

For most of the modern AI boom, text generation has had one very good trick: predict the next token, then do it again, and again, and again, until the machine either writes a sonnet or apologizes for being unable to help with your toaster. Diffusion language models ask a different question. What if language didn’t have to be generated like a typist moving left to right? What if a model could start with noise and gradually shape the whole sequence, the way today’s image models turn static into cats, castles, or suspiciously glossy startup logos?
That question has been floating around research labs for years. The annoying part is that text is not an image. Pixels live in a smooth numerical space. Words live in a vocabulary, which is more like a box of Lego pieces than wet clay. MIT’s new paper, Embedded Language Flows, from Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, and Kaiming He, takes the Lego problem seriously and proposes a surprisingly clean answer: keep language continuous for almost the entire generation process, then turn it back into tokens only at the end. The paper frames ELF as a continuous diffusion model built in embedding space using continuous-time Flow Matching, with a shared-weight network handling final discretization.
This matters because diffusion language models have often looked elegant on a whiteboard and awkward in practice. ELF is interesting not because it declares autoregressive models dead. It doesn’t. It’s interesting because it makes continuous text diffusion look much less like a research cul-de-sac and much more like a path worth paving.
Table of Contents
1. The Autoregressive Bottleneck: Why Language Needed A Diffusion Revolution
Autoregressive language models are wonderfully simple. Given a prefix, predict the next token. Add that token to the prefix. Repeat. This recipe scales, and history has been kind to recipes that scale. GPT-style models became dominant because next-token prediction is brutally effective, easy to train at internet scale, and naturally suited to streaming output one piece at a time.
But the same design has a built-in bias. The model commits early. Once it writes token 37, token 38 must live with that decision. Images and video models already enjoy a more global refinement style. They begin with noise and repeatedly improve the whole object.
| Generation Style | How It Works | Strength | Pain Point |
|---|---|---|---|
| Autoregressive LLM | Predicts one token after another | Scales beautifully and streams naturally | Hard to revise globally once tokens are emitted |
| Discrete DLM | Corrupts and restores tokens directly | Matches the discrete nature of text | Token transitions can be rigid and specialized |
| Continuous DLM | Denoises embeddings in a smooth space | Can borrow tricks from image diffusion | Must map smooth vectors back to words cleanly |
| ELF | Denoises embeddings, decodes only at the final step | Simple continuous path with no separate decoder | Still early compared with mature GPT-style systems |
The bottleneck is not that autoregression is bad. It’s that language generation has been trapped in one dominant shape. Diffusion language models offer another shape: generate by revision, not just extension.
2. What Diffusion Language Models Actually Change
Diffusion language models replace the left-to-right ritual with iterative denoising. Instead of asking, “What token comes next?”, they ask, “Given this messy sequence, what cleaner sequence should it become?” That small change opens a large design space.
In images, diffusion works because corruption and recovery are smooth. Add Gaussian noise to a photo, train a neural network to remove it, and the model learns the structure of the data. Do that repeatedly and noise can become a plausible image. For language, the same intuition is attractive. The model could refine an entire answer, code block, translation, or summary in parallel.
The trouble is that words are discrete. There is no halfway token between “cat” and “dog” in a vocabulary table, unless you enjoy semantic taxidermy. Token IDs are arbitrary labels, not coordinates in a meaningful geography.
So researchers have tried two broad routes. One keeps the process discrete and designs token-level corruption schemes. The other maps language into vectors and runs diffusion there. ELF belongs to the second camp, and it argues that the continuous route was not doomed. It just needed less ceremony.
Large language diffusion models also carry a practical promise: they may make some kinds of generation more parallel, more controllable, and less tied to token-by-token latency.
3. The Core Debate: Discrete Vs Continuous Diffusion
The phrase discrete vs continuous diffusion sounds like a graduate seminar topic designed to scare away normal people. The actual divide is simple.
Discrete diffusion treats tokens as tokens. A model might mask words, replace them, or push them toward a categorical distribution, then learn to reverse that process. Methods such as masked diffusion language models and Duo-style approaches live here. This is a natural fit for text because text is made of symbols. The model never has to pretend that token IDs are smooth.
Continuous diffusion treats tokens as entries into a vector space. The model embeds text, adds noise to those embeddings, and learns to denoise the vectors. This looks more like image diffusion, which is useful because the image world has built a rich toolkit for sampling, guidance, and flow-based generation.
The historical problem was the return trip. A vector can drift in a smooth space. A word cannot. Earlier continuous methods often had to keep checking back with token space through rounding losses, simplex constraints, or token-level supervision along the trajectory. ELF’s move is to stop asking too early. Let the model stay continuous. Let the flow do its work. Decode at the end.
4. Enter Embedded Language Flows
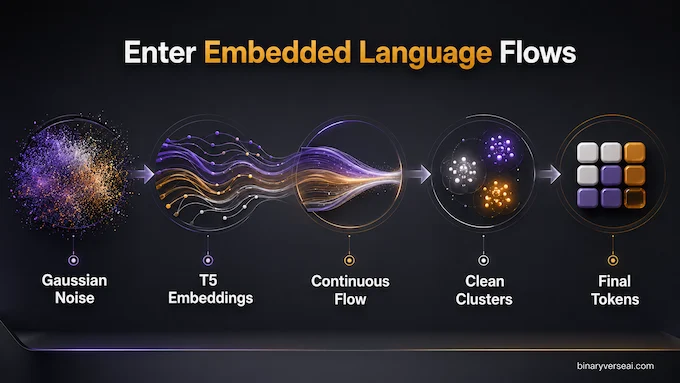
Embedded Language Flows starts with a pragmatic idea: use an encoder to turn discrete tokens into continuous embeddings, then train a flow-based model to move from Gaussian noise toward those embeddings. In the default setup, the authors use contextual embeddings from a frozen pretrained T5-small encoder. During generation, the model starts from noise, iteratively denoises in embedding space, and only at the final moment projects back to tokens.
That final moment is the trick. ELF does not keep discretizing throughout the trajectory. It does not force every intermediate state to look token-like. In the paper’s diagram, the process flows from a cloud of noise toward clean embedding clusters, and discretization happens only at time t = 1. This is a small design choice with large consequences: the model gets to behave like a continuous generative model for almost the entire computation.
This is why diffusion language models suddenly feel less awkward here. ELF is not trying to make language continuous in a metaphysical sense. It is making the working space continuous because the math and the optimization behave better there.
5. The “No Separate Decoder” Breakthrough
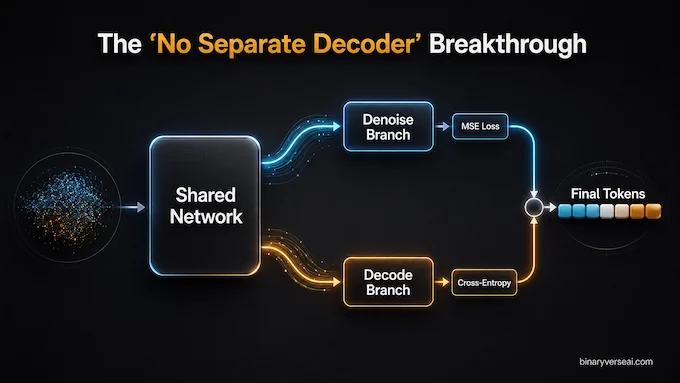
Latent diffusion models in vision usually need a decoder. They work in a compressed latent space, then use another model to turn that latent back into pixels. That design is powerful, but it adds machinery. For language, extra machinery can become a tax paid at training time, inference time, and debugging time, which is the tax nobody budgets for.
ELF avoids a separate decoder. The same shared-weight network denoises during most of the process and switches into decoding mode at the final step. During training, the network sees two branches: a denoising branch trained with a mean squared error objective, and a decoding branch trained with cross-entropy against the original token sequence. The authors state that this two-branch computation is batched, so it does not add extra training cost in the way a separately trained decoder pipeline would.
This is elegant in the engineering sense of the word. Not “look at this clever trick” elegant, but “one less moving part to babysit at 2 a.m.” elegant. The denoiser and decoder share weights, which keeps the system conceptually tight.
6. Flow Matching For Generative Modeling In Text
Flow Matching for generative modeling is the mathematical engine under ELF. The model learns a continuous path from noise to data. Instead of simulating a long Markov chain of tiny denoising steps, Flow Matching defines a velocity field: at any point in time, the model learns which direction the noisy representation should move to become data.
In ELF, the path is a linear interpolation between Gaussian noise and the clean embedding. If t = 0, you are noise. If t = 1, you are data. For values between, you are somewhere on the road. The model predicts the clean embedding, then converts that prediction into a velocity update. The paper emphasizes that this x-prediction setup fits high-dimensional embedding representations and aligns naturally with the final task of predicting clean tokens.
The nice thing about this formulation is that it makes text generation look structurally similar to newer systems used for images and videos. That does not make text easy. It does make text compatible with a toolbox that already works well elsewhere. Toolboxes compound.
7. Classifier-Free Guidance For Language

The killer feature may be classifier-free guidance, usually shortened to CFG. In image models, CFG is the knob that lets you trade diversity for prompt adherence and sample quality. Turn it up too far and the image may become overcooked. Use it well and the model snaps closer to what you asked for.
ELF can borrow CFG because its core quantities are continuous. That’s the whole point of staying in embedding space. The paper uses self-conditioning to create the conditioning signal and adapts training-time CFG techniques so guidance does not require two forward passes at inference. It also extends naturally to conditional generation, where clean prefix embeddings can condition the output.
For developers, this is not a decorative feature. A guidance knob for text could mean more direct control over generation quality, diversity, and faithfulness without retraining the model for every behavior. It could also help with structured outputs, translation, summarization, and code generation, where “creative freedom” is often a polite name for breaking the schema.
Diffusion language models have long promised controllability. ELF gives that promise a familiar interface.
8. The 10x Efficiency Marvel: Doing More With Less Data
For diffusion language models, benchmarks are where elegance meets the bill.
On unconditional generation with OpenWebText, ELF-B reaches a generative perplexity of about 24 using 32 sampling steps. The comparison includes discrete models such as MDLM and Duo, plus continuous models such as FLM and LangFlow. ELF does this without extra distillation, while some few-step baselines rely on additional distillation stages. The authors also report that ELF uses 45.2B effective training tokens, compared with more than 500B for several baselines in the system-level comparison.
| Result Area | ELF-B Reported Result | Why It Matters |
|---|---|---|
| Model Size | 105M parameters, plus a 35M T5 encoder used for embeddings | Competitive at a modest research scale |
| Unconditional Generation | Gen. PPL near 24 at 32 sampling steps | Strong quality with fewer steps |
| Training Tokens | 45.2B effective tokens | Roughly an order of magnitude less than compared baselines |
| Translation | 26.4 BLEU on WMT14 German-to-English | Beats listed similarly scaled baselines |
| Summarization | Best listed ROUGE scores on XSum | Shows the method works beyond free-form generation |
The conditional results matter too. ELF-B reports 26.4 BLEU on WMT14 German-to-English translation and leads the compared baselines on XSum summarization across ROUGE-1, ROUGE-2, and ROUGE-L. The paper’s qualitative examples show the model following context in translation and summarization, not just hallucinating stylish fog.
This does not mean ELF is ready to replace production LLM stacks. It means the old assumption, continuous text diffusion is too clumsy to compete, just took a dent.
9. Will Large Language Diffusion Models Replace GPT?
Not tomorrow. Autoregressive models have the advantages that matter in the real world: mature infrastructure, scaling laws, streaming generation, tool-use scaffolding, and years of hard-won systems work.
But replacement is the wrong question. The better question is where large language diffusion models might be the right tool. Parallel refinement could shine in editing, infilling, structured generation, constrained decoding, translation, summarization, and tasks where the model benefits from seeing the whole output evolve. If you’re generating JSON, a proof sketch, a plan, or a short program, the ability to revise globally is not a philosophical luxury. It’s the job.
Diffusion language models also invite a different mental model of reasoning. Autoregression says thought is a chain. Diffusion says thought can be a field that gradually settles. Neither metaphor is fully true. Both are useful. The field metaphor becomes tempting for tasks where early commitments are expensive.
ELF’s achievement is not that it beats GPT at everything. It doesn’t claim that. Its achievement is that it makes continuous diffusion for text feel technically credible, clean, and data-efficient enough to take seriously.
10. What To Watch Next
The next questions are obvious and hard, which is how you know the work is interesting.
First, scale. ELF-B, ELF-M, and ELF-L show improved generative perplexity and entropy frontiers as model size grows, but the open question is what happens when this family is pushed toward true frontier scale. The paper reports encouraging scaling across 105M, 342M, and 652M variants, with larger models improving the quality-diversity frontier.
Second, latency. Fewer sampling steps help, but diffusion-style generation still needs iterative refinement. Autoregressive decoding is slow in one way. Diffusion decoding is slow in another. The winner may depend on hardware, batching, sequence length, and whether future samplers can cut the step count without wrecking quality.
Third, controllability. CFG is a familiar knob, but text needs richer controls than images. Developers will want constraints, schemas, citations, safety filters, style control, and faithful grounding. If the continuous formulation makes those controls easier to express, diffusion language models could become very attractive in product settings.
Fourth, reasoning. A model that revises globally may handle some reasoning patterns differently from a model that commits token by token. That doesn’t magically create intelligence. It may create a better workspace for certain forms of search, correction, and consistency.
The practical takeaway is simple: don’t sell your GPUs and declare the autoregressive era over. Also don’t ignore ELF. The history of machine learning is full of ideas that looked awkward until the right formulation made them obvious in hindsight.
Embedded Language Flows feels like one of those formulations. It takes a hard boundary, continuous math versus discrete words, and moves the boundary to the only place it truly has to exist: the final output. That’s clean. That’s useful. And it gives researchers a better playground.
If you build with language models, keep an eye on this line of work. The next big leap in text generation may not come from making the typist faster. It may come from giving the model a draft, a workspace, and permission to revise before it speaks. You can explore the full ELF codebase on GitHub to dive deeper into the implementation.
What Are Diffusion Language Models (DLMs)?
Diffusion language models are AI models that generate text by starting with noise and gradually denoising it into readable language. Unlike GPT-style autoregressive models, which predict text one token at a time, DLMs refine larger parts of the output through repeated revision.
What Is The Difference Between Discrete And Continuous Diffusion In AI?
Discrete diffusion works directly on text tokens, such as masked or corrupted words. Continuous diffusion first maps text into a smooth embedding space, performs denoising there, and converts the final clean embeddings back into readable tokens.
How Does MIT’s Embedded Language Flows (ELF) Work?
MIT’s Embedded Language Flows, or ELF, maps text tokens into continuous embeddings using a frozen T5 encoder. It then uses Flow Matching to denoise those embeddings and converts them back into text only at the final generation step.
Does ELF Require A Separate Decoder Like Latent Diffusion Models?
No. ELF does not require a separate decoder. Its key design choice is a shared-weight network that handles both denoising and final decoding, which keeps the architecture simpler and avoids an extra inference component.
Can You Use Classifier-Free Guidance (CFG) On Text Generation?
Yes. Because ELF operates in continuous embedding space, it can use Classifier-Free Guidance much like image diffusion models. CFG helps control the trade-off between output quality, diversity, and generation behavior.