

Introduction
Bigger models keep winning, but the reason is not always “more intelligence.” Sometimes it is just less wasted work.
The Engram paper makes an almost irritatingly sensible point. Transformers do two jobs at once: they remember stable patterns, and they reason over them. Since a vanilla transformer has no native lookup primitive, it often simulates retrieval by burning attention and MLP depth early in the stack, even for common multi-token entities. That is expensive, and it steals depth from the parts that actually benefit from depth.
Engram’s proposal is to treat memory as its own sparse primitive, alongside MoE compute, and to make that memory conditional. The paper calls the primitive Conditional Memory. I like this framing because it turns a vague complaint, “models waste compute,” into a concrete architectural knob. You can almost hear the profiler running in the background: why spend sequential depth reassembling yesterday’s n-grams when a lookup would do.
Table of Contents
1. Conditional Memory, The Missing Primitive In Transformers
1.1 The Two Jobs Problem
A language model is constantly switching between:
- Recall: local, repetitive structure, names, phrases, short dependencies.
- Reason: global context, composition, multi-step logic.
Today, transformers blur those jobs. They can spend multiple early layers reconstructing what is basically a lookup table at runtime.
That is the intuition behind Conditional Memory. Give the model a cheap way to fetch stable patterns, so attention and later layers can focus on what changes with context.
Conditional Memory Workload Map
A quick, scannable view of where standard transformers spend compute, and where Conditional Memory shifts work into fast lookup.
| Workload | What Standard Transformers Do | What Conditional Memory Tries To Do |
|---|---|---|
| Common phrases, entities | Re-derive patterns through depth | O(1) retrieve a stored pattern embedding |
| Long context | Spend attention on local glue | Offload local glue, save attention for global links |
| Reasoning tasks | Mix recall with reasoning in the same depth | Preserve depth for composition and planning |
1.2 Why This Is Not Just Another Memory Story
The paper frames Conditional Memory as a complementary sparsity axis to conditional computation. MoE sparsely activates experts to run dynamic logic. Conditional Memory sparsely retrieves embeddings to recall fixed patterns.
That separation matters because it gives you two knobs that push on different failure modes.
2. DeepSeek Engram In One Minute
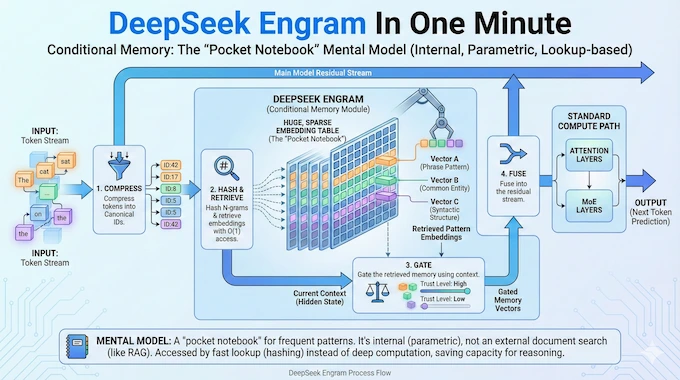
DeepSeek Engram keeps a huge table of local pattern embeddings. At each token position, it looks at the recent suffix, hashes it into deterministic indices, pulls a small set of vectors, then decides how much to trust them based on the current context.
If you want a mental model, think “pocket notebook.” Not external like RAG, still parametric, just accessed by lookup instead of by layered computation.
A forward pass adds four quick steps:
- Compress tokens into canonical IDs.
- Hash N-grams and retrieve embeddings with constant-time access.
- Gate the retrieved memory using context.
- Fuse into the residual stream, then run attention and MoE as usual.
3. How Engram Works, Hashed N-Gram Embeddings With O(1) Lookup

3.1 Tokenizer Compression, More Semantic Density
Tokenizers care about reconstructing text, so they often assign different IDs to near-equivalent strings. Engram adds a projection that maps raw token IDs into canonical identifiers using normalized textual equivalence, including NFKC and lowercasing. That yields a 23% reduction in effective vocabulary size for a 128k tokenizer in their setup.
This is a quiet but important piece of Conditional Memory: fewer accidental duplicates means more useful patterns per byte.
3.2 Multi-Head Hashing, Collisions Managed
Engram cannot parameterize all possible N-grams, so it hashes them. To reduce collisions, it uses K distinct hash heads per N-gram order and concatenates the retrieved embeddings into one memory vector.
The scaling point is that only a constant number of slots are retrieved per token. So you can grow the table without increasing per-token FLOPs. That is the practical meaning of Conditional Memory.
4. The Gate, Why The Model Doesn’t Blindly Trust Lookups
Lookup is fast, but it can be wrong, especially under collisions or polysemy. Engram adds context-aware gating: the hidden state becomes a query, retrieved memory becomes key and value, and the model produces a scalar gate via normalized dot product and a sigmoid. When memory contradicts context, the gate falls toward zero and suppresses it.
Then it runs the gated values through a small depthwise causal convolution, kernel size 4, dilation tied to max N-gram order, SiLU, and a residual connection back into the backbone.
This is the core safety valve. Conditional Memory is cheap recall, not an oracle.
5. A New Axis Of Sparsity, Engram Vs MoE
MoE is conditional compute. You activate a few experts per token.
Engram is conditional memory. You retrieve a few vectors per token.
The paper pitches these as complementary primitives, and that lines up with a broader view of transformers: FFNs are often hypothesized to behave like key-value stores for factual associations. If that is even partly true, then adding Conditional Memory is less like bolting on a feature, and more like acknowledging what the network was already trying to become, just inefficiently.
There is also a clean engineering intuition here. Conditional computation helps when the transformation you need depends on context, so you want specialized “thinking” paths. Conditional Memory helps when the thing you need is stable, so you want fast access. Confusing these two is how you end up with models that are huge, expensive, and still oddly forgetful.
6. The U-Shaped Scaling Law, How Much Memory Is Too Much
Here is the part I trust most: they do not claim “more memory always wins.”
They define an allocation ratio ρ, the fraction of sparse capacity given to MoE experts, with the remainder given to Engram embeddings. Sweeping ρ yields a U-shaped curve. Pure MoE is suboptimal. Pure memory is suboptimal. Best results come from reallocating roughly 20% to 25% of sparse budget to memory, with an optimum around ρ ≈ 75% to 80% that stays stable across tested regimes.
That is a great sign. Conditional Memory is not a shortcut, it is a missing piece, and it still respects the need for real compute.
7. Does It Improve Reasoning, Not Just Trivia
The headline results are intentionally iso-bounded: same total parameters and same per-token FLOPs.
Engram-27B is derived from MoE-27B by reducing routed experts from 72 to 55, reallocating the freed parameters to a 5.7B embedding module, while keeping total size constant. Under that comparison, the reported gains show up across knowledge benchmarks, general reasoning, and code and math, including improvements on BBH, ARC-Challenge, HumanEval, and MATH.
Mechanistically, the authors argue Engram relieves early layers from reconstructing static knowledge, effectively increasing depth for complex reasoning. That fits an informal mental model: the first blocks of a transformer are often doing syntax and phrase assembly, and only later do you get the “planner” vibe.
The fun part is that the paper reports the biggest deltas in places where you would not expect a dumb lookup table to help, general reasoning and code. My read is that Conditional Memory is not directly solving logic. It is clearing the runway so the model’s existing compute can do more useful work per layer.
8. Long Context, Local Offload Buys Global Attention
Engram’s long-context claim is structural: offload local dependency modeling to lookups, and attention can spend more budget on global context.
On 32k long-context evaluation, Engram-27B improves RULER across tasks, including Multi-Query NIAH at 97.0 versus 84.2 for the MoE baseline in a matched setting, and stronger Variable Tracking too. The paper also highlights that Engram can match perplexity while improving accuracy, even with fewer pre-training steps.
9. Serving And Hardware, VRAM Is Not Your Destiny
MoE routing creates messy communication at inference. Engram’s access is deterministic. Once tokens are known, the lookup indices are fixed and can be computed ahead of time, which makes runtime prefetching possible.
The system design is clear: tables are sharded across GPUs during training, and can be offloaded to host memory at inference, while the host asynchronously prefetches embeddings and overlaps transfer with computation in preceding blocks.
They benchmark a conservative case: a 100B-parameter memory table entirely in host DRAM. The throughput penalty peaks at 2.8% on an 8B backbone, implying the transfer can be hidden behind early-block compute. The introduction summarizes it as under 3% overhead for offloading a 100B table.
If you are wondering about AI inference vs training, this is where it lands. Training is the one-time spend, inference AI is the recurring bill. inference AI meaning is basically, can I serve this fast, cheaply, and predictably.
This is where Conditional Memory feels unusually practical. Deterministic IDs mean you can prefetch like you are streaming video, not like you are playing roulette with a router. It also means the effective communication volume scales with the number of activated slots, not the total table size. So you can imagine a world where the “capacity” slider keeps moving up, while your per-token latency barely twitches.
If this shows up in a production DeepSeek API, it could shift deployment expectations.
10. Engram Vs RAG Vs Over-Tokenization, What It Is Not

Engram is still parametric. It stores embeddings as parameters and retrieves them via hashed N-gram lookups. RAG retrieves external documents. Over-tokenization changes the sequence, often increasing compute pressure. A classic n gram language model is fast at local patterns, and bad at global composition.
Conditional Memory, RAG, And N-gram Approaches
A side-by-side comparison of where knowledge lives, how it is retrieved, and what you trade off for speed, freshness, and reasoning headroom.
| Approach | Where Knowledge Lives | Retrieval Mechanism | Best For | Tradeoffs |
|---|---|---|---|---|
| Conditional Memory (Engram) | In-model embedding table | Deterministic hashed N-gram lookup | Cheap local recall, freeing depth | Collisions, limited editability |
| RAG | External corpus | Similarity search, rerank, prompt | Fresh facts, provenance, enterprise docs | Latency, retrieval quality, prompt fragility |
| Over-Tokenization | Token stream | More tokens, more context | Some pattern coverage | Longer sequences, higher inference cost |
| n gram language model | Explicit N-gram stats or embeddings | Direct lookup | Local dependencies | Weak reasoning, weak abstraction |
11. Critiques And Failure Modes, The Systems Reality Check
11.1 Collisions, Polysemy, Rare Patterns
Multi-head hashing and gating help, but collisions still exist. Sometimes you retrieve a plausible, wrong prior, and the gate does not fully mute it. Rare N-grams also raise the classic “long tail” question, capacity can get wasted on patterns that never repeat.
11.2 Memory Cannot Replace Compute
The U-shaped curve is the warning label. In the memory-dominated regime, reasoning tasks degrade, because memory cannot substitute for conditional computation.
11.3 Responsibility Split And Single Points Of Failure
Ablation hints at a functional split: factual knowledge collapses under Engram ablation, while reading comprehension is largely preserved by the backbone. That is interesting, and also operationally relevant. You just introduced a component that can become a bottleneck for certain behaviors.
11.4 Systems Complexity, The Price Of Cleverness
The paper explicitly argues for algorithm-system co-design, including deeper placement to overlap communication and computation. That is great, and it also means more knobs to tune, prefetch windows, caching policies, and failure cases that look like “the model got dumber when the PCIe bus was busy.” If you have shipped distributed systems, you know that last sentence is not a joke.
12. What This Likely Means For DeepSeek V4, And Your Next Step
I do not know what DeepSeek v4 will ship, but the direction is clear. Sparse models are growing new primitives, and Conditional Memory is a strong candidate for the default toolkit because it decouples storage from compute. The paper’s conclusion explicitly points to deterministic addressing and offloading large tables with negligible inference overhead.
My bet is that the next wave of “bigger” models will feel less like brute force, and more like better budgeting:
- more total capacity without GPU panic,
- more effective depth for reasoning,
- smoother inference economics.
If you build or evaluate models, do one simple thing. Stop asking only “how big is it”, start asking “what work is it doing per layer.” Conditional Memory is a neat answer to that question, and it is a useful lens even if you never implement Engram yourself.
If you want a simple litmus test, try this on your next model read: when performance improves, did we buy it with more compute, or did we stop wasting compute. Conditional Memory is a sharp way to ask that question, and Engram is a concrete, testable answer.
If this sparked ideas for your own architecture or serving stack, share the post, and send me the weird failure case you hit first. Better yet, run a small experiment, even a toy version. The fastest way to understand this primitive is to watch it fail, then watch what the backbone does when you take the crutch away.
What is conditional memory in LLMs (in plain English)?
Conditional memory is a learned lookup module that retrieves helpful information only when the current context needs it. Instead of spending layers re-deriving common patterns, the model fetches a compact memory vector and keeps its compute for reasoning and planning.
Is DeepSeek Engram “just a lookup table” or real learning?
DeepSeek engram is a lookup over trained parameters, not an external database. The memory embeddings are learned end-to-end, then mixed into hidden states through gating. That means the module can learn what to store, when to retrieve, and when to ignore noisy matches.
How is Engram different from RAG?
RAG retrieves documents at runtime, then feeds them into the prompt. Engram retrieves parametric memory embeddings inside the forward pass. Engram mainly offloads local pattern reconstruction so attention can focus on global context, while RAG is best for fresh facts and source-grounded answers.
Do AI models use RAM or VRAM, and why does Engram change the conversation?
Most inference is bottlenecked by VRAM capacity and bandwidth, which limits how big you can run efficiently. Engram’s deterministic access makes memory more offload-friendly, so parts of the model can live in host RAM with prefetch, reducing the VRAM squeeze during inference AI.
Will this show up in DeepSeek v4, and will it improve multi-turn memory?
No release is guaranteed, but the design is positioned as a foundation for next-gen sparse models. If DeepSeek v4 adopts it, the biggest win is likely better reasoning and long-context behavior from freed attention capacity, not “chat history memory” in the product sense.