

Introduction
If you have ever watched a self-driving demo and thought, “Cool, but why did it do that?”, you are not alone. Autonomous driving has spent a decade getting better at perception, better at prediction, and better at path planning, while staying stubbornly bad at explaining itself. When something goes weird, the stack usually responds with silence, or worse, a confidence score.
Alpamayo-R1 is NVIDIA’s attempt to make driving policies less opaque. Not by bolting a chatbot on top of a planner, but by training a single vision-language-action model that can both talk through a decision and output a trajectory you can execute. Think less “robotaxi in a box”, more “inspectable foundation model for driving.”
So let’s skip the hype loop and answer the only questions that matter, what is actually open, what is actually useful, and what does it take to run.
Table of Contents
1. Alpamayo-R1 In One Sentence, And Why NVIDIA Calls It A “ChatGPT Moment” For Physical AI
Alpamayo-R1 is a reasoning-first driving policy that turns multi-camera sensor history plus a text prompt into two outputs, a short causal explanation of what it is doing, and a kinematically feasible future trajectory.
That “ChatGPT moment” framing makes sense if you read it as a workflow shift, not a product launch. The jump is from “black box behavior cloning” to “systems that can explain their intent in plain language while acting in the world.” That matters for validation, debugging, and regulation, even if it does not magically solve the last mile of safety.
Here’s the fastest way to set expectations.
Alpamayo-R1: What’s Open vs What You Still Build
| What You Get From The Stack | What You Still Have To Build |
|---|---|
| A reasoning VLA model that produces explanations plus trajectories | A production-grade safety case, redundancy, fault handling, and certification |
| A simulator-friendly policy you can benchmark in closed loop | A full perception and sensor fusion stack tuned for your hardware |
| A data recipe centered on causal, decision-grounded traces | Fleet data, rare corner cases, and an operational validation pipeline |
| A credible starting point for research and distillation | A consumer-ready Nvidia self driving product, because that is not what this is |
If you work on NVIDIA autonomous vehicles, this looks like an accelerant. If you are hoping to retrofit a car and call it Level 4, this is not that.
2. What Alpamayo-R1 Actually Is, A Reasoning VLA That Outputs Both Explanations And Trajectories
Most end-to-end driving models output a trajectory and call it a day. Alpamayo-R1 treats language as part of the policy. If you see people write alpamayo r1 in forums, they mean the same model, just less punctuation.
The model autoregressively generates a reasoning trace and discrete trajectory tokens, then uses an action-expert decoder to turn those tokens into continuous waypoints at inference time.
That dual-output design is the point. The explanation is not a marketing garnish, it is intended to be a first-class artifact you can audit. In the paper’s framing, text reasoning lets the model explore alternatives “in language space” before committing to motion.
A trajectory alone is ambiguous. A trajectory plus a stated driving decision plus causal factors is something a human can review, and a test harness can score.
3. What’s Included In The “Open Stack”, Model, AlpaSim, And Physical AI Datasets
The Alpamayo portfolio is presented as a three-piece kit: the model, the AlpaSim simulation framework, and physical AI datasets (with a gated subset released publicly). Think “policy, testbed, and data”.
The important part is the loop. Run the policy in simulation, measure driving metrics, iterate on training, repeat. Closed-loop evaluation matters because open-loop metrics can flatter you. A model can predict plausible waypoints and still crash once it has to live with its own consequences.
That is why Alpamayo-R1 is interesting, it comes with a path to make it falsifiable.
4. “Open Source” Vs “Open Weights”, The Licenses People Keep Mixing Up

If you have been around ML long enough, you have seen this movie. Someone says “open source,” half the room hears “I can ship it,” and the other half hears “I can read it.”
With this stack, treat “open” as two different layers:
- Code openness, can you inspect and modify the implementation?
- Weight openness, can you use the trained model commercially?
Those are not the same question.
Here is a clean mental model you can keep on a sticky note:
Alpamayo-R1: Open Code vs Open Weights vs Rights
| Layer | Typical Meaning | Why It Matters |
|---|---|---|
| Open Source Code | You can run, inspect, modify, and contribute | Enables reproducibility, debugging, and custom evaluation |
| Open Weights | You can download the trained parameters | Enables research replication and benchmarking |
| Commercial Rights | You can ship it in a product | Determines whether this becomes a business asset or a research tool |
If you are a researcher, you care about the first two. If you are a startup, the third one decides your roadmap.
5. The Core Idea, Chain Of Causation Reasoning, Not Free-Form Chain-Of-Thought
Here is the subtlety most people miss. Alpamayo-R1 is not trying to get the model to ramble more. It is trying to make the reasoning trace tethered to the executed driving decision.
The paper spends real time criticizing the usual free-form chain-of-thought datasets in driving. They can be vague, they can be superficial, and they can “leak the future” by referencing events that occur after the history window.
So they build a Chain of Causation (CoC) dataset with explicit structure: pick a driving decision from a closed set, list only causal factors that occur in the observable history window, then compose a concise trace.
The key phrase is “decision-grounded and causally linked.” The model is trained to say “I am yielding because the pedestrian is in the crosswalk,” not “I am being cautious because driving is hard.”
Regulators do not want poetry. They want a cause-and-effect claim that can be checked.
6. Under The Hood Without Drowning Readers, Cosmos-Reason Backbone, Action Expert, And Flow-Matching Trajectory Decoding
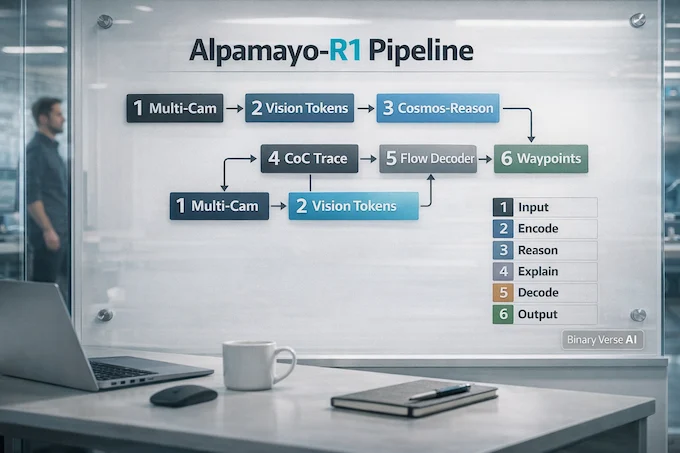
The architecture is modular, and that is refreshing. At a high level:
- A vision encoder turns multi-camera, multi-timestep inputs into tokens.
- A VLM backbone, Cosmos-Reason, does cross-view reasoning and language generation.
- The model emits discrete trajectory tokens during autoregressive decoding.
- An action-expert decoder uses flow matching to convert those tokens into continuous, kinematically feasible waypoints, conditioned on the reasoning output.
Flow matching shows up for latency and geometry. Autoregressively decoding long trajectories as tokens is slow and awkward for constraints. The paper explicitly calls out that waypoint decoding as text is inefficient and lacks the geometric and kinematic structure you want for safe control.
In their runtime breakdown, flow-matching trajectory decoding is a single-digit millisecond component, versus hundreds of milliseconds when doing it autoregressively.
If you want a simple mental model, imagine a translator who first writes down intent in English, then hands it to a motion specialist who speaks “acceleration and curvature” fluently.
That separation is why Alpamayo-R1 can be both interpretable and fast enough to matter.
7. Performance Reality Check, What “Real-Time” Means Here

“Real-time” is a word people abuse. In driving, it is not a vibe, it is a budget. If your policy takes 300 milliseconds to respond, you are effectively driving while looking through a keyhole.
The paper benchmarks end-to-end inference on an NVIDIA RTX 6000 Pro Blackwell platform and reports 99 milliseconds latency, which they place within a typical 100 millisecond real-time requirement.
Even better, they show where the time goes. Reasoning decoding is about 70 milliseconds for 40 tokens, and trajectory decoding is about 8.75 milliseconds with five flow-matching steps.
That breakdown tells you what to optimize. If you want faster, you can compress vision tokens (they discuss alternatives) or shorten reasoning, or both. What you cannot do is pretend the language part is free.
8. Hardware And Software Requirements, The Section Reddit Actually Wants
Let’s be blunt. Alpamayo-R1 is a 10B-class model. That means it is not a weekend microcontroller project.
The released stack targets NVIDIA GPUs, and in practice you want at least one modern card with enough VRAM to hold weights plus overhead. The public materials point at 24 GB as a practical floor for a single-GPU setup, with Linux as the expected environment.
One tip that will save you time: plan your storage and download pipeline. Weights for Alpamayo-R1 are large enough that your network becomes part of your stack.
9. How To Run Alpamayo-R1, A Quickstart That Won’t Waste Your Afternoon
The quickest path is to treat this like any other gated model workflow:
- Request access to the model weights and the dataset subset on Hugging Face.
- Authenticate locally so your download can actually happen.
- Create a clean Python environment, then install dependencies.
- Run the provided inference script on the included example data.
- Visualize predicted trajectories and read the reasoning traces side by side.
Where people stumble is step one. Gated access is a speed bump, but it is also a clue about how NVIDIA wants this used right now, as a research foundation, not as a turnkey product drop.
10. Simulation Vs Real World, What Alpamayo Uses, And What You Should Test In Closed Loop
Open-loop evaluation is the comfort food of autonomous driving research. It is easy to compute, and it produces tidy charts. It is also where bad models can look good.
Closed-loop evaluation is meaner and more honest. It forces the policy to live with its own decisions, and it exposes compounding errors.
The paper reports closed-loop results in AlpaSim across 75 challenging scenarios. In that setting, Alpamayo-R1 reduces off-road rate from 17.0% to 11.0% and reduces close encounter rate from 4.0% to 3.0%, while improving the AlpaSim score.
Those numbers are not “we solved autonomy.” They are a signal that causally grounded reasoning plus action alignment can translate into measurable safety and comfort improvements in closed loop.
This is also where autonomous vehicle lidar and the broader sensor suite re-enter the conversation. Your real-world system lives or dies by sensor diversity, synchronization, and failure modes. Simulation is where you should break those assumptions safely.
11. Alpamayo-R1 Vs Tesla FSD Vs Waymo, Answer It Directly, Without Stock Talk
People ask this comparison because they want a scoreboard. The honest answer is that they are playing different games.
Alpamayo-R1 is a toolbox designed to be inspected, adapted, and evaluated. Tesla FSD is a vertically integrated product tied to a fleet and a specific vehicle platform. Waymo is a robotaxi deployment with geofencing plus a safety and operations apparatus that is as important as the model.
The moat is not a single network. The moat is data plus deployment plus validation. This is where the levels of autonomous vehicle framing becomes useful. A level 3 autonomous vehicle can sometimes lean on the driver. Level 4 needs to stand on its own in a defined domain. Alpamayo-R1 is positioned as a Level 4 research foundation, not a consumer-ready system.
So if you are choosing between them, ask a different question: do you need a product, a deployment, or a toolbox?
12. What You Can Build With It, And What You Can’t, Yet
Let’s end with a pragmatic list, because this is where the hype usually collapses into confusion.
With Alpamayo-R1, you can:
- Build evaluation harnesses that score both motion and stated intent.
- Prototype interpretable planners where language acts as a debuggable interface.
- Use the model as a teacher for distillation into smaller policies.
- Experiment with auto-labeling pipelines that produce structured driving decisions and causal factors.
- Stress test long-tail scenarios in simulation, then iterate.
What you cannot do, at least not responsibly, is drop Alpamayo-R1 into a car and declare victory. Real autonomy requires redundancy, sensor fault handling, operational design domains, and a verification story that is far bigger than a single model.
Alpamayo-R1 is a bet that interpretability and action quality can be trained together, then tested in closed loop, then improved again. If that resonates with your work, pull the code, run the examples, and start measuring. If you do not measure, you are just vibes-testing a 10B-parameter policy.
And if you publish anything you learn, benchmarks, failure modes, distillation tricks, weird corner cases, send it my way. The field moves forward when we turn demos into data, and data into shared understanding.
Will Tesla compete with Nvidia with Alpamayo-R1?
Tesla and NVIDIA compete at different layers. Tesla ships a vertically integrated driver-assist product tied to its fleet. Alpamayo-R1 is a developer foundation and research stack that OEMs and AV teams can adapt, test, and distill into their own systems.
Is Tesla or Nvidia better for self-driving?
“Better” depends on what you are building. Tesla optimizes for broad consumer deployment and rapid iteration from fleet data. NVIDIA focuses on enabling partners with compute, tooling, simulation, and now Alpamayo-R1 as a foundation model to speed up development and validation.
What is meant by Chain of Causation in Alpamayo-R1?
In Alpamayo-R1, Chain of Causation is a structured explanation format tied to a specific driving decision. The reasoning only references causal factors visible in the input history window, which helps prevent vague narratives and prevents “future leakage” into the explanation.
What is an example of a “break” in the Chain of Causation?
A break happens when the explanation cites a cause the model could not have observed yet, like referencing a pedestrian stepping out before it appears in the history window. Another break is “hand-wavy” text that does not match the actual trajectory choice, like claiming to yield while accelerating through.
Is Alpamayo-R1 open source, and can I use it commercially?
Alpamayo-R1 typically ships with open inference code, but the model weights are released under a non-commercial license. That means you can study, run, and evaluate it for research, but commercial deployment is restricted unless NVIDIA provides a separate commercial path.