

Three months. That’s all the time Google needed between Gemini 3.0 and Gemini 3.1 Pro. If the release cadence feels disorienting, that’s because it is. We’re not in the era of annual model refreshes anymore. We’re in something closer to a sprint with no finish line in sight, and Gemini 3.1 Pro is the latest proof that Google isn’t here to play catch-up. If you’ve been following AI news and model releases or tracking the best LLMs for coding in 2025, this one demands your attention.
The core claim is bold: Google took the heavy-duty compute that powered Deep Think mode, the kind previously reserved for the model’s extended reasoning ceiling, and baked it into the standard baseline. The result isn’t just an incremental upgrade. It’s a model that thinks harder by default, costs the same to run, and in several key benchmarks, beats everything else in its tier.
Let’s dig in.
Table of Contents
1. The Gemini 3.1 Pro Drop: Why the AI World Is Experiencing Whiplash
When Gemini 3 Pro launched in November 2025, it was already a strong performer. By February 2026, Google shipped Gemini 3.1 Pro, a direct successor that doesn’t just fine-tune the edges but fundamentally upgrades the reasoning core. The marketing line is that 3.1 Pro represents “a step forward in core reasoning,” but the benchmark data makes that sound modest by comparison.
The real story is architectural philosophy. Google made Deep Think mode’s reasoning compute the new floor, not the ceiling. That’s a meaningful choice. It means every call to Gemini 3.1 Pro gets access to better chain-of-thought infrastructure, whether you’re debugging a React component at midnight or synthesizing a 400-page policy document before a board meeting. Here’s a quick snapshot of where the model stands:
| Feature | Gemini 3.1 Pro |
|---|---|
| Model Code | gemini-3.1-pro-preview |
| Input Token Limit | 1,048,576 (1M) |
| Output Token Limit | 65,536 |
| Input Pricing (≤200k tokens) | $2.00 / 1M tokens |
| Output Pricing (≤200k tokens) | $12.00 / 1M tokens |
| Context Caching | Supported |
| Knowledge Cutoff | January 2025 |
| Custom Tools Endpoint | gemini-3.1-pro-preview-customtools |
2. The ARC-Agi-2 Leap: 77.1% and the End of “Pattern Matching”
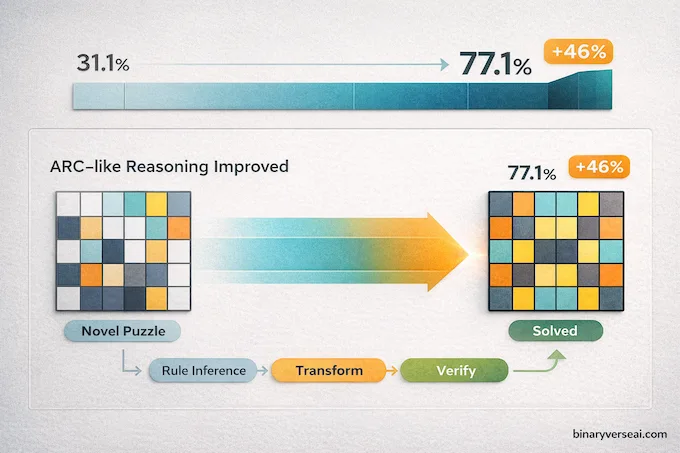
The number that stopped people cold was 77.1% on ARC-AGI-2. For context, Gemini 3 Pro scored 31.1% on the same benchmark. That’s not a marginal improvement. That’s more than doubling performance on one of the most meaningful tests in the field.
ARC-AGI-2 deserves a proper explanation because it’s often misunderstood. Unlike standard academic benchmarks where a model can succeed by memorizing training data, ARC-AGI-2 presents entirely novel logic puzzles. The grids, rules, and transformations are designed to be unseen. There’s no shortcut through pattern recall. A model either reasons through the problem or it doesn’t.
Going from 31% to 77.1% on that kind of benchmark, verified independently by the ARC Prize committee, is the kind of result that shifts how people think about what these systems can actually do. Gemini Deep Think mode was the driver here, and the full evaluation confirms it. Claude Sonnet 4.6 landed at 58.3%, Opus 4.6 at 68.8%, and GPT-5.2 at 52.9%. Gemini 3.1 Pro leads the field by a margin wide enough to matter.
This isn’t about claiming AGI. It’s about fluid, adaptable reasoning on tasks the model has never seen. That’s a meaningfully different capability than autocompleting the most statistically likely answer, and the gap is now visible in the numbers.
3. “Benchmaxxed” or Brilliant? Putting the Coding Benchmarks to the Test
The skepticism arrived on schedule. Within hours of the announcement, Reddit threads filled with comparisons, counter-claims, and the perennial concern that benchmark numbers are curated to tell a flattering story. So let’s actually look at what the data shows.
On SWE-Bench Verified (single attempt), Gemini 3.1 Pro scores 80.6%. Claude Opus 4.6 edges it out at 80.8%. Sonnet 4.6 follows at 79.6%. These models are genuinely close at the top of software engineering benchmarks, which tells you more about the state of the field than any one number. You can explore a more detailed SWE-Bench analysis across GPT-5, Claude, and Gemini here.
Where Gemini 3.1 Pro pulls ahead is LiveCodeBench Pro, a competitive coding benchmark drawing from Codeforces, ICPC, and IOI. Its Elo of 2887 against GPT-5.2’s 2393 is a substantial gap, not noise. On SciCode, Gemini 3.1 Pro hits 59%, compared to Sonnet 4.6 at 47% and Opus at 52%.
Real-world developer reports are more nuanced, as they tend to be. The consensus on clean React and Golang code is genuinely positive. Complex LaTeX rendering and intricate HTML integration? Still rough around the edges. The GDPval-AA Elo score of 1317 trails Sonnet 4.6’s 1633, suggesting there are still expert-task domains where Gemini 3.1 Pro hasn’t caught up. Honest reviewers will acknowledge both the wins and the gaps.
4. Gemini 3.1 Pro vs. Claude Sonnet 4.6: The Heavyweight Clash
Google benchmarked Gemini 3.1 Pro against Sonnet 4.6, not Opus 4.6. That’s a deliberate positioning choice. They’re not aiming for the high-cost frontier tier. They’re targeting the sweet spot where serious reasoning meets practical pricing, and they want developers to see Gemini 3.1 Pro as the smarter option at the same price point.
| Benchmark | Gemini 3.1 Pro Thinking (High) | Gemini 3 Pro Thinking (High) | Sonnet 4.6 Thinking (Max) | Opus 4.6 Thinking (Max) | GPT-5.2 Thinking (xhigh) | GPT-5.3-Codex Thinking (xhigh) |
|---|---|---|---|---|---|---|
| Humanity’s Last Exam (No tools) | 44.4% | 37.5% | 33.2% | 40.0% | 34.5% | — |
| Humanity’s Last Exam (Search + Code) | 51.4% | 45.8% | 49.0% | 53.1% | 45.5% | — |
| ARC-AGI-2 (ARC Prize Verified) | 77.1% | 31.1% | 58.3% | 68.8% | 52.9% | — |
| GPQA Diamond (No tools) | 94.3% | 91.9% | 89.9% | 91.3% | 92.4% | — |
| Terminal-Bench 2.0 (Terminus-2 harness) | 68.5% | 56.9% | 59.1% | 65.4% | 54.0% | 64.7% |
| Terminal-Bench 2.0 (Other best self-reported) | — | — | — | — | 62.2% (Codex) | 77.3% (Codex) |
| SWE-Bench Verified (Single attempt) | 80.6% | 76.2% | 79.6% | 80.8% | 80.0% | — |
| SWE-Bench Pro (Public) (Single attempt) | 54.2% | 43.3% | — | — | 55.6% | 56.8% |
| LiveCodeBench Pro (Elo) | 2887 | 2439 | — | — | 2393 | — |
| SciCode | 59% | 56% | 47% | 52% | 52% | — |
| APEX-Agents | 33.5% | 18.4% | — | 29.8% | 23.0% | — |
| GDPval-AA (Elo) | 1317 | 1195 | 1633 | 1606 | 1462 | — |
| τ2-bench (Retail) | 90.8% | 85.3% | 91.7% | 91.9% | 82.0% | — |
| τ2-bench (Telecom) | 99.3% | 98.0% | 97.9% | 99.3% | 98.7% | — |
| MCP Atlas | 69.2% | 54.1% | 61.3% | 59.5% | 60.6% | — |
| BrowseComp (Search + Python + Browse) | 85.9% | 59.2% | 74.7% | 84.0% | 65.8% | — |
| MMMU Pro (No tools) | 80.5% | 81.0% | 74.5% | 73.9% | 79.5% | — |
| MMMLU | 92.6% | 91.8% | 89.3% | 91.1% | 89.6% | — |
| MRCR v2 (8-needle) (128k average) | 84.9% | 77.0% | 84.9% | 84.0% | 83.8% | — |
| MRCR v2 (8-needle) (1M pointwise) | 26.3% | 26.3% | Not supported | Not supported | Not supported | — |
The picture that emerges is interesting. Gemini 3.1 Pro dominates on reasoning-heavy and agentic benchmarks. Sonnet 4.6 holds a clear lead on expert-task evaluation. For developers choosing an API, the question really comes down to what your workload looks like. If you’re building agentic systems, multi-step workflows, or long-context pipelines, Gemini 3.1 Pro’s profile is compelling. If you need consistent expert-level output across diverse domains, Sonnet 4.6 still earns its keep.
5. The Hallucination Drop: A Game Changer for Enterprise Adoption

One of the most practically important improvements in Gemini 3.1 Pro is the drop in hallucination rates. The official Gemini 3.1 Pro model card describes it as “more grounded, factually consistent,” and user reports back that up in ways that are harder to ignore than benchmark tables.
One example circulating in developer communities involves a user who uploaded a photo of a legal notice and asked Gemini 3.1 Pro to generate an appeal. The model returned a structurally sound, legally coherent response on the first attempt. No hallucinated citations. No invented procedural steps. Just clean, grounded output that the user described as immediately usable.
That kind of reliability is what enterprise adoption actually requires. A model that scores 80% on coding benchmarks but confidently fabricates API endpoints or legal precedents is not a production tool. Reduced AI hallucination rates, combined with the model’s grounding improvements and search integration, make Gemini 3.1 Pro a serious candidate for high-stakes workflows in legal, finance, and research contexts. The safety evaluations in the model card reflect consistent performance across text-to-text and multilingual safety policies, with improvements over Gemini 3.0 Pro on most dimensions.
6. Vibe Coding and Native SVGs: Gemini’s Underrated Visual Superpower
Buried under the reasoning benchmarks is a capability that deserves more attention: Gemini 3.1 Pro can generate website-ready, animated SVGs directly from a text prompt, built entirely in code.
This matters more than it sounds. A traditional approach to web animation involves video files, heavy GIFs, or JavaScript libraries that add latency and weight to your pages. SVGs built in pure code are resolution-independent, scale without degradation, and have file sizes that make video assets look embarrassing by comparison. Ask Gemini 3.1 Pro to animate a loading state, illustrate a data flow diagram, or build a branded visual element, and you get back clean, deployable code.
The spatial reasoning improvements underpinning this capability also show up in how the model handles complex visual explanations. Asking it to visualize a concept, synthesize scattered data into a coherent view, or bring a design brief to life produces output that’s meaningfully better than what Gemini 3 Pro could manage. It’s not flashy in a demo, but it’s the kind of thing that saves hours in real projects.
7. Under the Hood: Context Windows, Caching, and the Custom Tools API
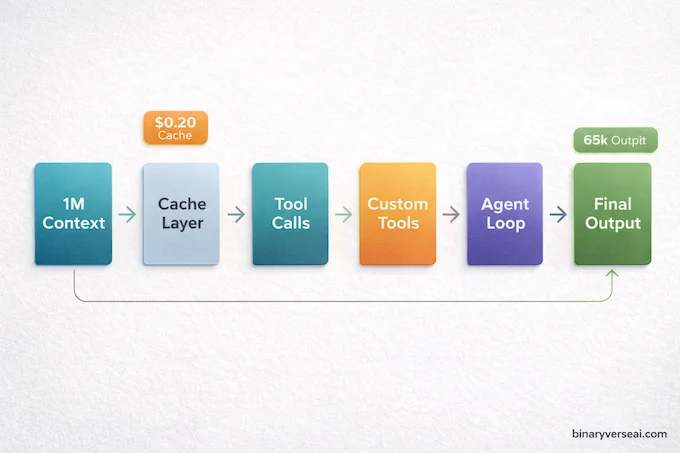
For the developers reading past the marketing, here’s what actually matters technically.
The context window sits at 1,048,576 tokens, roughly one million. That’s large enough to ingest entire codebases, lengthy research compilations, or multi-session conversation histories without truncation. Context caching is supported and priced at $0.20 per million tokens for prompts under 200k, which makes repeated calls against the same long document meaningfully cheaper over time.
The more interesting addition is the Gemini custom tools API endpoint. The standard model code is gemini-3.1-pro-preview, but there’s a separate endpoint specifically for agentic workflows that use a mix of bash and custom tools: gemini-3.1-pro-preview-customtools. This endpoint is tuned to prioritize your own tool definitions, whether that’s a view_file command, search_code function, or any other custom integration. If you’re building agentic AI systems and enterprise workflows, this endpoint is where you want to start.
Google is upfront that quality can vary in use cases that don’t benefit from tool-heavy workflows, so it’s not a universal replacement. But for the specific case of agentic software engineering, it’s a meaningful optimization that most competing APIs don’t yet offer with this level of explicit support.
8. API Pricing: Top-Tier Reasoning on a Budget
Let’s talk about the Gemini 3 Pro price question that’s driving a lot of search traffic, because it’s directly relevant here.
Gemini 3.1 Pro is priced at $2.00 per million input tokens and $12.00 per million output tokens for prompts under 200k tokens. For longer prompts, those numbers step up to $4.00 input and $18.00 output. Context caching drops the repeated-context cost to $0.20 per million tokens, with a storage rate of $4.50 per million tokens per hour. You can verify the full breakdown on the official Gemini API pricing page. For a broader comparison of costs across models, the LLM pricing comparison and LLM cost calculator at BinaryVerseAI are useful references.
That pricing structure makes Gemini 3.1 Pro attractive for high-volume applications. You’re getting better reasoning than Gemini 3 Pro at pricing that doesn’t demand a budget renegotiation. For developers building pipelines that process thousands of requests daily, the combination of improved grounding, the million-token context window, and competitive output pricing adds up to a genuinely different cost-performance equation than what was available six months ago.
9. The Elephant in the Room: UI Bugs, Missing Chats, and “Nerf” Fears
Being fair means acknowledging what’s broken. The Gemini web UI has issues. Users report missing chat history, sessions that don’t persist correctly, and forced personalization features that feel more like a product team’s OKR than a user request. These aren’t subtle inconveniences. For people relying on the web interface as a daily tool, they’re genuinely frustrating.
There’s also the familiar concern in the community about post-launch throttling. The pattern has happened before with other models, and users are watching carefully to see whether Gemini 3.1 Pro’s capabilities remain stable or whether quality quietly degrades in the weeks after launch. Google is shipping this as a preview with the explicit goal of gathering feedback before general availability, which is a reasonable approach but also means some instability is baked in by design.
The model itself is solid. The infrastructure around it still needs work. Those are separate problems, but it’s worth keeping both in view when evaluating whether to build on this today versus waiting for the GA release.
10. Frontier Safety: Is Gemini 3.1 Pro Safe from Misuse?
The model card’s Frontier Safety Framework results are worth reading carefully. Google evaluated Gemini 3.1 Pro across five risk domains: CBRN, cyber, harmful manipulation, machine learning R&D, and misalignment.
The headline finding: no critical capability level was reached in any domain. On CBRN, the model can surface accurate information but still falls short of providing the novel, complete instructions that would represent a meaningful uplift for bad actors. On cyber, capabilities increased compared to Gemini 3 Pro, and the model has reached the alert threshold, but it remains below the CCL. That distinction matters. Reaching an alert threshold triggers additional testing and mitigation work, which is exactly what happened here. Google deployed additional evaluations in this domain specifically because of the prior Gemini 3 Pro result.
On harmful manipulation, the maximum odds ratio for belief change was 3.6x compared to a non-AI baseline, identical to Gemini 3 Pro, and below the alert threshold. Child safety evaluations met required launch thresholds. The overall picture is a model that’s more capable than its predecessor in ways that require careful monitoring, and a safety process that appears to be taking that monitoring seriously.
11. Final Verdict: Has Google Reclaimed the AI Crown?
Probably not in every category, and that’s fine. “Who’s the best AI model” is increasingly the wrong question. The more useful question is: best for what?
Gemini 3.1 Pro is the best option for developers building agentic systems that need multi-step reasoning, long-context processing, and custom tool integration. It’s the right choice for enterprise teams where AI hallucination rates are a blocking concern. It’s a compelling pick for anyone doing high-volume API work where the pricing needs to make sense at scale.
The ARC-AGI-2 result at 77.1% is real and it’s significant. The reasoning improvements over Gemini 3 Pro are not incremental. The custom tools endpoint is a practical differentiator for agentic workflows. And the grounding improvements make this a more reliable partner for tasks where fabricated output isn’t just annoying, it’s unacceptable.
The web UI needs real work. The preview status introduces some instability risk. The GDPval-AA benchmark suggests there are still expert-task domains where Claude holds an edge.
But the underlying Gemini 3.1 Pro model, accessed through the API, is a monumental step forward in what mid-tier-priced reasoning looks like in 2026. If you’re building anything serious with AI this year, at minimum, run your evals against it.
Start with Google AI Studio. The preview endpoint is live. See what it does with your hardest prompts. You might be surprised.
Is Gemini 3.1 Pro actually better than Claude 4.6 Sonnet?
On paper, Gemini 3.1 Pro vs Claude 4.6 Sonnet is extremely close across major evals, with Gemini often leading on reasoning-heavy and agentic tool benchmarks. In day-to-day dev work, Gemini 3.1 Pro tends to shine when you need structured tool use, visual “vibe coding,” and long-context reasoning without jumping price tiers.
What is the ARC-AGI-2 benchmark and why does a 77.1% score matter?
The ARC-AGI-2 benchmark measures whether a model can solve new logic puzzles that look unlike its training examples. A move to 77.1% signals the model is doing more than pattern recall, it’s building flexible rules on the fly and adapting across tasks.
What is Gemini Deep Think mode, and why does it change results?
Gemini Deep Think mode is the heavier reasoning setting that spends more compute to plan, verify, and avoid shallow shortcuts. Gemini 3.1 Pro matters because it feels like Google pushed more of that “think first” behavior into the baseline, so you get stronger reasoning without having to fight the model into it every time.
What is the Gemini custom tools API, and when should I use it?
The Gemini custom tools API refers to the tool-first endpoint gemini-3.1-pro-preview-customtools, designed for agent workflows that mix bash-style actions and custom functions. Use it when your app depends on the model calling the right tool at the right time, especially in multi-step automation like “read file, edit code, run tests, summarize diff.”
How much does the Gemini 3.1 Pro API cost, and is it good value?
The standard headline pricing is $2.00 per 1M input tokens and $12.00 per 1M output tokens under the smaller context tier. The practical story is value: if Gemini 3.1 Pro reduces retries and lowers AI hallucination rates in your workflow, your real cost per successful task drops even when raw token prices look similar.