

Introduction
Decoder-only models have been winning the popularity contest for a while. They are great at talking. You give them a prompt, they keep the autocomplete train rolling, and suddenly you have code, essays, or a questionable poem about GPUs.
Then Google ships T5Gemma 2, and it feels like someone walking into a room full of loud extroverts and saying, “Cool, but can we also read?”
That’s the real story here. This release is not “yet another small model.” It’s a deliberate return to the encoder-decoder architecture, upgraded with modern tricks from Gemma 3, and aimed at a practical future: on-device AI that can digest long documents, look at images, and respond quickly without a datacenter-sized carbon footprint.
If you’ve been wondering why the naming looks like a math problem, why the architecture matters, and whether it’s worth your time to run it locally, this is the walkthrough.
Table of Contents
1. The Return Of The Encoder-Decoder
For a few years, the industry mostly pretended there were only two kinds of language models: big ones, and bigger ones. And almost all of them were decoder-only. Predict the next token, repeat, profit.
The encoder-decoder family never went away, it just stopped being fashionable. It was the “serious” architecture you used for translation and summarization, the one that quietly did its job while the decoder-only models got the stage lights.
Now the stage lights are moving. T5Gemma 2 is Google DeepMind saying the encoder-decoder approach still has a real advantage, especially when the job is “read this whole thing, understand it, then answer.” The paper frames the goal plainly: strong multilingual, multimodal, and long-context capability in lightweight, open models, built by adapting pretrained Gemma 3 checkpoints with the UL2 objective.
If that sounds like a mouthful, good. We’re finally talking about capability per byte, not just capability per parameter.
2. T5Gemma 2 Vs. Gemma 3: Why Architecture Still Matters
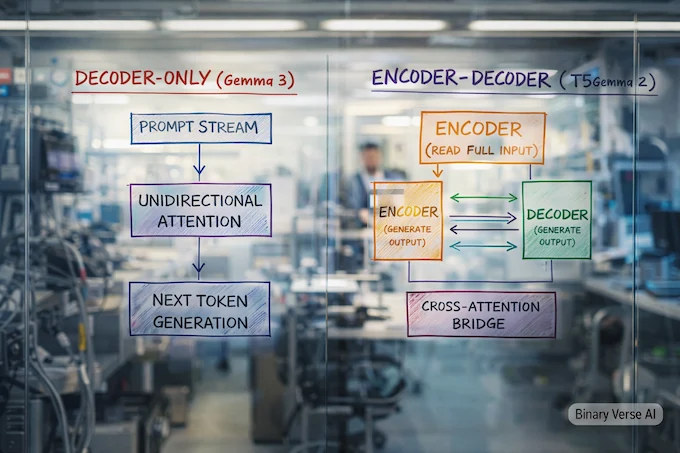
Let’s make the architecture difference feel tangible.
2.1 Decoder-Only Models: Great At Talking, OK At Reading
Decoder-only models are basically next-token engines. They can simulate reading by stuffing your entire prompt into a left-to-right stream, then generating from the end. They work, but the “reading” part is always entangled with the “talking” part.
2.2 Encoder-Decoder Architecture: Read First, Write Second
Encoder-decoder flips that mental model into something closer to how humans behave on a good day. The encoder reads the input with bidirectional attention, building a representation of the whole thing. The decoder then generates the output while attending to that representation.
The paper leans into this separation, especially for long context: the encoder gets full visibility over the input tokens, and cross-attention lets the decoder pull from higher-level representations instead of raw text soup.
This matters most when your prompt stops being “write a haiku” and becomes “here’s a 40-page contract plus a chart plus a screenshot, tell me what’s risky.” That’s where encoder-decoder starts to feel like the right tool, not the nostalgic one.
3. Decoding The “270M-270M” Naming Convention
If you’ve seen “270M-270M” and thought, “So… 540M?”, you’re not alone. The naming is shorthand: encoder size, then decoder size. The point is symmetry. The model isn’t a tiny encoder strapped to a giant decoder, it’s balanced.
Here’s the part that clears up most confusion: the total parameter budget depends on what you count. The paper breaks parameters into (1) a frozen vision encoder, (2) embeddings, and (3) the non-embedding encoder and decoder weights.
That split is why the smallest variant looks deceptively small on paper while still being genuinely capable in practice. It’s also why this family lands squarely in the “small language models” sweet spot: big enough to be useful, small enough to ship.
4. Key Innovation 1: Tied Embeddings That Actually Matter
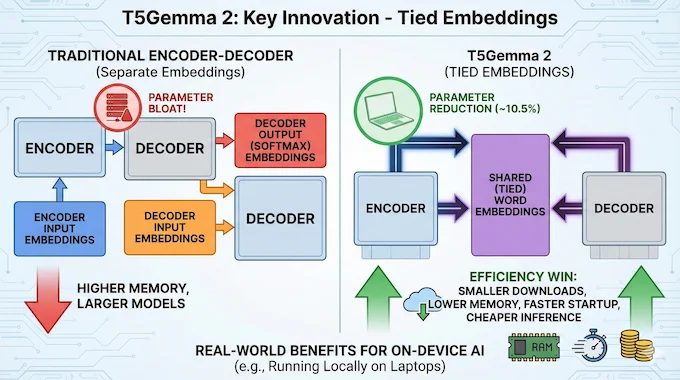
Embeddings are one of those unglamorous parts of models that can quietly eat your parameter budget, especially in smaller networks. Traditional encoder-decoder setups often keep separate embeddings for encoder input, decoder input, and decoder output (softmax).
T5Gemma 2 ties them together. One shared set of word embeddings across encoder and decoder, following the classic T5 idea. The authors report that this produces almost no quality change while reducing parameters by about 10.5%, which is a very real win when you care about on-device deployment.
This is the kind of efficiency trick that doesn’t show up in flashy demos, but shows up everywhere else: smaller downloads, lower memory, faster startup, cheaper inference.
If you’re trying to run LLM locally on a laptop, tied embeddings are not a trivia fact. They’re the difference between “it fits” and “it crashes.”
5. Key Innovation 2: The Merged Attention Mechanism
Encoder-decoder models have a historical reputation: strong at “read then write,” but slower and heavier than decoder-only at generation time. A lot of that comes from the decoder block structure, where you have self-attention and cross-attention as separate sub-layers.
The paper’s answer is the merged attention mechanism. Instead of treating self-attention and cross-attention as separate modules, it merges them into a single attention block with shared parameters, essentially narrowing the architectural gap between the decoder here and the decoder in Gemma 3.
The trade is refreshingly honest: merged attention saves about 6.5% of parameters, with a small average quality drop (around 0.3 points in their ablation). They call it an acceptable deal.
In other words, this is not magic. It’s engineering. You shave complexity, you keep most of the gain, and you get a model that’s easier to adapt from decoder-only checkpoints in the first place.
6. Native Multimodality: Seeing Through A Frozen SigLIP Encoder
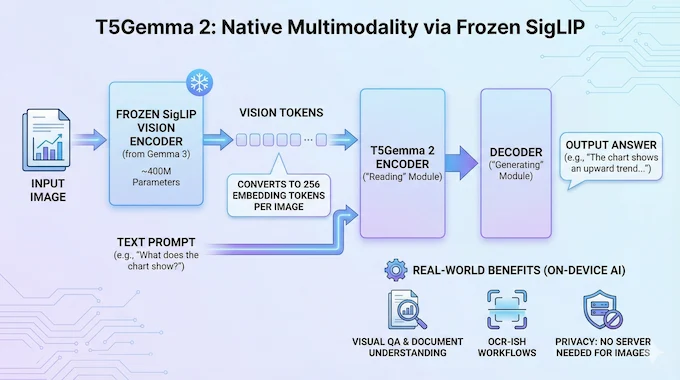
A lot of “multimodal” models still feel like text models wearing a vision hat. The hat works, but it’s obviously a hat.
Here, the setup is clean: the model reuses the same SigLIP vision encoder from Gemma 3, keeps it frozen, and feeds vision tokens into the encoder side so the “reading” module handles images too.
Two details are worth calling out because they translate directly into developer intuition:
- The SigLIP vision encoder is about 400M parameters.
- An image is converted into 256 embedding tokens before being processed.
That means the model treats images as first-class input, but in a way that still feels like language modeling: tokens in, meaning out.
This is exactly the design you want for multimodal AI models that need to run close to the user: visual question answering, document understanding, OCR-ish workflows, “what’s in this chart?” tasks, all without sending images to someone else’s server.
7. Long Context On The Edge: 128K Tokens Without The Drama
The most common lie we tell ourselves about long context is: “If the context window is big, the model will use it well.”
Reality is harsher. Many models technically accept long context but behave like they’re skimming, then hallucinate with confidence.
The paper argues encoder-decoder has a structural advantage here, and backs it up with results. They push to a 128K context window, even though the models were pretrained on much shorter sequences (up to 16K).
The key intuition is simple: the encoder can “see” the whole document with bidirectional attention, build a global representation, then the decoder generates while consulting that representation. That is a better mental model for long documents than “keep predicting the next token and pray the early sections stay in memory.”
If you care about on-device agents, local search over PDFs, or codebase-level prompting, this is the section of the release that should make you sit up.
8. Performance Benchmarks: What The T5Gemma 2 Benchmark Actually Says
Benchmarks are easy to misuse. They’re also hard to ignore, because they’re still one of the few ways to compare models without vibes.
The paper evaluates across five buckets: reasoning and factuality, STEM and code, multilingual, multimodal, and long context. Table 4 is the main pretraining snapshot, and it’s surprisingly readable once you stop trying to treat it like a leaderboard.
Here’s the headline: T5Gemma 2 tends to beat its Gemma 3 counterpart at the same scale on long context and often does well on multimodal, even when the base Gemma models at smaller scales were text-only.
If you’re coming in from the “Llama vs Qwen vs everyone” discourse, translate that into a more practical question: “Does this model do the jobs encoder-decoder is supposed to do, and does it do them efficiently?”
On long-context benchmarks, the gap is hard to miss. For example, on Ruler 128K, the 270M-270M variant is far above Gemma 3 270M (25.5 vs 4.4), and the 4B-4B variant reaches 57.6.
This is why the phrase “T5Gemma 2 benchmark” is not just SEO bait. The results line up with the architectural story.
T5Gemma 2 Model Sizes At A Glance
| Variant | Text Params (Emb + Enc + Dec) | Vision Encoder Params | Approx Total Params | Approx FP16 Weight Size | Who It’s For |
|---|---|---|---|---|---|
| 270M-270M | ~368M | 417M | ~785M | ~1.6 GB | Mobile-class experiments, edge prototypes |
| 1B-1B | ~1.70B | 417M | ~2.12B | ~4.2 GB | Serious local workloads, faster iteration |
| 4B-4B | ~7.09B | 417M | ~7.51B | ~15.0 GB | High-quality multimodal + long-context on a single beefy GPU |
Source parameter counts come from Table 2 in the paper.
(FP16 sizes are rough math: ~2 bytes per parameter, plus a little overhead in real life.)
9. Practical Guide: How To Run T5Gemma 2 Locally
Let’s get concrete. If your goal is to run LLM locally, the easiest path is usually Hugging Face Transformers.
9.1 The Short Path: Pipeline
Use this when you want a quick sanity check, not a production deployment.
from transformers import pipeline
generator = pipeline(
"image-text-to-text",
model="google/t5gemma-2-270m-270m",
)
out = generator(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
text="<start_of_image> in this image, there is",
generate_kwargs={"do_sample": False, "max_new_tokens": 50},
)
print(out)9.2 The Slightly More Serious Path: Processor + Seq2Seq
This is the version you’ll want if you plan to batch, tweak generation, or run on GPU.
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
processor = AutoProcessor.from_pretrained("google/t5gemma-2-270m-270m")
model = AutoModelForSeq2SeqLM.from_pretrained("google/t5gemma-2-270m-270m")
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "<start_of_image> in this image, there is"
inputs = processor(text=prompt, images=image, return_tensors="pt")
tokens = model.generate(**inputs, max_new_tokens=30, do_sample=False)
print(processor.decode(tokens[0]))A small but important workflow note: the encoder-decoder split often makes it easier to reason about prompt structure. Put all “reading” into the input, keep the output clean and specific. You’ll feel the difference when prompts get long.
Also, if you’re browsing the checkpoints, you’ll run into licensing gates. That’s normal for Gemma-family weights. On the T5Gemma Hugging Face pages, you typically need to accept the terms before downloading.
10. Post-Training Potential: Fine-Tuning, Quantization, And The GGUF Question
Pretraining gets you a capable base. Post-training is where models become useful tools.
The paper includes post-training results as an illustration and explicitly calls the tuning lightweight compared to Gemma 3. Even so, it reports that T5Gemma 2 outperforms Gemma 3 on most capabilities after this minimal post-training.
That’s a subtle but meaningful signal: encoder-decoder models often fine-tune nicely for tasks like summarization, translation, structured extraction, and domain-specific QA. The architecture naturally supports “condition on the input, generate the answer,” without forcing everything into a single autoregressive stream.
Now, the practical question everyone asks: quantization and GGUF.
- Quantization should be straightforward in principle because the weights are not exotic.
- GGUF and llama.cpp support depend on the community and tool maintainers catching up to this specific seq2seq, multimodal layout.
If your main goal is “run it everywhere,” keep an eye on toolchain support. If your goal is “get the job done today,” Transformers and a GPU will take you far.
11. Community Reception: What Developers Are Actually Saying
When models ship, the community response tends to split into three camps:
- People excited about capability.
- People confused about naming and usage.
- People asking, immediately, “Can I run this on my laptop?”
This release hits all three. The encoder-decoder comeback is genuinely interesting for researchers, but it also forces developers to remember that not every model is a chat-completion clone. You prompt it like a system that reads, then answers.
There’s also a privacy-shaped undertone to the excitement. The more competent these small language models get, the less you need to send sensitive inputs to remote APIs. Long documents, private screenshots, internal diagrams, it all becomes fair game for local inference.
And yes, there’s still the eternal question: “Is it better than Llama 3?” That’s the wrong framing. The right framing is: “Is this a better tool for input-heavy tasks?” The benchmarks suggest the answer is often yes, especially in long context and multimodal.
T5Gemma 2 Benchmark Highlights
| Capability | Metric | 270M-270M | 1B-1B | 4B-4B |
|---|---|---|---|---|
| Reasoning | HellaSwag | |||
| Code | HumanEval | |||
| Multilingual | XQuAD (all) | |||
| Multimodal | VQAv2 | |||
| Long Context | Ruler 128K |
All values are from the paper’s pretraining evaluation table.
12. Conclusion: The Future Of Small Language Models Is More Than Bigger Decoders
The easiest way to misunderstand this release is to treat it like a nostalgia project. It’s not. T5Gemma 2 is a bet that “read first, write second” will matter more as models move onto devices, into products, and closer to real inputs.
The encoder-decoder architecture is not trendy. It’s functional. It’s better aligned with tasks that look like: parse this, understand that, answer precisely. Add multimodality, add 128K context, keep it compact, and suddenly you have something that can live on laptops, workstations, maybe even phones, without turning every interaction into a cloud request.
If you build tools for real users, here’s the simplest next step: download the smallest checkpoint, run the image-text demo, then feed it something you actually care about. A PDF. A screenshot of a dashboard. A chunk of code with comments. See if the “reading” feel is different.
Then do the fun part: post what you learn. Share a notebook. Drop a benchmark. Write a short thread. The quickest way to understand T5Gemma 2 is to put it in contact with your own messy inputs and see if it stays honest.
If you try it, tell me what worked, what broke, and what surprised you. That’s how this ecosystem gets better, one real test at a time.
What is T5Gemma 2 and how does it differ from Gemma 3?
T5Gemma 2 is an encoder-decoder architecture model adapted from Gemma-era tech, while Gemma 3 is primarily decoder-only. The encoder reads the full input to build understanding, then the decoder writes the answer. That separation often helps with summarization, long documents, and multimodal AI models that mix images and text.
Is T5Gemma 2 an encoder-decoder model?
Yes. T5Gemma 2 is an encoder-decoder model in the T5 tradition. It keeps the “read then write” setup, but adds efficiency upgrades like tied embeddings and a merged attention mechanism so it stays practical at small language models sizes and for on-device deployment.
How can I run T5Gemma 2 locally on my device?
To run T5Gemma 2 locally, install the latest Transformers, then load the model with AutoProcessor and AutoModelForSeq2SeqLM from T5Gemma Hugging Face. Use FP16 for best quality if you have enough GPU memory, or quantize (8-bit or 4-bit) to fit smaller devices. Exact VRAM depends on dtype and overhead, but quantization is the easiest win.
What are the benefits of the merged attention mechanism in T5Gemma 2?
The merged attention mechanism combines decoder self-attention and cross-attention into a single unified block. That cuts parameters, reduces architectural complexity, and usually improves inference efficiency. In practice, it helps encoder-decoder models feel less “slow and heavy,” especially when you care about latency on local hardware.
Does T5Gemma 2 support image inputs (multimodality)?
Yes. T5Gemma 2 supports image inputs and text inputs, then generates text output. It uses a SigLIP-based vision encoder so it can do vision-language tasks like visual question answering, document understanding, and chart or screenshot interpretation. This makes it a strong fit for multimodal AI models that need to work privately on-device.