

Introduction
Some weeks feel like a neat list of headlines. This one felt like watching a distributed system under load. Everything speeds up, the bottlenecks move, and the dashboards start arguing with each other. We got faster decoding for small-ish language models, test-time learning that treats long context like continual training, image generation that finally respects faces and typography, and a reminder that the real limiting reagent is still power.
This edition of AI News January 3 2026 is built to do two jobs. First, give you the pulse, what shipped and what got published. Second, pull out the pattern, the few trends that will matter when the hype dust settles.
The patterns are repeating:
- Speed is becoming a feature, not an optimization.
- Memory is becoming a capability, not a context length.
- Infrastructure is becoming the moat, not an afterthought.
Now let’s hit the top AI news stories.
Table of Contents
1. Tencent Wedlm-8b-instruct, Diffusion Parallel Decoding Makes 8b Models Feel Fast
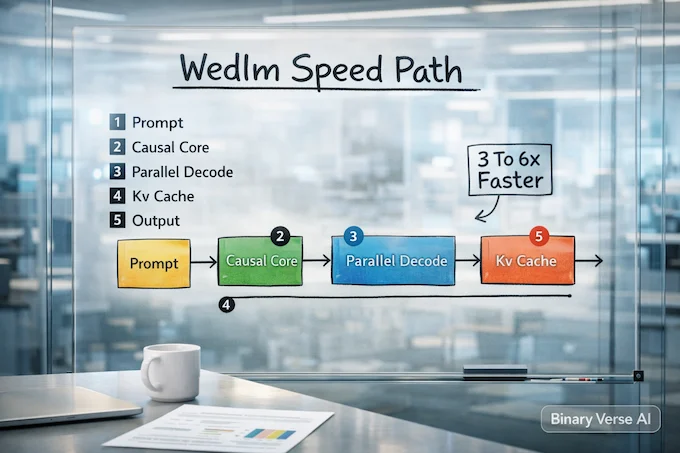
Tencent dropped WeDLM-8B-Instruct, an instruction model that borrows diffusion-style parallel decoding while keeping standard causal attention. The pitch is pragmatic, faster answers without forcing teams to abandon mainstream Transformer tooling. It is built on a WeDLM-8B base derived from Qwen3-8B-Base, and targets chat, coding, and reasoning where latency decides what gets used.
Tencent reports 3 to 6x faster inference than a vLLM-optimized Qwen3-8B-Instruct on structured math, plus smaller gains on code and open QA. It also ships a 32,768 token context window and keeps KV-cache friendliness, including FlashAttention-style stacks. With an Apache-2.0 license and a dedicated engine, it reads like an “adopt it, ship it” open source AI project.
2. TTT-E2E Test-Time Training Treats 128k Context Like Continual Learning

TTT-E2E argues long-context language modeling has been framed wrong. Instead of paying the growing cost of full attention, it keeps a standard Transformer with sliding-window attention and learns at test time. During inference, the model runs next-token prediction over the provided context and compresses useful information into its weights.
The paper claims constant latency regardless of context length, and reports being 2.7x faster than full attention at 128K on an H100. It also says quality keeps pace with full attention as context grows, while some sequence-model alternatives degrade. The “end-to-end” trick is meta-learning an initialization that is good at adapting during test-time learning, which makes this one of the more interesting new AI papers arXiv for long context.
3. Qwen-image-2512 Targets The Three Image Model Pain Points
Qwen released Qwen-Image-2512 as a December refresh aimed at the stuff that makes images feel real. It focuses on more convincing people, richer textures, and better text rendering inside scenes. In practice, those are the three failure modes that turn a promising demo into a visual generation production headache.
The headline upgrade is human realism, cleaner skin detail, sharper hair, expressions that do not drift. The sleeper upgrade is typography and layout stability, fewer garbled glyphs when you ask for posters, labels, or slide-like compositions. Qwen claims strong results in large blind evaluations and positions it as a leading open-weights option. Put this in the “new AI model releases” bucket that nudges visual generation closer to dependable workflows.
4. mHC Stabilizes Wider Residual Mixing With A Doubly Stochastic Constraint
DeepSeek’s mHC takes aim at a scaling problem. Hyper-Connections widen the residual pathway by running multiple streams and mixing them, but unconstrained mixing breaks the identity-like behavior that keeps deep residual networks trainable. Once that clean signal path erodes across depth, training gets unstable quickly.
mHC constrains the residual mixing matrix onto the Birkhoff polytope, the set of doubly stochastic matrices, using Sinkhorn-Knopp projection. Rows and columns sum to 1, so each mix stays conservative, and the property survives across many layers. DeepSeek pairs the math with systems work like kernel fusion and selective recomputation, and reports about 6.7% training overhead at expansion rate 4. This AI advancement looks small, then quietly shifts the scaling knobs.
DeepSeek mHC Explained, Stable Hyper-Connections For Wider Transformers.
5. A Science Analysis Says Polished Prose Is No Longer A Quality Signal
A Science analysis zooms out from individual tools and asks what LLMs do to scientific production at scale. By scanning arXiv, bioRxiv, and SSRN with a text-based detection approach, the authors link LLM usage to faster manuscript output, lower friction for non-native English writers, and broader literature discovery patterns. The output is not just more papers, it is different citation wiring.
The uncomfortable part is evaluation. If fluent writing becomes cheap, “this reads smart” stops being a reliable filter. The paper pushes institutions toward incentives that reward verifiable work, reproducibility, provenance, and auditability. Think of it as AI regulation news without a legislature, new norms for a world where volume rises and old heuristics fade.
6. OpenAI Hardware Rumors Hint At An AA Pen, And The Interface Stakes
OpenAI hardware rumors have drifted into hardware rumors, an Ive-era device that could be a pen, pitched as context-aware and voice-first. It sounds too simple, until you remember how much work happens away from screens. The ambition is to move from “open an app” to “capture intent,” an assistant that stays out of the way.
This story matters in AI News January 3 2026 because the last wave of AI gadgets struggled next to smartphones. Better models help, but hardware lives on friction. Reports mention manufacturing shifts and a naming dispute that forced marketing changes. If the pen exists, the bar is clear: it must do more than transcribe, it has to earn carry by being calmer than the phone. It needs to be a true voice-first device.
7. Chip Makers Enter 2026 With Inference As The New Battlefield

After a blistering 2025, Chip Makers are heading into 2026 expecting bigger demand and tougher constraints. Advanced memory, packaging, power delivery, and cooling are now part of the product story, not footnotes. Data center buyers still want more compute, but they want it installed, powered, and costed like a real business.
In AI News January 3 2026, the strategic pivot is inference. Training made the headlines, inference pays the bills. That shift opens room for specialized architectures and more competition, including hyperscalers pushing their own accelerators. For AI news this week January 2026, the takeaway is simple: the “best model” race is being shaped by watts, bandwidth, and supply chain execution.
8. Meta’s Reported Manus Deal Is A Loud Bet On Working Agents
Meta reportedly agreed to buy Manus for more than $2 billion, and the subtext is Agentic AI News going mainstream. Manus got attention for an agent that could assemble research reports and build websites, leaning on foundation models from multiple vendors. Buyers are rewarding systems that plan and execute multi-step tasks with less babysitting.
In AI News January 3 2026, the deal reads like a product wedge, not just an acquihire. Reports say Meta plans to keep the service operating and integrate capabilities into Meta AI across its distribution surfaces. The geopolitics angle is real, a Singapore HQ with Chinese founders under tighter scrutiny. If the reported revenue growth is accurate, this is how agentic AI becomes a business line.
9. xAI Expands Colossus, And Compute Turns Into A Power Project
Reuters reports xAI bought a third building to expand its Colossus cluster, with Elon Musk pointing at nearly 2 gigawatts of training capacity. At that scale, “more GPUs” is the easy part. Siting, grid access, cooling, and conversion timelines become the schedule drivers, and the plan reportedly targets a huge GPU count over time.
The controversy sits right where you would expect. The expansion is reported near major power infrastructure, including a natural-gas plant xAI is building, drawing criticism from environmental groups. The strategic read is vertical integration, owning more of the compute and power stack to move faster than rivals. In 2026, electricity is a competitive advantage disguised as a data center utility bill.
10. Forogated Origami Gives Deployable Robots Tape-measure Strength
Deployable robotics has a brutal trade-off, compact storage usually means low stiffness after deployment. A Science Robotics result highlighted by Nature introduces a fold-and-roll corrugated design called FoRoGated that aims to dodge that compromise. Think tape measure behavior, roll up small, then extend into a corrugated form that resists sagging under load.
The structure uses interlaced origami, multiple long strips connected in parallel with a ribbon weaving technique that enables smooth rolling while keeping aligned rotational joints for stability. The team backs it with finite element modeling plus theory, reporting strength predictions above 90% accuracy. That matters because designers can iterate on variants without endless prototypes. Not every AI world update is software, sometimes the future needs better mechanical Lego.
11. Cellwhisperer Brings Chat-style Exploration To Single-cell Sequencing
Single-cell RNA sequencing produces stunning data and equally stunning analysis queues. CellWhisperer, highlighted in Nature Reviews Genetics, tries to lower the entry cost by letting researchers explore scRNA-seq datasets through natural language. The value is early-stage orientation, quick answers about cell types, marker genes, and possible trajectories before you dive into heavy statistical work.
A reported comparison on colon cell data found it reached similar conclusions to conventional pipelines about four times faster. The method links transcriptomes with textual annotations so questions stay grounded in expression patterns. Demos also include developmental atlas work and candidate marker discovery. The message is workflow, AI as a faster loop for hypothesis generation, then humans and standard checks for confirmation.
12. European Banking Jobs Face A 200,000-role Reshuffle, AI Is The Catalyst
A Morgan Stanley forecast reported by the Financial Times projects over 200,000 European banking jobs could be cut by 2030, roughly 10% across 35 major banks. Customers keep moving routine work to apps, investors want leaner cost bases, and legacy systems are expensive to run. Generative AI is the accelerant that makes the cost math work sooner.
This is the human side of AI News January 3 2026. The roles most exposed are repetitive workflows in back and middle office operations, plus document-heavy work in compliance and parts of risk. The replacement story is a skills reset: oversight, exception handling, controls, and safer automation inside regulated shops. Cut too deep without reskilling and you get fragility, not efficiency. This touches on broader jobs displacement concerns.
13. Grok Business Tries To Look Enterprise Ready With Drive And Vault Features
xAI launched Grok Business and Grok Enterprise, aiming at teams that want an assistant with clearer boundaries. The pitch includes higher rate limits, shared workspaces, and a promise not to train on customer data. Business is self-serve, Enterprise adds admin tooling for managed rollout, and Vault is positioned for stricter security needs.
The differentiator is connectivity with access control. Grok can pull from Google Drive and is described as permission-aware, if you cannot see a file, it should not show up in results. Answers are framed as verifiable with citations and quote previews, and Vault adds customer-managed encryption keys. This is the enterprise assistant space maturing, and it will meet audits and AI regulation news the moment it hits production.
14. Web World Models Use Web Code As “Physics” And LLMs As Bounded Imagination
Web World Models proposes a middle path for agent environments. Traditional web apps are deterministic but bounded, fully generative worlds are open-ended but hard to control. WWMs put web code in charge of state, entities, constraints, and transitions, then call an LLM to add narrative, descriptions, and high-level choices.
The practical upside is tooling. Typed interfaces keep state explicit, and normal web stacks bring testing, versioning, and security boundaries. The paper demos environments from an infinite travel atlas grounded in real geography to game-like systems, showing how deterministic procedures enable infinite expansion without chaos. If you build agents that live in environments, this blueprint treats world building like software engineering.
15. Memory Research Is Becoming An Agent Design Manual
A survey called “AI Meets Brain” argues memory is the missing layer between single-turn outputs and durable autonomous agents. LLMs are still mostly stateless, so we keep stretching context windows as a substitute for persistence. The survey connects cognitive neuroscience framing to engineering patterns, short-term versus long-term memory and their agent analogs, temporary context versus external stores.
In AI News January 3 2026, this lands as a systems checklist. Memory Research is a lifecycle, extraction, updating, retrieval triggers, and how recalled content gets used, context augmentation or internalization. The survey also flags memory security, attacks like data extraction and backdoors, defenses like purification and runtime blocking. The frontier is multimodal memory and transferable skills, reusable expertise that can move between agents.
16. What To Watch Next Week
The week’s AI Advancements rhyme with each other. Speed is the user experience. Memory is the agent capability. Infrastructure is the ceiling. Also, no blockbuster Google DeepMind news this time, which is usually a sign they are cooking quietly.
Three bets to track:
- Diffusion ideas invading language inference.
- Test-time learning becoming a default for long context.
- Agents that ship, and get acquired, because they make money.
If this post helped you compress the noise into signal, share it with someone drowning in tabs. Subscribe, bookmark, or drop a comment with the one New AI papers arXiv release you think everyone missed. I’ll fold the best finds into the next AI News January 3 2026, and we’ll keep mapping the pattern, not just the pulse.
- https://huggingface.co/tencent/WeDLM-8B-Instruct
- https://arxiv.org/abs/2512.23675
- https://qwen.ai/blog?id=qwen-image-2512
- https://arxiv.org/pdf/2512.24880
- https://www.science.org/doi/abs/10.1126/science.adw3000
- https://www.techradar.com/…/openais-mysterious-chatgpt-gadget…
- https://www.wsj.com/tech/ai/after-a-year-of-blistering-growth…
- https://www.reuters.com/world/china/meta-acquire-chinese-startup…
- https://www.reuters.com/business/musks-xai-buys-third-building…
- https://www.nature.com/articles/s44287-025-00252-9
- https://www.nature.com/articles/s41576-025-00927-x
- https://www.ft.com/content/71e12f85-1edb-4156-8cb5-3fe8aef36d93
- https://x.ai/news/grok-business
- https://arxiv.org/abs/2512.23676
- https://arxiv.org/html/2512.23343v1
AI News January 3 2026: What are the biggest new AI model releases?
This week’s standout releases cluster around speed, long context, and practical deployment. Tencent’s WeDLM-8B-Instruct pushes parallel decoding without ditching causal attention. TTT-E2E reframes 128K context as continual learning at test time. Qwen-Image-2512 targets better realism and cleaner text in images.
AI News January 3 2026: What’s the most important arXiv research drop to read first?
If you care about agents and real systems, start with the “plumbing” papers: TTT-E2E for constant-latency long context, DeepSeek’s mHC for stabilizing wider residual mixing at scale, and Web World Models for building persistent, debuggable agent environments on normal web stacks.
AI News January 3 2026: What changed in agentic AI news this week?
The signal is consolidation plus “agents as products.” Meta’s reported Manus acquisition is a direct bet on paid, task-doing agents. xAI is pushing Grok into workplaces with Google Drive search and enterprise controls. Meanwhile, OpenAI’s rumored hardware experiments hint at agents that live with you, not in a tab.
AI News January 3 2026: Why is everyone talking about inference and chips going into 2026?
Training is still huge, but inference is where costs explode when real users show up. The chip story heading into 2026 is: more demand, tighter bottlenecks (memory, packaging, power), and more competition from specialized inference players and hyperscaler silicon. xAI’s “gigawatt-scale” buildout is the loudest example of how physical this race is getting.
AI News January 3 2026: What’s the real workforce impact headline, beyond hype?
Banking is a clean early case study: Morgan Stanley estimates over 200,000 European banking roles could be cut by 2030 as AI and digitization bite into repeatable work. At the same time, Science highlights a parallel shift in research itself: more output, weaker “polish = quality” signals, and higher pressure for auditability and reproducibility.