Should You Test?
Here’s the honest version.
If your work is math-heavy, or you’re building an agentic system where you can afford multiple parallel attempts, Falcon H1R 7B looks like a serious candidate. The report’s core thesis is that a compact model can be competitive by combining targeted training with efficiency under test-time scaling.
If your work needs SWE-bench receipts, or you plan to deploy heavily quantized and demand published post-quant scores, you should treat it as “promising, now prove it.”
Either way, don’t make this a fandom decision. Make it a measurement decision.
Call to action: Take your top 20 real prompts, run them in three modes, single-shot, multi-sample, and DeepConf-style filtered voting. Then post what you found. If you’re shipping, that little harness will teach you more than a week of scrolling hot takes.
And if you want one last anchor sentence to remember: Falcon H1R 7B is interesting because it makes “more thinking” feel less like a luxury feature and more like something you can actually budget for.
Is Falcon AI free to use?
Falcon H1R 7B weights are publicly available, but “free” depends on the Falcon LLM license and your use case, especially commercial use and redistribution. Treat it as available with conditions, then verify the exact license terms before shipping.
How do I access Falcon H1R 7B?
The fastest path is the official Hugging Face pages: the main weights repo and the falcon h1r 7b gguf repo for local inference. For servers, run it through Transformers or vLLM. For local, GGUF tooling is the shortest route.
What is a 7B parameter model, and why does it matter here?
“7B” means roughly seven billion learned parameters. The point of Falcon H1R 7B is efficiency: it targets strong reasoning results without needing a 30B to 70B class model, helped by training choices plus test-time scaling ideas.
What changed in Falcon H1R 7B compared to the base Falcon H1 7B?
Two big changes define Falcon H1R 7B: cold-start SFT on long reasoning traces (math, code, science, long outputs), then RL with GRPO to refine reasoning quality while staying inside token budgets.
Is Falcon H1R 7B the best AI for reasoning or coding?
It’s one of the strongest “small reasoning” releases by the reported numbers, especially in math, and it’s competitive for code-style reasoning. “Best” depends on your workload. The clean framing is: best 7B-class reasoning efficiency under test-time scaling, not best overall model.