

AI launches now follow a familiar rhythm. One lab ships a shiny flagship, the internet crowns a winner, and then another team barges in with a model that is cheaper, stranger, and uncomfortably hard to ignore. Kimi K2.6 is that kind of release. Kimi K2.6 shows up with open weights, a 1 trillion parameter MoE architecture, native multimodal support, a 256K context window, and a very pointed message: serious agentic software should not cost a small fortune. More important, Kimi K2.6 is not selling only vibes. It is selling long-horizon coding, swarm orchestration, stronger tool use, and pricing that makes many premium workflows look absurd.
1. The Benchmark Reality, Before The Hype
The headline numbers are strong, and unusually broad. This model is not a one-trick exam machine. It posts competitive results in coding, agentic search, multimodal reasoning, and tool-heavy tasks that look a lot closer to software work than to benchmark cosplay.
| Benchmark | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max effort) | Gemini 3.1 Pro (thinking high) | Kimi K2.5 |
|---|---|---|---|---|---|
| HLE-Full, w/ tools | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| BrowseComp | 83.2 | 82.7 | 83.7 | 85.9 | 74.9 |
| BrowseComp, Agent Swarm | 86.3 | — | — | — | 78.4 |
| DeepSearchQA, F1 | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
| DeepSearchQA, Accuracy | 83.0 | 63.7 | 80.6 | 60.2 | 77.1 |
| WideSearch, item-F1 | 80.8 | — | — | — | 72.7 |
| Toolathlon | 50.0 | 54.6 | 47.2 | 48.8 | 27.8 |
| MCPMark | 55.9 | 62.5* | 56.7* | 55.9* | 29.5 |
| Claw Eval, pass^3 | 62.3 | 60.3 | 70.4 | 57.8 | 52.3 |
| Claw Eval, pass@3 | 80.9 | 78.4 | 82.4 | 82.9 | 75.4 |
| APEX-Agents | 27.9 | 33.3 | 33.0 | 32.0 | 11.5 |
| OSWorld-Verified | 73.1 | 75.0 | 72.7 | — | 63.3 |
| Terminal-Bench 2.0 | 66.7 | 65.4* | 65.4 | 68.5 | 50.8 |
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Multilingual | 76.7 | — | 77.8 | 76.9* | 73.0 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| SciCode | 52.2 | 56.6 | 51.9 | 58.9 | 48.7 |
| OJBench, Python | 60.6 | — | 60.3 | 70.7 | 54.7 |
| LiveCodeBench v6 | 89.6 | — | 88.8 | 91.7 | 85.0 |
| HLE-Full | 34.7 | 39.8 | 40.0 | 44.4 | 30.1 |
| AIME 2026 | 96.4 | 99.2 | 96.7 | 98.3 | 95.8 |
| HMMT 2026, Feb | 92.7 | 97.7 | 96.2 | 94.7 | 87.1 |
| IMO-AnswerBench | 86.0 | 91.4 | 75.3 | 91.0* | 81.8 |
| GPQA-Diamond | 90.5 | 92.8 | 91.3 | 94.3 | 87.6 |
| MMMU-Pro | 79.4 | 81.2 | 73.9 | 83.0* | 78.5 |
| MMMU-Pro, w/ Python | 80.1 | 82.1 | 77.3 | 85.3* | 77.7 |
| CharXiv, w/ Python | 86.7 | 90.0* | 84.7 | 89.9* | 78.7 |
| MathVision, w/ Python | 93.2 | 96.1* | 84.6* | 95.7* | 85.0 |
| BabyVision, w/ Python | 68.5 | 80.2* | 38.4* | 68.3* | 40.5 |
| V*, w/ Python | 96.9 | 98.4* | 86.4* | 96.9* | 86.9 |
A quick reality check matters here. The supplied benchmark sheet mostly compares against Claude Opus 4.6, while the market conversation has already moved to Claude Opus 4.7. So the clean takeaway is not “case closed.” It is this: the published numbers clearly put Kimi K2.6 in the frontier conversation, especially for coding and tool-augmented workflows.
| Model | Input Price | Output Price | Practical Read |
|---|---|---|---|
| Kimi K2.6 Best Value | $0.60 | $2.50 | Cheap enough for repeated agent loops and long coding sessions |
| Claude Opus 4.7 class pricing Premium Cost | $5.00 | $25.00 | Strong, but painfully expensive at scale |
| Premium closed-model stacks General Range | High | Very high | Great for demos, less fun when the invoice arrives |
Table of Contents
2. The 1T Architecture, Minus The Marketing Fog
A lot of model launches try to win the room with one enormous number. Here, the big number matters, but the active-parameter number matters more. That is the difference between a brag and a design choice. An MoE system only works if routing is disciplined enough that the model feels focused instead of fragmented. When that works, you get a system that can cover a wide surface area without dragging every ounce of capacity through every token.
Under the hood, this is a Mixture-of-Experts model with 1 trillion total parameters and 32 billion active parameters per token. That last part is the important one. You are not hauling the whole trillion into every step. You are activating a relevant slice. That is how the system stays huge without becoming instantly useless.
The rest of the stack tells a coherent story: 256K context, MLA attention, MoonViT for vision, 384 experts, 8 selected experts per token, and native INT4 quantization. In plain English, the design goal is breadth with stamina. Read a lot. Keep enough in memory. Use tools. Stay coherent. Keep shipping.
3. Kimi K2.6 Vs Claude Opus 4.7, The Question Buyers Actually Need To Ask
The comparison also exposes a deeper shift in the market. Closed models used to bundle two advantages together, better capability and fewer operational headaches. Open-weight models were cheaper, but usually came with caveats. You had to accept weaker coding, shakier tool use, or a lower reliability ceiling. Releases like this one start to break that bargain. You can now squint and see a future where “best available” and “best deployable” are no longer the same thing.
The lazy question is which model is “best.” The useful question is what kind of work you need to pay for.
If your workload is dominated by one-shot, high-stakes reasoning, the best closed models still have an argument. They often feel steadier at the ceiling. But once the work becomes iterative, tool-heavy, or agentic, cost starts shaping capability. That is where Kimi K2.6 gets sharp. It may not win every row in every table, but it makes ambitious multi-step workflows affordable enough to repeat. That changes the buying decision more than people admit on launch day. If you want a broader view of how leading models stack up for coding specifically, the landscape is shifting faster than most teams realise.
4. Run Kimi K2.6 Locally, Then Meet Physics
There is also a cultural point hiding inside the local-deployment obsession. Developers do not ask to run large models locally only because of cost. They ask because local control means privacy, tunability, offline use, and freedom from vendor mood swings. That instinct is good. It is one reason open-weight releases matter so much. But hardware is still the bouncer at the door, and this model arrives with a very strict guest list.
This is the section where dreams collide with memory bandwidth. In BF16, the weights land around 595 GB. Native INT4 helps, but you are still looking at roughly 297 GB. That is not “I have a decent gaming PC.” That is workstation or server territory.
So yes, you can run Kimi K2.6 locally. In the same sense that you can own a race car. Many people love the idea. Fewer enjoy the maintenance bill. For most builders, API access is the sane path. Open weights still matter, because control and deployment choice matter. They just do not repeal VRAM. The full model weights are available on Hugging Face for anyone who wants to inspect the architecture or attempt a local deployment.
5. Kimi K2.6 Hardware Requirements, In Human Language
You need a lot of memory, a lot of bandwidth, and a high pain tolerance for hardware invoices. A top-end shared-memory Mac setup is plausible. A serious multi-GPU rig is plausible. A normal desktop is not.
That is not a flaw. It is actually a sign of maturity. Open models used to arrive with an implied footnote, “pretty good, considering.” This release drops the apology. The conversation is no longer whether open weights can matter. The conversation is whether your infrastructure budget can keep up. For teams weighing the broader TPU vs GPU hardware decisions that underpin inference at scale, this is exactly the kind of model that sharpens that decision.
6. Agent Swarm AI, The Part That Feels Like A Real Product Idea
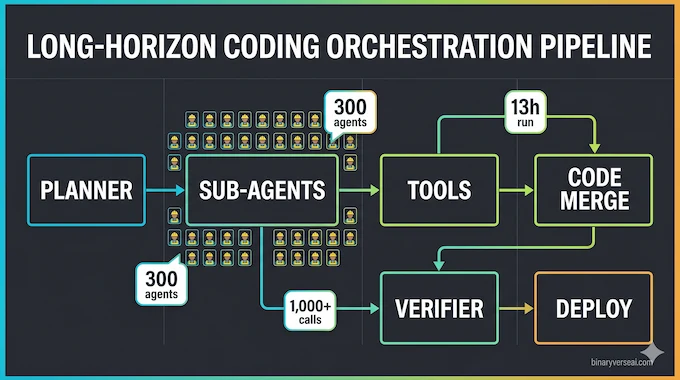
There is a reason this feature lands harder than yet another “smarter assistant” claim. Software work is already a swarm activity. A codebase is one conversation, a ticket queue is another, and the runtime environment is usually holding a third conversation in the background, often in the form of smoke and sirens. A single monolithic assistant is often too blunt for that. Coordinated sub-agents are not guaranteed to solve it, but at least they fit the shape of the problem.
Most “agent” claims in AI sound like pitch-deck fog. Here, at least, the claim is concrete: up to 300 sub-agents and about 4,000 coordinated steps in one autonomous run.
That matters because agent swarm AI is one of the few ideas in the field that actually changes the interface. Instead of forcing one model to cosplay as planner, coder, critic, researcher, and PM all at once, you split the work into specialized threads and coordinate them. Done badly, this becomes chaos with extra steps. Done well, it becomes a force multiplier.
The examples in the supplied material are ambitious enough to be interesting: long-running code optimization, spreadsheet generation, document production, research synthesis, and persistent operational work. Marketing examples are always polished within an inch of their lives, of course. Still, the direction feels right. The future probably belongs less to one heroic chatbot and more to systems that manage many narrower loops well. Anyone already exploring ChatGPT agent use cases will recognise the same underlying logic at work here.
7. The Benchmaxxing Debate, And Why The Better Test Is Boring
This is also where the SWE-Bench Pro open source conversation gets more interesting than the leaderboard itself. Developers do not care about one heroic benchmark score in the abstract. They care whether a model can inspect a codebase, reason across files, avoid fake fixes, and stay productive long enough to be worth handing real work. That is why the coding rows in the table feel more consequential than the flashier reasoning numbers.
Skepticism is healthy. Benchmarks can flatter a model. Prompt setups can be tuned. Vendors can cherry-pick. No serious reader should turn off that instinct.
But skepticism should have standards. The better question is whether the system can sustain useful work over time. Can it stay on task through long coding runs? Can it use tools without wandering off into decorative nonsense? Can it recover when a plan fails? Those are duller questions than leaderboard drama, and far more important.
That is why the long-horizon examples matter more than the most flattering row in the table. They suggest the system is being optimized for operational coherence, not just benchmark cosmetics.
8. Coding-Driven Design, A Quietly Big Deal
Front-end work has always been oddly underrepresented in AI discourse. Everyone loves to talk about theorem-solving and competitive coding. Fewer people talk about the far more common task of making software feel coherent. Layout, interaction, animation, state transitions, sensible defaults, visual hierarchy, database glue, and the thousand tiny decisions that determine whether a product feels cheap or deliberate. Any model that can help with that is working on a harder problem than many benchmark charts admit.
One of the smartest parts of the positioning is the focus on coding-driven design. The model is presented not only as a code generator, but as something that can turn prompts and visual inputs into polished interfaces, richer front ends, and lightweight full-stack flows.
That matters because the boring future of AI software is endless mediocre CRUD. The interesting future is faster iteration on taste, interaction, and implementation at the same time. If a model can reason about code, structure a UI, wire basic data flows, and keep going across a long task, it becomes much more valuable to small product teams than a collection of narrower tools handing each other broken artifacts. For teams comparing LLM pricing before committing to a stack, the economics of this kind of iterative, design-heavy work add up fast.
9. Kimi K2.6 API Pricing, The Most Important Line Item In The Whole Story
The economic story gets even sharper when you think like a product owner instead of a benchmark fan. A model is not just a unit of intelligence. It is a meter running in the background of every feature you ship. The minute your assistant starts browsing, writing code, calling tools, retrying failed actions, or maintaining long context, token pricing stops being trivia. It becomes product design.
Pricing is where the release stops being impressive and starts being disruptive.
At about $0.60 input and $2.50 output, Kimi K2.6 is priced to be used, not admired. Compare that with premium pricing around $5 input and $25 output, and the difference is not cosmetic. It changes what kinds of products make sense. Agentic systems retry. They branch. They search. They hit dead ends. They recover. If every recovery feels expensive, your “autonomous workflow” is really just a luxury demo with good branding.
This is the real attack on premium closed models. Not moral purity. Not open-source romance. Basic economics. The Moonshot AI team announced the release details on X, including the pricing structure and swarm mode capabilities that underpin this argument. You can use a live LLM cost calculator to run the numbers against your own token volumes before making a stack decision.
10. The License Question, And The Bigger Signal Beneath It
There is a second layer to this. License debates are often really trust debates. Teams are asking whether they can build on a model today without discovering six months later that the rules changed, the interpretation narrowed, or the commercial reality became inconvenient. That anxiety is rational. It is the tax the industry now pays for years of creative language around openness.
The modified MIT license will raise eyebrows, and it should. Developers have learned the hard way that “open” can mean several different things depending on who is selling it.
So yes, commercial teams should read the license carefully. But the larger signal is already visible. Open-weight releases are no longer content to be the noble alternative. They want to compete head-on in coding, multimodal work, agent orchestration, and production economics. That is a much bigger development than one more license debate. Anyone watching the broader agentic AI tools and frameworks landscape will see this pattern playing out across multiple releases simultaneously.
11. Final Verdict, Should You Change Your Stack?
One of the easiest mistakes in AI is treating model launches like sports results. Win, lose, next headline. But infrastructure decisions do not work that way. They are about fit, repeatability, and what your team can afford to operationalize without drama. In that sense, this release is less a knockout punch and more a very sharp wedge. It forces teams to ask whether they are paying for actual advantage or simply paying for a familiar logo.
If you only care about the calmest possible answer to a brutal one-shot reasoning problem, the best closed model of the week may still be worth the premium. But if you are building systems that search, code, iterate, recover, and keep going, Kimi K2.6 deserves serious attention. For context on how it fits against other recent open and closed model releases, the gap between open-weight and closed-source capability is narrowing in ways that matter operationally.
That is why this release matters. It makes open weights feel strategically relevant again. Not as a hobbyist badge. As an infrastructure choice. Test it against your actual workflows. Price the loops honestly. Then ask the only question that matters: is your current stack truly better, or just more expensive?
Can I run Kimi K2.6 locally on my PC or Mac?
Not realistically on a normal consumer machine. Moonshot’s own deployment guide shows TP8 on a single H200 node for both vLLM and SGLang examples, and the Hugging Face release is split into 64 safetensor shards, most around 9.81 GB, which puts self-hosting firmly in enterprise-hardware territory.
Is Kimi K2.6 actually better than Claude Opus 4.7 and GPT-5.4?
The careful answer is not proven head-to-head by Moonshot’s official table. Moonshot’s benchmark blog compares K2.6 against Claude Opus 4.6, not 4.7. Independent tracking still places K2.6 near the frontier, so the safest snippet wording is that K2.6 is competitive and far cheaper, while GPT-5.4 and Opus 4.7 remain safer choices for absolute peak reasoning.
How much does the Kimi K2.6 API cost?
The current official pricing shown by Moonshot is $0.95 per million input tokens, $4.00 per million output tokens, with $0.16 cache-hit input pricing. If you still see $0.60 / $2.50 in the SERPs, treat it as stale or provider-specific, not the clean official number to publish today.
What is the Modified MIT license for Kimi K2.6?
It is mostly permissive MIT-style licensing, but Moonshot added one important commercial condition: if a commercial product using K2.6 or derivative works exceeds 100 million monthly active users or $20 million in monthly revenue, the UI must prominently display “Kimi K2.6.” That is more precise than saying it has vague “commercial attribution” rules.
Are Kimi K2.6’s benchmark scores just benchmaxxing?
Skepticism is fair, but Moonshot is not relying only on benchmark tables. The official blog also cites a 12+ hour, 4,000+ tool-call Mac optimization run, a 13-hour, 1,000+ tool-call overhaul of an old financial matching engine, and a separate 5-day autonomous engineering worklog. That does not prove every benchmark claim, but it does strengthen the case for real long-horizon behavior.