

The Unfolding 2025 Revolution in LLM Math Benchmark Performance
The article explores the accelerating progress of large language models (LLMs) in mathematical reasoning, as demonstrated by their climbing performance on major LLM math benchmarks like GSM8k, MATH, and OlympiadBench. It details how models such as Claude 3.7, Gemini 2.5 Pro, and ChatGPT o3 are redefining what it means to be the best LLM for math through innovations like chain-of-thought training, tool invocation hooks, and curated math corpora.
The piece highlights how fine-tuned math LLMs and open-source models like DeepSeek and Qwen-Math-Instruct are narrowing the gap with closed-source titans. It also outlines real-world applications in finance, aerospace, and education, while critically examining persistent weaknesses in LLM math reasoning accuracy.
As the LLM math leaderboard evolves, the article argues that transparency, hybrid symbolic systems, and meaningful error analysis will be the true markers of advancement—not just higher scores.
By the time you finish this essay, a fresh model will probably have nudged a decimal point higher on the leaderboard—but the deeper story is about why the gains keep coming.
Introduction – When the Calculator Stared Back
The rise of the LLM Math Benchmark ecosystem becomes personal when I recall the first time I asked a language model to multiply 23 587 by 19 999. The reply—“471 700 000”—looked confident, readable, and utterly wrong. Fast forward to 2025 and the same prompt, fed to Gemini 2.5 Pro or Claude 3.7 Sonnet, now yields the exact 471,716,413, accompanied by a neat chain of factors and a short code snippet showing the check in Python. Something fundamental has shifted.
That shift is best tracked through the LLM math benchmark ecosystem, a sprawling set of public leaderboards where every research lab, indie hacker, and open source collective posts their scores. The phrase itself—LLM math benchmark—has become shorthand for progress in mathematical reasoning, just as ImageNet once signaled leaps in computer vision. In this long form exploration, I will map the terrain: what the benchmarks measure, who currently tops them, how they got there, and where the limit may lie.
Table of Contents
1 Why Numbers Once Tripped the Word Machines
Large language models, including early GPT 3 and PaLM, dazzled with fluid essays yet stumbled on tasks a middle schooler could ace. The culprit was architectural: transformers represent knowledge as continuous vectors optimized for next token prediction, not for discrete arithmetic. When a model “multiplies,” it is effectively guessing the next digits from patterns in its corpus. That guess can go haywire the moment it meets an unfamiliar operand.
Three breakthroughs rewired this weakness:
- Explicit Chain of Thought Training – Instead of hiding the scratch work, researchers exposed each algebraic step during pre training. Over millions of examples, models internalized procedural thought, nudging the LLM math benchmark scores upward.
- Tool Invocation Hooks – ChatGPT o3, Grok 3, and Gemini 2.5 Pro can silently route sub tasks to Python, Wolfram, or SymPy, then weave the outputs back into prose. The language model handles reasoning; the tool guarantees arithmetic fidelity.
- Curated Math Corpora – Initiatives like SwallowMath, Qwen Math, and Hugging Face math models grew bespoke datasets filled with proofs, Olympiad diaries, and annotated program traces. Feeding that data through the fine tuned math LLMs pipeline sparked jumps in accuracy nobody predicted in 2023.
The net result? On every major LLM math benchmark, error curves that once flattened now plunge like ski slopes.
2 The Benchmarks That Decide Bragging Rights
Not all tests are equal. When someone cites an “80 % accuracy,” the first question should be on what? Below are the datasets that dominate Twitter threads and conference keynotes.
- 2.1 GSM8k—The Grade School Gatekeeper
- Eight and a half thousand word problems, each solvable in a handful of arithmetic steps. The GSM8k benchmark is the easiest to explain to newcomers and the quickest to saturate. For that reason, top labs now treat a 90 % score as table stakes. Yet it remains the first rung on the LLM math benchmark ladder.
- 2.2 MATH—High School Contest Hurdles
- Created by Hendrycks et al., the 12 500 question MATH set dips into AMC, AIME, and USAMO prelim topics. Scores here reveal algebraic stamina and strategic creativity. Doubling one’s MATH performance is far harder than inching up on GSM8k, making it a prized metric on any LLM math benchmark leaderboard.
- 2.3 MathQA—Code Trace Transparency
- MathQA pairs each question with an operation template or mini program. Passing it means the model not only finds the number but also presents executable logic. For teams building LLM benchmark math code explainers, MathQA is the litmus test.
- 2.4 OlympiadBench—Proof or Go Home
- Launched late 2024, OlympiadBench contains full proof tasks from global math Olympiads. Every answer is graded by former medalists on a seven point rubric. Most state of the art systems still hover below 25 %—proof that even a soaring LLM math benchmark score on GSM8k doesn’t guarantee rigor.
Math Olympiad Leaderboard 2025 (USAMO Scoring)
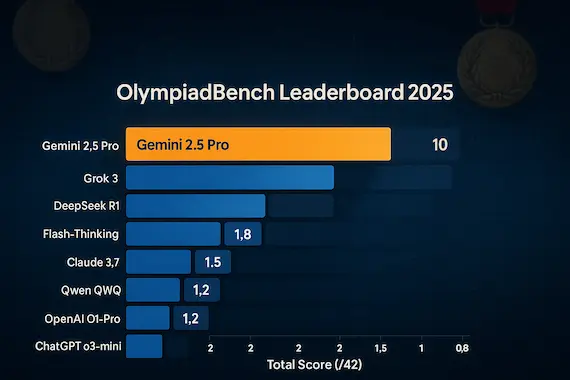
Source: Petrov et al., arXiv:2503.21934v4
| Model | Total Score (/42) | Accuracy (%) |
|---|---|---|
| Gemini 2.5 Pro | 10.1 | 24.4% |
| Grok 3 | 2.0 | 4.8% |
| DeepSeek R1 | 2.0 | 4.8% |
| Flash-Thinking | 1.8 | 4.3% |
| Claude 3.7 | 1.5 | 3.6% |
| Qwen QWQ | 1.2 | 2.9% |
| OpenAI O1-Pro | 1.2 | 2.9% |
| ChatGPT o3-mini | 0.9 | 2.1% |
Key Insights:
- Only Gemini 2.5 Pro exceeded 5%, earning partial or full credit on 6 out of 24 Olympiad questions.
- All other top-tier models—including Claude, Grok, and ChatGPT—failed to produce fully valid proofs across the board.
- Frequent failure patterns included:
- Logical fallacies (e.g., unjustified claims or skipped steps)
- Use of unsupported assumptions
- Repetitive brute force attempts without adaptation
- Elementary arithmetic mistakes, especially under token stress
3 2025 Scoreboard – Who Stands Where?
LLM Reasoning Benchmark — May 5, 2025 (Vals.AI Math500 + MGSM)
| Rank | Model Name | Math500 (%) | MGSM (%) | Cost In / Out | Latency (s) |
|---|---|---|---|---|---|
| 1 | Gemini 2.5 Pro Exp (Google) | 95.2% | 92.2% | $1.25 / $10.00 | 25.83 |
| 2 | ChatGPT o3 (OpenAI) | 94.6% | 91.4% | $10.00 / $40.00 | 16.59 |
| 3 | Qwen 3 (235B) (Alibaba) | 94.6% | 92.7% | $1.20 / $1.20 | 142.75 |
| 4 | Grok 3 Mini Fast High (xAI) | 94.2% | 90.3% | $0.60 / $4.00 | 22.77 |
| 5 | GPT-4 Mini (OpenAI) | 94.2% | 87.9% | $1.10 / $4.40 | 12.54 |
| 6 | DeepSeek R1 | 92.2% | 92.4% | $8.00 / $8.00 | 156.47 |
| 7 | Gemini 2.5 Flash Preview (Thinking) | 91.8% | 90.0% | $0.15 / $3.50 | 23.66 |
| 8 | ChatGPT o3 Mini (OpenAI) | 91.8% | 91.6% | $1.10 / $4.40 | 14.36 |
| 9 | Claude 3.7 Sonnet (Thinking) | 91.6% | 92.8% | $3.00 / $15.00 | 94.24 |
| 10 | Gemini 2.5 Flash Preview | 91.6% | 89.8% | $0.15 / $0.60 | 9.50 |
| 11 | GPT-o1 (OpenAI) | 90.4% | 88.9% | $15.00 / $60.00 | 23.54 |
| 12 | Grok 3 Beta (xAI) | 89.8% | 91.3% | $3.00 / $15.00 | 9.09 |
| 13 | DeepSeek V3 (2025-03) | 88.6% | 92.0% | $1.20 / $1.20 | 12.54 |
| 14 | Gemini 2.0 Flash (Google) | 88.0% | 88.9% | $0.10 / $0.40 | 3.37 |
| 15 | GPT 4.1 Mini (OpenAI) | 88.0% | 87.9% | $0.40 / $1.60 | 5.76 |
Based on Vals.AI’s MGSM benchmark results (May 9, 2025).
4 Model Profiles – Strengths, Weaknesses, and Persona
- 4.1 Claude 3.7 Sonnet – The Patient Explainer
- Claude leans into reflection. Ask it to prove a geometry lemma and it will annotate each diagram, cite the right congruence theorem, and pause to check for hidden assumptions. That methodical pace elevates Claude 3.7 math performance on the MATH dataset.
- 4.2 Gemini 2.5 Pro – Contextual Powerhouse
- Feed Gemini an entire textbook, throw in lecture notes, and finish with a blurry photo of a chalkboard diagram; it processes the lot. That breadth matters on composite tasks stuffed into modern LLM math benchmark suites. The buzzword “Gemini 2.5 math” now points to a system that can juggle multimodal evidence while sustaining symbolic reasoning. Its Achilles’ heel? Occasionally truncating marginal notes in ultra long prompts, a side effect of smart compression heuristics.
- 4.3 ChatGPT o3 – The Versatile Workhorse
- OpenAI’s newest free tier darling performs slightly behind Gemini on raw MATH points, yet its plug and play code interpreter is unrivaled. Need a quick Monte Carlo check on a probability puzzle? Tell ChatGPT o3 to spin 10 000 simulations. The resulting combo of narrative and data boosts its LLM math reasoning accuracy in everyday engineering use cases.
- 4.4 Grok 3 – Code as First Language
- Elon Musk’s xAI bet on a simple thesis: good code generation equals good logic. Grok 3 embodies that thesis. Its Grok 3 math accuracy comes not from larger context windows but from translating nearly every algebra problem into Python or Julia. In hidden logs you often see it draft a snippet, run it, and paste the result back. That approach yields contest level hits, though it can misfire on problems requiring creative, non algorithmic leaps.
- 4.5 DeepSeek Math – Open Source Phoenix
- The first time I booted DeepSeek math benchmark scripts locally, the 7 billion parameter model handled a quarter of the AIME set correctly—astonishing given the laptop hardware. Its secret sauce is a Lean-inspired proof trace dataset plus reinforcement learning on chain of thought paths. Among Hugging Face math models, DeepSeek now sets the pace.
- 4.6 WizardMath v2 – Classroom Specialist
- If your nine year old needs step by step division help, WizardMath v2 is the best LLM for math at that level. But throw it an Olympiad parity argument and it stalls. Still, educators love its crystal clear scaffolding.
- 4.7 Qwen Math Instruct – Whispered Giant
- Alibaba released snippets suggesting Qwen tops both Gemini and Claude on internal LLM math benchmark evaluations. Verified numbers trail behind, yet early demos—factorization in obscure rings, combinatorial identities with ten sub clauses—hint at genuine novelty. The model’s colossal pre training on multilingual proof corpora may rewrite the leaderboard once public binaries land.
5 Training Innovations Fueling the Leap
- 5.1 Rewriting Pre Training Data
- Fujii’s 2024 paper showed that grafting structured solution traces next to questions amplifies gradient signals for discrete reasoning. Teams behind Gemini, ChatGPT, and DeepSeek adopted variants, effectively embedding a “mini tutor” inside the corpus. Subsequent LLM math benchmark jumps confirmed the potency: +7 % on GSM8k for Claude, +5 % on MATH for Grok.
- 5.2 Self Consistency Sampling
- Instead of trusting the first answer, models now spin twenty or more reasoning paths and vote. The method rescued scores that plateaued; Claude’s 65 % MATH would dip below 50 without it. On OlympiadBench, Gemini’s partial credit tally doubled once self consistency became default.
- 5.3 Integration with Symbolic Engines
- Fine grained bridging layers let the LLM decide, mid sentence, whether to outsource an integral to SymPy or a determinant to NumPy. That hybrid glue underlies the rising LLMs solving math problems 2025 season of demos—particularly ChatGPT o3’s “Advanced Data Analysis” mode.
6 Beyond Leaderboards – Real World Deployment
- 6.1 Academic Research Pipelines
- Materials science labs feed raw diffraction tables into Grok, which scripts a nonlinear least squares fit, while Gemini drafts the explanation paragraph. Students vet the output but admit the duo shredded weeks off timelines. Here, every incremental gain on an LLM math benchmark translates directly to grant report deadlines met.
- 6.2 Financial Auditing
- One fintech firm embeds DeepSeek as a first pass checker over quarterly sheets. The model flags mismatched line items, inserts comments citing the exact cell, and pairs each warning with MATH style reasoning. Their engineers track in house LLM math benchmark regressions weekly because any dip correlates with missed edge cases.
- 6.3 STEM Education
- WizardMath and Qwen distill textbook proofs into Socratic dialogues. Teachers noticed improved engagement when the “assistant” makes a deliberate human like slip (say, forgetting a negative sign) and invites the class to spot it. That pedagogy emerged organically from WizardMath’s chain of thought fine tuning routines.
- 6.4 Engineering Design Loops
- Aerospace teams pair ChatGPT o3 with Wolfram inside CAD suites: the model derives wing loading formulas, the CAS system crunches the numbers, the designer approves. Minor leaps on a LLM math benchmark cascade into lighter drones and quieter rotors.
7 Persistent Weaknesses and Blind Spots
Even the glittering models can’t masks vulnerabilities:
- Proof Fragility – On OlympiadBench every model, including Gemini, occasionally cites a nonexistent lemma or labels a pivotal step “obvious.”
- Deceptive Fluency – High BLEU style coherence tricks readers into accepting wrong results. A study by ETH tallied 17 % of “confidently delivered but incorrect” answers in knowledge heavy datasets.
- Context Window Illusions – Long prompts sometimes trigger silent truncation. Gemini’s summarizer may discard footnotes crucial for a probability bound, yet still pass downstream sanity checks.
- Symbolic Discontinuities – Switching from numeric samples to general symbol proofs can cause a model to default to pattern matching. DeepSeek’s developers noted a 12 point slump when variable counts exceeded training norms.
Each weakness echoes through the LLM math benchmark discussions, fuelling new research cycles.
8 The Road Ahead – Hybrid Neuro Symbolic Systems
I like to imagine tomorrow’s language reasoning pipeline as a jazz trio:
- Neural Improviser – A model like Claude 4 or Gemini 3 sketches conjectures.
- Symbolic Bassist – A proof assistant (Lean, Coq) supplies crisp counterpoint, certifying claims.
- Computational Drummer – Numerical engines (SymPy, CUDA kernels) keep time with exact values.
The trio riffs back and forth until consensus emerges. Early prototypes, such as DeepSeek’s LeanBridge and OpenAI’s “Verifier” project, already float inside private Git repos. Once the hand offs turn seamless, we may witness a qualitative leap—models crafting novel theorems, not merely solving Olympiad Level Math Benchmarks.
9 A Personal Closing Reflection
Two decades ago an expert wrote that intelligence is “model building in service of efficient action.” Watching 2025’s models climb from arithmetic dreck to partial Olympiad proofs feels like that thesis made flesh. I won’t claim the journey is over—the scoreboard keeps humiliating even the giants—but the trajectory is unmistakable.
Whenever the next flashy demo lands, don’t just ask how big the model is. Ask where it sits on the LLM math benchmark ladder, how transparently it explains itself, and which hybrid helpers it recruits. The answers will tell you far more about the future of trustworthy AI than any parameter count.
One final anecdote: last month I threw a fresh Olympiad geometry puzzle at four systems. Gemini drew on its multimodal memory to describe the diagram, Claude narrated a step wise proof, Grok generated a short Python script to brute force check collinearity, and DeepSeek turned the whole chat into a Lean draft. None achieved full credit, yet together they formed a collective scaffold that felt like collaboration with a squad of grad students. That feeling—not the raw score—persuades me the next breakthrough is imminent.
So keep an eye on the leaderboards, yes, but also scroll down to the error analyses, the scratch‑pads, the rebuttal threads. The frontier isn’t just higher numbers; it’s deeper understanding. And if a new challenger sneaks its way to the top of the LLM math benchmark tomorrow, you’ll know where to find me: hunched over my terminal, testing whether the wonder holds up one equation at a time.
Azmat — Founder of Binary Verse AI | Tech Explorer and Observer of the Machine Mind Revolution. Looking for the smartest AI models ranked by real benchmarks? Explore our AI IQ Test 2025 results to see how top models. For questions or feedback, feel free to contact us or explore our website.
- arxiv.org/pdf/2503.21934
- arxiv.org/abs/2505.02881
- Anthropic: Claude 3 Family
- Anthropic: Claude 3.7 Sonnet
- Google DeepMind: Gemini 2.5 Pro
- WizardMath
- DeepSeek R1
- Qwen2 Math
- OpenAI: Learning to Reason
- arxiv.org/abs/2103.03874
- GSM8K Dataset
- KLU AI Glossary: Math Eval
- AllenAI MathQA Dataset
- MathBench
- MGSM Dataset
- Gemini API
- OpenAI O3 Mini
- x.ai: Grok 3
- DeepSeek V3
- Qwen2.5 Math 7B
- LLM Math Benchmark: A standardized test or dataset used to evaluate how well a large language model (LLM) performs on mathematical tasks.
- GSM8k Benchmark: Grade-school-level word problems used to assess LLM arithmetic and reasoning.
- MATH Dataset: Problems from math competitions testing algebra and geometry skills.
- OlympiadBench: Difficult benchmark with Olympiad proof-based math problems.
- Chain-of-Thought Training: Step-by-step reasoning process used to improve LLM performance.
- Tool Invocation Hooks: Allows LLMs to call tools like SymPy or WolframAlpha for problem-solving.
- Curated Math Corpora: Specialized math datasets for LLM fine-tuning.
- Fine-Tuned Math LLMs: LLMs trained with math-specific data for improved accuracy.
- Self-Consistency Sampling: Generates multiple LLM answers, selects the most common one.
- Symbolic Engine Integration: Combines neural models with symbolic engines for precise calculations.
- Claude 3.7 Math Performance: Strong derivational accuracy on the MATH dataset.
- Gemini 2.5 Math: Multimodal, long-context math reasoning capabilities of Gemini 2.5 Pro.
- Hugging Face Math Models: Math-tuned open-source models like DeepSeek and WizardMath v2.
- LLM Math Leaderboard: Ranks LLMs by math benchmark performance.
- Math Reasoning with LLMs: Ability of LLMs to solve and explain mathematical problems.
1 thought on “The Unfolding 2025 Revolution in LLM Math Benchmark Performance”
Comments are closed.