

Introduction
Most “feature selection” stories start the same way. You have a model, you have a mountain of inputs, and you suspect half of them are doing more harm than good. Then you open a paper, see “NP-hard,” and quietly decide you will just throw everything into the network and let SGD sort it out.
That works, until it doesn’t. Latency budgets tighten. Training bills arrive. Debugging becomes a scavenger hunt because every input is “kind of important.” And the worst part, you still do not know which signals are actually carrying the prediction.
I like Sequential Attention because it takes a classic idea, greedy forward selection, and drags it into the deep learning era without turning it into a fragile science project. The punchline is simple: pick features one by one, but re-score what “matters” after every pick, so redundancy gets punished and synergy gets a chance to show up. The paper’s critique is blunt: naive attention-style ranking can ignore a feature’s residual value, its marginal contribution conditioned on what you already selected, and that leads to redundant selections or missed “only useful in combination” signals.
That’s the promise of Sequential Attention. If you have ever stared at 10,000 inputs and wished for a subset that is smaller, faster, and still accurate, this is worth your time.
Table of Contents
1. Sequential Attention Explained In 60 Seconds
Sequential Attention is greedy feature selection that updates its notion of “importance” after every choice. Instead of scoring each feature once and locking in a static ranking, it keeps a running selected set, asks the model what still matters given that context, then takes the best next item and repeats.
| Question You Actually Have | Old Answer | Why It Breaks At Scale | What This Method Does Instead |
|---|---|---|---|
| “Which inputs matter?” | Rank features once, pick top k | Ignores redundancy and interactions | Re-scores after each pick, so importance is conditional |
| “Can I do greedy feature selection?” | Train and eval models for every candidate | Costs explode, O(kd) retrains | Learns importance logits inside the same training loop |
| “Will this work with deep nets?” | Use L1 or gates | Often brittle, lots of tuning | Adds a small mask and lets gradients do the work |
| “Is it interpretable?” | Maybe, if you trust saliency | Instance-wise scores can be noisy | Produces a global selection order you can inspect |
The key payoff is that you get a subset, not just a heatmap. You also get the order in which features were chosen, which is often more informative than the final set.
2. What Is Sequential Attention?
People overload the word “attention” like it is universal seasoning. So let’s be precise, and save you a bounce.
2.1 What It Is In This Article
Sequential Attention here means a subset selection method. You want k out of d candidates. The algorithm picks one candidate at a time, and each decision depends on what is already picked. The “attention” part is the scoring mechanism: trainable logits become importance scores, and a softmax turns them into a differentiable mask that scales unselected features.
One detail the authors emphasize is practical: instead of generating many instance-wise masks and then trying to aggregate them, they train one global mask and select from it. That trims overhead and cuts a lot of needless tuning.
2.2 What It Is Not
It is not FlashAttention. It is not “a sequential model” in the RNN sense. It is not a generic transformer trick.
The name shows up in older NLP contexts because people have long used attention as a way to rank things. This paper is narrower and more useful: attention is a tool for greedy selection, not the headline.
3. Why Feature Subset Selection Is NP-Hard
Subset selection blows up because combinations blow up. Choosing k from d gives you “choose d, k” possibilities, and that number gets silly fast. If d is 10,000 and k is 100, you are not searching that space. You are naming it, then walking away.
Deep nets make it worse in a specific way: the value of a feature is not a property of the feature. It is a property of the feature in context. A signal can be useless alone but crucial when paired with another signal. Sequential Attention is basically saying, stop pretending importance is absolute, make it conditional on the set you already built.
4. The Old Way: Greedy Feature Selection, And Why It Hurts
Classic greedy forward selection does something wonderfully honest. At step t, it tries each remaining feature, retrains or re-evaluates, and asks, “Which one improves loss the most if I add it?” Repeat until you hit k.
It also has an honest price tag. Training O(kd) models is not a footnote. It is a deal breaker for modern neural networks. The paper states this plainly, greedy forward selection can select high-quality features, but it is impractical at deep learning scale because it requires training O(kd) models.
Sequential Attention keeps the greediness and replaces the cost.
5. The Core Idea: Greedy Selection Powered By Attention Scores
Here’s the move: keep the greedy loop, but stop paying full price for marginal gain.
Instead of retraining d times at every step, you train one model that can fractionally consider all candidates at once. You introduce trainable variables w, one per feature, treat them as attention logits, softmax them over the unselected features, and multiply each input feature by its softmax weight. Then you take the feature with the largest learned weight, lock it in, and repeat.
In other words, Sequential Attention uses a differentiable mask as a cheap stand-in for “train d alternative worlds and measure the marginal gain in each.” It is a proxy, but it is a proxy you can afford.
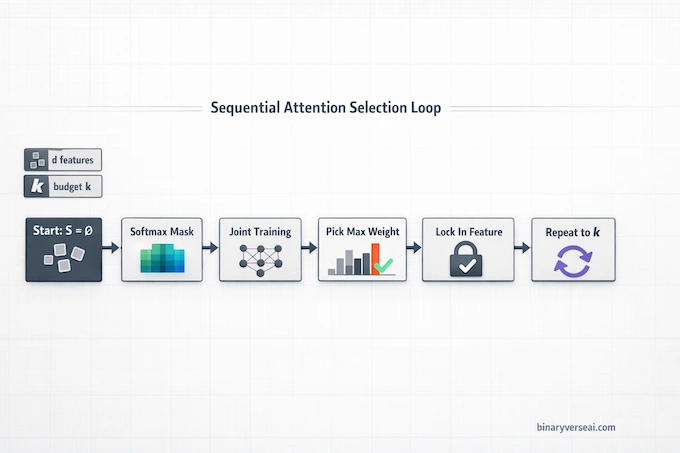
6. How The Sequential Attention Algorithm Works
Let’s walk through the sequential attention algorithm without turning it into a code dump.
6.1 Inputs And Outputs
Inputs: a dataset X with n examples and d features, labels y, a differentiable model f, a loss function, and a budget k. Output: a set S of k feature indices.
6.2 The Selection Loop
At each round:
- Maintain a selected set S, initially empty.
- Train the model parameters and the attention logits jointly, where selected features pass through as-is and unselected features are scaled by the softmax mask.
- Select the unchosen feature with maximum learned importance.
- Add it to S and continue until you have k.
The important detail is that the mask depends on S, so when S changes, the scoring changes. That adaptivity is the difference between picking “the top k correlated columns” and picking a set that actually cooperates.
6.3 The Practical Knobs
You still have choices. How long do you train per round? Do you stop early if gains flatten? How do you regularize logits so the model does not spread attention everywhere?
The paper includes a blunt, useful trick: instead of training k separate models for k rounds, you can train a single model and partition training epochs into k segments, selecting one feature per segment. That keeps overhead low while preserving the sequential behavior.
There is also a quiet win here: this approach adds only d extra trainable variables, not entire subnetworks. That is why it stays lightweight compared to several prior neural feature selection methods.
7. Why It Works In Practice: Conditional Importance And Redundancy Avoidance

The best mental model is “marginal gain, approximated.”
When you select feature A, the model can now explain part of the data. Some other feature B becomes redundant because B was mostly correlated with A. Since the algorithm re-scores after each selection, B’s importance tends to drop.
Flip it around. A feature C might look weak alone because the model cannot use it without context. After you select that context, C becomes valuable, and its score rises.
The paper sanity-checks this intuition directly on MNIST by comparing true marginal gains to the attention-based scores after selecting different numbers of pixels. The top-ranked regions remain similar, and the rankings correlate strongly early on, then degrade as selection progresses, which makes sense once the “obviously useful” features are gone.
This is the core advantage of Sequential Attention: it treats “importance” as conditional, not absolute.
8. Theory Corner: The OMP Connection
Greedy methods are popular partly because they feel intuitive, and partly because we like sleeping at night.
In linear regression, the authors analyze a variant that removes the softmax and adds L2 regularization, then show it is equivalent to Orthogonal Matching Pursuit. In a regime where we can prove things, the method inherits OMP-style guarantees.
One more subtle point matters for practice. In their analysis, the softmax is not the essential ingredient. The crucial piece is the Hadamard product overparameterization, the explicit “multiply features by learned weights” structure. They argue and test that swapping softmax for other normalized overparameterizations yields nearly identical performance.
So the theory is not saying “softmax is magic.” It is saying “this parameterization behaves like a greedy selector in a tractable setting.”
9. Implementation Notes You Actually Need
This is the part where a nice idea becomes a useful one.
9.1 Where To Integrate It
There are two sane places:
- Train-time selection. Run the selection loop while training, then train a final model on the chosen subset.
- Fine-tune-time selection. Start from a trained model and run selection as a structured adaptation step, useful when training is expensive.
Most teams start with train-time selection because it aligns the proxy with the training dynamics and keeps the mental model clean.
9.2 What To Log
If you want this to be more than a cool demo, log these:
- Selection order, not just the final set.
- Validation delta per step, a rough proxy for marginal gain.
- Stability across seeds, because any greedy method can be twitchy.
- The attention logits themselves, because they can tell you when the method is indecisive.
9.3 Sanity Checks
Three quick tests save you days:
- Random labels test. If you still get “confident” rankings, something is wrong.
- Redundancy test. Duplicate a feature and see if the selector wastes picks.
- Ablation against a plain baseline. If your fancy selection loses to a cheap filter, you have a bug or a mismatch.
10. Real Tradeoffs And Failure Modes

Marketing phrases like “without sacrificing accuracy” deserve a small trial.
Empirically, the paper reports that Sequential Attention is competitive with or better than several baselines on a benchmark suite of six datasets, selecting k = 50 features with a small one-layer ReLU network, and averaging results across multiple trials. It also scales to large data, for example the Criteo click-through rate dataset with 39 features and over three billion examples, where Sequential Attention outperforms other methods once you select at least 15 features and shows lower variance than LASSO-based selectors.
Still, there are real ways to fail:
- Proxy mismatch. Attention weights are a proxy for marginal gain. Proxies can lie, especially early in training.
- Not enough adaptivity. If you try to pick many features at once to speed things up, quality can drop. The appendix shows that selecting more features per round often hurts performance, with some dataset-specific exceptions.
- Selection overfitting. If you tune k and other knobs on the test set, you will “discover” a perfect subset that disappears in production.
There are also regimes where you should skip it. If d is small, wrapper greedy selection is fine. If your input pipeline already compresses signals into a handful of strong engineered features, the upside shrinks. And if you only need a quick ranking for interpretability, a simpler filter might be enough.
11. Where It Fits Beyond Feature Selection
Feature selection is the gateway drug. Once you get comfortable thinking in “pick a subset under a budget,” you start seeing subset selection deep learning everywhere.
The same sequential logic can be applied to bigger building blocks. That is where you see structured pruning and model pruning show up, because hardware likes structure, and deployment budgets are unforgiving. If you are shipping on accelerators, structured methods matter because they map to memory access patterns and kernels, not just a smaller number on a parameter counter.
This is also where you will hear the phrase ai model compression. It is a real problem and people pay real money for it. The useful framing is that compression often reduces to subset selection with constraints, and Sequential Attention is one way to do that selection without an absurd training bill. When you squint, you can treat Sequential Attention as a general-purpose subset selector that just happens to start with inputs.
| Subset Selection Target | What You Select | Why It Helps | Practical Gotcha |
|---|---|---|---|
| Input Features | Columns, embeddings, sensors | Cleaner generalization, faster inference | Nonlinear interactions can fool static rankings |
| Embedding Chunks | Dimensions or groups | Smaller footprint, lower memory | Easy to over-prune rare signals |
| Attention Heads Or Blocks | Structured groups | Real speedups on GPUs, TPUs | Needs hardware-aware structure |
| Weight Blocks | Block sparsity patterns | Better throughput, cache behavior | Tooling and metrics can lag reality |
If you are tempted to turn this into a “model compression guide,” resist. The interesting part is the selector. The applications are just where it earns rent.
12. Conclusion: What To Remember About Sequential Attention
If you remember three things, make them these:
- Sequential Attention is greedy feature selection that stays honest about context, re-scoring after each pick instead of assuming importance is fixed.
- It scales because it folds scoring into training, using a lightweight mask with attention logits instead of retraining thousands of models.
- It has a clean theoretical anchor in linear regression via an equivalence to OMP, plus strong empirical results in neural settings from small benchmarks to large-scale clicks.
If you are building models with too many inputs, or you are trying to ship something that fits into a real latency budget, give Sequential Attention a weekend. Implement the loop, log the selection order, and run the sanity checks before you celebrate.
Then do the part most people skip: read the selected features like a detective, not a tourist. If the algorithm picks something surprising, ask what it is compensating for. That feedback loop is where feature selection becomes an engineering tool, not a paper result.
1) What is sequential attention?
Sequential Attention is a greedy subset-selection method that picks features one at a time, then re-scores what’s left after every pick. That re-scoring makes it better at avoiding redundancy and catching “only useful in combination” signals than one-shot rankings.
2) What is meant by sequential learning?
Sequential learning is learning where order matters. The model updates over time as new data arrives or as it processes a sequence (tokens, events, time steps). It contrasts with “batch” learning where you train on a fixed dataset all at once.
3) What is meant by a sequential model?
A sequential model is built to process ordered inputs and carry information forward through steps. Examples include RNNs, LSTMs, GRUs, Transformers (in autoregressive mode), and temporal convolution models used for time series or language.
4) What does “sequential” mean in a neural network?
“Sequential” means the network (or procedure) processes things step-by-step with state or context from previous steps influencing the next step. In feature selection, “sequential” means each chosen feature changes what counts as “best next.”
5) What is the difference between model compression and model distillation?
Model compression is the umbrella goal: make a model smaller, faster, or cheaper (pruning, quantization, low-rank, etc.). Distillation is one technique: train a smaller “student” to match a larger “teacher” model’s outputs or internal signals.