

Qwen3.6 Plus arrived with the kind of launch that makes the rest of the industry look up from its dashboards and mutter, “well, that complicates things.” On paper, the pitch is outrageous: a 1M context window, a serious jump in agentic coding, stronger multimodal reasoning, support for both OpenAI-style and Anthropic-style APIs, and a generous free path through Qwen Code. In practice, the more interesting story is this: Qwen3.6 Plus does not need to beat every frontier model on every line item to matter. It just needs to be good enough, cheap enough, and easy enough to wire into real workflows. That threshold is lower than people think, and much more disruptive.
What makes Qwen3.6 Plus worth paying attention to is not one benchmark screenshot or one viral demo. It is the shape of the whole package. Qwen3.6 Plus looks like a model built by people who listened to developers complain, then treated those complaints as product requirements instead of background noise. Better terminal performance. Better long-horizon code work. Better document and image reasoning. Better tool use. And a clearer path into everyday developer environments, from Qwen Code to OpenClaw to Claude Code. That is how platform shifts actually happen. Not with one headline. With a pile of annoyingly practical decisions.
Table of Contents
1. The Benchmark Picture In One View
Before the hot takes, here is the full benchmark table from the source material.
| Benchmark | Category | Qwen3.6-Plus | Qwen3.5-397B-A17B | Kimi K2.5 | GLM5 | Claude 4.5 Opus | Gemini3-Pro |
|---|---|---|---|---|---|---|---|
| Terminal-Bench 2.0 | Agentic Terminal Coding | 61.6 | 52.5 | 50.8 | 56.2 | 59.3 | – |
| SWE-bench Pro | Agentic Coding | 56.6 | 50.9 | 53.8 | 55.1 | 57.1 | – |
| SWE-bench Verified | Agentic Coding | 78.8 | 76.2 | 76.8 | 77.8 | 80.9 | – |
| SWE-bench Multilingual | Multilingual Agentic Coding | 73.8 | 69.3 | 73.0 | 73.3 | 77.5 | – |
| Claw-Eval (pass^3) | Real-World Agent | 58.7 | 48.1 | 52.9 | 57.7 | 59.6 | – |
| QwenClawBench | Real-World Agent | 57.2 | 51.8 | 54.3 | 54.1 | 52.3 | – |
| QwenWebBench (Elo) | Artifacts | 1502 | 1162 | 1160 | 1315 | 1518 | – |
| NL2Repo | Long-Horizon Coding | 37.9 | 32.2 | 32.0 | 35.9 | 43.2 | – |
| MMMU | Multimodal Reasoning | 86.0 | 85.0 | 84.3 | – | 80.7 | 87.2 |
| RealWorldQA | Image Reasoning | 85.4 | 83.9 | 81.0 | – | 77.0 | 83.3 |
| OmniDocBench v1.5 | Doc Recognition & Understanding | 91.2 | 90.8 | 88.8 | – | 87.7 | 88.5 |
| Video-MME (w/ sub) | Video Reasoning | 87.8 | 87.5 | 87.4 | – | 77.6 | 88.4 |
A quick read of that table tells you almost everything. Qwen3.6 Plus is not the uncontested king of every coding metric. Claude 4.5 Opus still edges it on several heavyweight software benchmarks. Gemini3-Pro still leads on some multimodal tests. But Qwen3.6 Plus wins Terminal-Bench 2.0, wins RealWorldQA, wins OmniDocBench, stays close on SWE-bench Verified, and posts a QwenWebBench Elo almost tied with Claude. That is not a niche result. That is an all-rounder with sharp elbows.
2. Why Qwen3.6 Plus Feels Different
A lot of model launches are really pricing events wearing benchmark makeup. This one is different. Qwen3.6 Plus feels like a systems release. The story is not just “our numbers went up.” The story is that the model got better at the kind of messy, chained, tool-heavy work developers actually do, where memory, reasoning, execution, and interface handling all need to cooperate instead of taking turns looking smart. That framing runs through the source material from coding agents to visual reasoning to GUI-style action loops.
That matters because the market has moved past single-turn cleverness. Nobody serious is choosing an assistant because it can ace a toy riddle. They want a model that can inspect a repo, survive the terminal, read a screenshot, understand a document, keep the thread of a task alive, and not fall apart three turns later. Qwen3.6 Plus is clearly aiming at that exact target.
3. Qwen Coding Gets Serious
The most convincing part of the launch is qwen coding. Not the slogan, the texture of the results. Qwen3.6 Plus posts 61.6 on Terminal-Bench 2.0, which puts it ahead of Claude 4.5 Opus at 59.3. It stays highly competitive on SWE-bench Pro and SWE-bench Verified, and it puts real distance between itself and the previous Qwen generation. That gap is the story. When a model family improves this much in the boring, brutal benchmarks, you start expecting the day-to-day experience to improve too.
There is also a subtle product clue here. The new preserve_thinking option in the qwen api is not flashy, but it tells you what kind of workloads Alibaba has in mind. This is for multistep tasks, agent loops, repo-scale reasoning, and workflows where losing intermediate context means paying the “figure it out again” tax. Anyone who has watched an agent re-derive the same plan for the fourth time knows how expensive that tax gets.
3.1 Preserve Thinking Changes The Feel Of Long Tasks
This feature is easy to underestimate. A lot of developer pain is not raw intelligence. It is continuity. When Qwen3.6 Plus keeps prior reasoning available across turns, the model has a better shot at acting like it remembers what it is doing. That sounds obvious. In practice, it is rare enough to be useful. The best agent workflows do not feel brilliant. They feel steady.
4. Multimodality Stops Being A Side Quest
One of the more interesting things about Qwen3.6 Plus is that its multimodal story is not tacked on as decorative frosting. The model does well where useful multimodality starts paying rent: document understanding, image reasoning, visual coding, UI analysis, grounded perception, and video understanding. RealWorldQA at 85.4 and OmniDocBench at 91.2 are especially telling. Those are not novelty wins. Those are “can I actually trust this on mixed inputs?” wins.
That creates a practical advantage. A coding assistant that can also inspect a UI mockup, read charts, parse screenshots, reason over documents, and generate front-end artifacts is much closer to how real teams work. Engineers do not live inside plain text. They live inside a swamp of tickets, screenshots, Figma exports, error logs, dashboards, and half-finished docs. Qwen 3.6 Plus looks designed for that swamp.
5. Qwen Pricing Is The Real Plot Twist
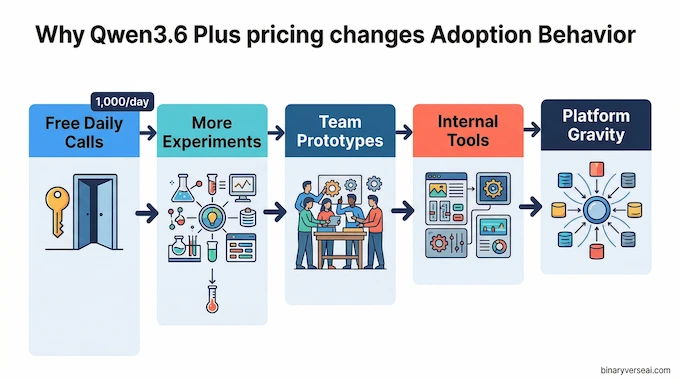
Let’s talk about qwen pricing, because this is where the launch gets strategically loud. If you have been asking, “is qwen ai free,” the honest answer is, sort of, in the way cloud companies love to be generous when they are trying to become your default. The source material says Qwen Code users get 1,000 free calls per day, and the hosted Plus model is available through Alibaba Cloud Model Studio. That is not charity. That is customer acquisition with a compiler attached.
This is why Qwen3.6 Plus matters even if you still prefer Claude or GPT for certain edge cases. Free or cheap enough changes behavior. Developers experiment more. Teams prototype sooner. Hobby projects become internal tools. Internal tools become dependencies. Dependencies become platform gravity. That is how qwen ai models stop being “interesting alternatives” and start becoming infrastructure.
6. The Benchmark Debate Is Real, And Also A Bit Missing The Point
Yes, the skeptics have a point. When a vendor compares itself to some frontier models and not others, that is a choice. The outline you provided even bakes this into the article direction, asking whether Alibaba dodged the newest headline opponents. Fair criticism. But the deeper question is not whether Qwen3.6 Plus won the PR bracket. It is whether it crossed the threshold where most people can swap it into their actual work and keep moving.
On that question, the answer looks a lot more interesting. Qwen3.6 Plus is already close enough in coding to be credible, already strong enough in multimodality to be useful, and already accessible enough through tooling to get adopted. Frontier prestige matters. Workflow gravity matters more.
7. The Open Weights Question Will Not Go Away
If you spend any time around local inference people, this is the first thing they ask. Not “how smart is it?” but “can I run it myself?” On that front, the answer is still incomplete. Qwen3.6-Plus, the flagship being promoted here, is API-first. As noted by Chujie Zheng on X, smaller-scale variants of the Qwen3.6 series are expected to be open-sourced in the coming days. That is promising, but it is not the same as having the weights in hand today.
This matters because local users are not just chasing cost savings. They care about control, latency tuning, privacy, reproducibility, and the ability to bend a model into specialized workflows. So yes, Qwen3.6 Plus is the shiny thing today. The next phase of the conversation will be about which qwen ai models become genuinely useful outside the hosted stack.
8. The Qwen API Story Is Better Than Most Launches
A model can be excellent and still fail if integration feels like tax paperwork. Here, Qwen3.6 Plus is doing something smart. The qwen api is available via Alibaba Cloud Model Studio, supports OpenAI-compatible chat completions and responses APIs, and also supports an Anthropic-compatible interface. That last part matters more than it looks. Teams with existing Claude Code habits do not have to emotionally process a whole new ecosystem before trying it.
Here is the practical view:
| Workflow | Best Entry Point | Why It Matters |
|---|---|---|
| Fast individual testing | Qwen Code | Easiest path, includes the 1,000 free calls per day flow |
| Terminal-heavy agent work | OpenClaw + Model Studio | Best fit for repo inspection, terminal loops, and tool use |
| Claude-style developer workflows | Claude Code via Anthropic-compatible endpoint | Lower switching cost for teams already living in that interface |
| Front-end and visual artifact generation | OpenClaw or Qwen Code | Pairs strong coding with visual reasoning and web artifact work |
That table is the hidden strength of Qwen3.6 Plus. It is not asking developers to move house. It is showing up at the tools they already use and saying, “you can keep your habits, just swap the engine.”
9. Should You Switch To Qwen3.6 Plus
For a lot of people, yes, at least for part of the stack.
If your work is coding-heavy, budget-sensitive, and increasingly multimodal, Qwen3.6 Plus is hard to ignore. If you want the absolute top score on every premium frontier benchmark, you will still compare it against the usual suspects on LLM pricing and performance. But if you want something that is broadly strong, often free to try, operationally flexible, and clearly pointed at real agent workflows, Qwen3.6 Plus already clears the bar.
My take is simple. Do not evaluate Qwen3.6 Plus with a toy prompt and a smug expression. Give it the work you actually hate. A messy repo. A broken build. A screenshot-plus-docs-plus-code task. A front-end artifact with annoying constraints. A planning loop that needs memory. That is where the model is trying to win, and that is where its design makes sense.
Qwen3.6 Plus does not make the frontier race over. It makes the race less comfortable. That is more important. It pressures pricing. It pressures distribution. It pressures assumptions about what a “good enough” model can do when the tooling is right. And it reminds the rest of the field that developers are not only buying intelligence. They are buying friction reduction.
That is why this release matters. Not because it is perfect. Because it is close enough, cheap enough, and integrated enough to change behavior.
Try Qwen3.6 Plus on something real this week. Not a benchmark screenshot, not a one-line prompt, a real task with real mess. That is where the truth lives, and where the winners usually reveal themselves.
Is Qwen3.6 Plus completely free to use?
Answer: During preview, Qwen3.6 Plus is effectively free to try, but not in an unlimited forever-free sense. Qwen says Qwen Code users get 1,000 free calls per day, OpenRouter lists a free variant at $0/M input and output tokens, and OpenCode says the free offer is available for a limited time. So the accurate answer is: free for preview access, yes, permanently free with no limits, not confirmed.
Why didn’t Alibaba benchmark Qwen3.6 Plus against GPT-5.4?
Answer: Alibaba did not explain the omission. The official Qwen launch materials highlighted comparisons with Claude 4.5 Opus and Gemini3-Pro, while OpenAI had already launched GPT-5.4 on March 5, 2026 with stronger published coding results such as 75.1 on Terminal-Bench 2.0 and 57.7 on SWE-bench Pro. So readers are right to notice the gap, but the reason remains inference, not a stated Alibaba explanation.
Is Qwen3.6 Plus open source?
Answer: No, not the flagship model. The current Qwen3.6 Plus release is presented as a hosted/API model available through Qwen and Alibaba Cloud routes, plus third-party hosted providers like OpenRouter and Puter. Qwen does publish open-weight models in the broader Qwen family, but Qwen3.6 Plus itself is not currently a public downloadable weight release.
Can I run a 1M token context window locally on my GPU?
Answer: Usually not on a single consumer GPU today, at least not comfortably. Very long context windows blow up KV cache memory, and long-context serving docs note that the cache can become a major RAM or VRAM bottleneck. Compression research like Google’s TurboQuant may help reduce that memory burden, but that is not the same as saying a full 1M-context flagship model is practical on one RTX 4090 right now.
How good is Qwen3.6 Plus for agentic coding?
Answer: Very good, and that is the strongest part of the launch. In the benchmark table from the source material, Qwen3.6-Plus scores 61.6 on Terminal-Bench 2.0, 56.6 on SWE-bench Pro, and 78.8 on SWE-bench Verified. Official Qwen and Alibaba Cloud materials also position it for real coding workflows through Qwen Code, Claude Code-compatible endpoints, and tools like OpenClaw.