

Prompt Injection Prevention, Security vs Utility, CaMeL vs Undefended
Task completion and provable security coverage, based on the CaMeL research results
Source: “Defeating Prompt Injections by Design”, CaMeL, arXiv:2503.18813.
You know that feeling when your agent demo looks perfect, then it reads a “helpful” web page and tries to email your financials to a stranger named Bob, who does not work at your company. That is the core problem. Agentic systems are brittle in the wild. If we want real AI agent security, we need prompt injection prevention that holds up when the inputs are messy, adversarial, and fast changing. This post is a practical field guide, grounded in recent research and hard lessons from live incidents, for anyone asking how to harden AI agents without turning them into museum pieces.
Table of Contents
1. The Problem: Prompt Injection Is A System Issue, Not A Slogan
Prompt injection is simple to describe and stubborn to kill. A model ingests untrusted content, it finds an instruction hidden inside, then follows it. Direct prompt injection says “ignore previous instructions.” Indirect prompt injection hides the payload inside a PDF, a web page, a calendar invite, or a tool result. Most failures do not look cinematic. They look like one subtly wrong argument passed to a tool.
Many teams start with band-aids. “Remind the model to be safe.” “Put untrusted text between delimiters.” “Ask it to verify its own plan.” These tricks help on happy paths. They do not survive creative inputs at scale. You need system design that treats prompt injection prevention as a first-class requirement, the same way classic software treats input validation and control flow integrity.
2. The Adversary Has Agents Too

Attackers moved from copy-paste scripts to agentic playbooks. We see campaigns that use models to triage stolen data, generate convincing extortion notes, and adapt messages to each target. Less skilled actors ride this wave, because modern tooling lowers the bar for complex operations. That matters for defenders because it changes tempo. Your detection, response, and hardening loops need to keep up. Prompt injection prevention is no longer a research curiosity. It is table stakes for any workflow that touches untrusted content and tools.
3. The Breakthrough: Design For Safety With Google CaMeL
The best recent idea comes from the CaMeL framework, short for Capabilities for Machine Learning, which treats prompt injection prevention as a systems problem. The core move is to separate control flow from data flow, then enforce what may pass into each tool at execution time. In evaluations, CaMeL completed 77 percent of AgentDojo tasks with provable security, compared to 84 percent for an undefended system, which is a good trade when you care about safety by design.
3.1 The Dual LLM Pattern, Instantiated
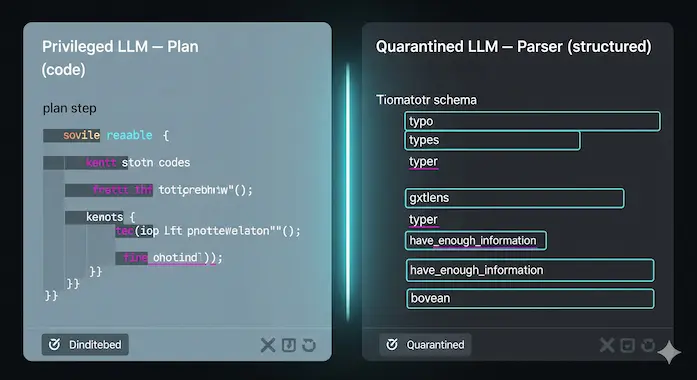
CaMeL makes the dual LLM pattern concrete. A Privileged LLM sees only the trusted user request. It writes the plan, as code, without ever peeking at untrusted data. A Quarantined LLM parses untrusted content into structured fields, and it cannot call tools. So injected text cannot hijack tool execution directly. This clean split is the backbone for prompt injection prevention that holds under pressure.
Yet separation alone is not enough. An attacker can still steer the arguments that flow into tools, which can be just as damaging. CaMeL addresses that gap by making security a property of values, not just prompts.
3.2 Capabilities And Policies
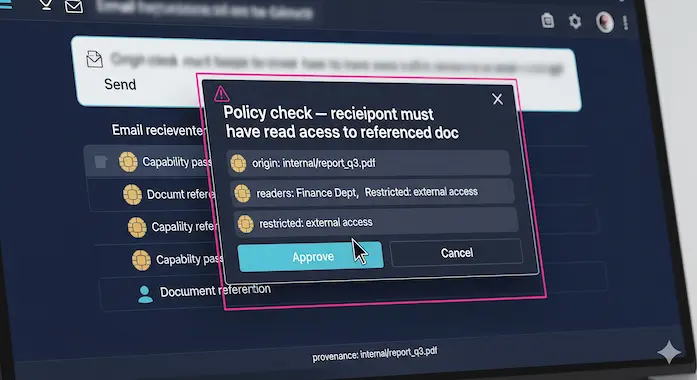
Every value in the plan carries a capability, a little passport that records where the data came from and who is allowed to see it. Before any tool runs, a policy checks those passports. For example, an email-sending policy can require that recipients already have read access to a referenced document. Policies are simple Python functions; they can gate specific tools, and they can be as strict as your environment demands. This is the heart of robust prompt injection prevention because the guard lives at the tool boundary, where harm happens.
3.3 An Interpreter That Tracks Data Flow
The CaMeL interpreter executes the Privileged LLM’s code, builds a dependency graph, and enforces policies at each tool call. The Quarantined LLM helps parse untrusted blobs into typed fields, which keeps the plan crisp and auditable. No model surgery required. That makes adoption far easier than retraining or fine-tuning for every edge case.
4. A Practical Playbook For Prompt Injection Prevention
You want something you can ship next week. Here is a no-nonsense playbook, tuned for teams building agents with tool access.
4.1 Separate Control And Data
Have one component that writes the plan, and a different one that parses untrusted content. Do not let the planner see untrusted data. Do not let the parser call tools. This structural decision gives you a place to anchor prompt injection prevention without awkward prompt gymnastics. It also helps with audits, since you can log plans and parser outputs independently.
4.2 Enforce Capabilities At Tool Boundaries
Tag values as they enter the system. Record provenance, allowed readers, and any special restrictions. Create tight policies for high-risk tools like file send, payment, external HTTP, and code execution. Fail closed. Ask for user confirmation if a policy would be violated. This is the one place where a small amount of friction pays for itself many times over.
4.3 Use Structured Outputs For The Parser
The Quarantined LLM should return structured outputs for the parser, not prose. Define minimal schemas, add a “have_enough_information” flag, and retry only through the planner. This defeats a whole class of indirect prompt injection tricks and keeps your dependency graph sane.
4.4 Whitelist Tools Per Task
Grant the minimum set of tools required for the plan. If the user asks for a calendar change, the agent does not need file deletion, repository push, or a network fetch. This dramatically reduces the blast radius when something slips past your first layers of prompt injection prevention. Implement a per-task tool whitelist.
4.5 Require Human Approval For High-Impact Actions
Anything with money, deletion, external sharing, or secrets gets a checkpoint. Keep the approval compact and contextual, show provenance, and log the decision. You will catch mistakes and attacks, and you will build trust with auditors.
4.6 Build Observability That Survives Incidents
Log the plan, the parser schema and outputs, the tool inputs, the tool results, and every policy decision. Store capability tags alongside values in your data lake. This supports both live monitoring and forensics. If you want lasting prompt injection prevention, you need eyes.
4.7 Red Team Regularly, Then Fix The Controls
Test direct prompt injection and indirect prompt injection across your top 20 workflows. Use red team content that looks like the wild: web reviews, meeting notes, financial summaries, and vendor emails. When you find issues, fix the plan, the schema, or the policy, not just the prompt.
5. Threats To Controls Mapping
One table you can keep near your runbook.
| Threat | Typical Symptom | Primary Controls | Notes |
|---|---|---|---|
| Direct prompt injection | Model says it will ignore instructions, or rewrites the plan | Planner isolation, plan logging, policy checks at tools | Keep the planner blind to untrusted content. |
| Indirect prompt injection | Wrong arguments passed to a tool | Quarantined parser, typed schemas, capability checks | This is where most real issues hide. |
| Data exfiltration via tool call | Unintended sharing or network fetch with secrets | Capability readers, “public vs specific recipients” policies | Make sharing explicit. |
| Tool misuse | Unexpected tool gets called | Per-task tool whitelist, strict policy on high-risk tools | Fail closed. |
| Memory poisoning | Old notes steer a new action | Provenance tags, freshness checks, human approval for sensitive actions | Treat memory as untrusted unless explicitly tagged. |
| Side channels | Information leaks through counts or timing | Strict dependency mode, block derived state-changing calls after parser decisions | Design for noisy channels, not perfection. |
Prompt injection prevention is a portfolio, not a silver bullet. The more of these you turn on, the less exciting your incidents will be.
6. Implementation Notes That Pay Off
6.1 Keep The Plan Small And Deterministic
Short plans are easier to audit and harder to subvert. Make the planner write explicit steps, not loops over unknown data sets, unless you really need them. Deterministic plans simplify policy reasoning and improve the quality of your prompt injection prevention.
6.2 Design Schemas To Minimize Parser Power
If the only valid output is an email address and a filename, then define a schema that allows exactly that. Avoid free text. Add a boolean like “have_enough_information,” which lets the system retry the plan without giving the parser a chance to sneak suggestions back into planning.
6.3 Policies As Code, Reviewed Like Code
Express policies as simple functions. Keep them versioned, code reviewed, and tested. Start with high-value ones: send_email, external_http, transfer_money, write_file, run_code. The discipline matters more than any single rule.
6.4 Think In Values, Not Strings
Capabilities travel with values. If you split a document into chunks, the chunks inherit the document’s readers and provenance. If you compute a summary, the summary’s capability should reflect its inputs. This mindset shift is central to robust prompt injection prevention.
7. Limits, Honestly Stated
No system stops every failure mode. CaMeL’s guarantees target actions at the tool boundary. It does not try to stop text-only misinterpretations that never touch a tool. In tests, separation plus policies drove the attack success rate near zero, and the remaining “wins” were outside the threat model, such as simply printing a malicious review back to the user. The important part is that the model did not send money or leak files because those actions were gated by policies.
Side channels exist. If a loop runs N times based on a private value, a remote counter may infer that N. A strict dependency mode can reduce this class of leaks by treating control conditions as data dependencies for policy checks. That mindset lets you block or confirm risky operations that would otherwise leak through behavior, which strengthens your overall prompt injection prevention posture.
8. Strategy For Teams Getting Started
- Pick one agent that touches untrusted data and one high-risk tool.
- Split planner and parser. Give the parser structured outputs only.
- Add two policies, send_email and external_http, and run with confirmation prompts.
- Tag values with provenance and readers. Log everything.
- Red team for prompt injection and indirect prompt injection across three realistic tasks.
- Fix the plan, the schema, or the policy, not just the wording of your prompt.
- Repeat for the next agent.
This sequence takes you from slogans to concrete prompt injection prevention inside a sprint or two. It also sets up a foundation you can extend across your stack.
9. Where This Leaves Us
We do not need to beg the model to be good. We can make the system safe by construction. Google CaMeL shows a clear path, separate control and data, track provenance, and enforce policies at tool time. The research community has done the hard part of proving that careful design beats vibes. Now it is on us to build.
Call to action. Take one workflow that touches untrusted content, then ship the split-planner design with capabilities and two high-risk policies. Measure how often you block unsafe actions. Publish your results. If you want a sounding board on your architecture for AI agent security, reach out. The community needs more real stories about prompt injection prevention that actually work, not just clever prompts. You can start today.
Notes: CaMeL is described in “Defeating Prompt Injections by Design.” It formalizes the dual LLM pattern, tracks data dependencies, and enforces capabilities at tool time. The study demonstrates strong security with modest utility costs, and it requires no model modifications.
:1) What Is Prompt Injection And Why Is It So Hard To Stop?
Prompt injection is when crafted text steers an AI system away from its instructions, often to exfiltrate data or misuse tools. It is hard to stop because the model cannot reliably tell trusted instructions from untrusted ones, and attackers can hide instructions inside web pages, PDFs, or emails that the model later reads. Lists of mitigations exist, but detection alone is not enough since even a small miss rate lets attacks through at scale. Treat it like a system design problem, not just prompt wording, and make prompt injection prevention a first class control.
2) What Is The Difference Between Direct And Indirect Prompt Injection?
Direct prompt injection happens when a user types instructions that override the system’s goals, for example “ignore previous instructions.” Indirect prompt injection hides a malicious instruction inside content the AI later processes, for example a web page or document with invisible text. Indirect attacks are more dangerous for agents with tools, because the model treats the embedded text as context and may attempt actions on its behalf. Effective prompt injection prevention requires isolating untrusted content and gating tool calls, not just filtering phrases.
3) What Is The “Dual LLM Pattern” For AI Security?
The dual LLM pattern splits responsibilities. A Privileged LLM plans and calls tools but never sees untrusted data. A Quarantined LLM reads untrusted data and returns structured outputs but cannot call tools. An orchestrator keeps them separate and treats the quarantine output as tainted. This limits how a hidden instruction can influence actions and improves prompt injection prevention for agents that browse, read files, or call APIs. The pattern has become a common reference point for developers hardening real systems.
4) What Is Google’s CaMeL Framework And Why Is It A Breakthrough For AI Agent Security?
CaMeL, short for Capabilities for Machine Learning, wraps the model in a protective layer. It extracts control flow from the trusted user request, parses untrusted data separately, and adds capability tags that carry provenance and permissions with values. Policies check those capabilities at tool time, so unsafe actions are blocked even if the model was influenced by a prompt. In public results, CaMeL demonstrated provable security on a substantial share of AgentDojo tasks, which is notable because most prior defenses were probabilistic filters. Think of it as architecture, not a patch, designed to make prompt injection prevention a property of the system.
5) How Does CaMeL’s “Design Based” Security Compare To Traditional Input Filtering?
Input filtering and detection try to spot bad strings. That helps, but attackers adapt and even a small false negative rate is enough to cause incidents. CaMeL changes the execution model. It separates planning from untrusted parsing, tracks data flow, and enforces capability policies before any tool runs. The result is stronger, more predictable control at the point of impact. In short, filters reduce some noise, architecture removes classes of failure. Use both, but anchor your prompt injection prevention on design, not hope.